之前写的一篇SSD论文学习笔记因为没保存丢掉了,然后不想重新写,直接进行下一步吧。SSD延续了yolo系列的思路,引入了Faster-RCNN anchor的概念。不同特征层采样,多anchor. SSD源码阅读 https://github.com/balancap/SSD-Tensorflow
ssd_vgg_300.py为主要程序。其中ssd_net函数为定义网络结构。先简单解释下SSD是如何提取feature map的。如下图,利用VGG-16,采用多尺度提取,提取不同卷积层的特征网络。一般为6个,层数大小分别为conv4 ==> 64 x 64,conv7 ==> 32 x 32,conv8 ==> 16 x 16,conv9 ==> 8 x 8,conv10 ==> 4 x 4,conv11 ==> 2 x 2,conv12 ==> 1 x 1。
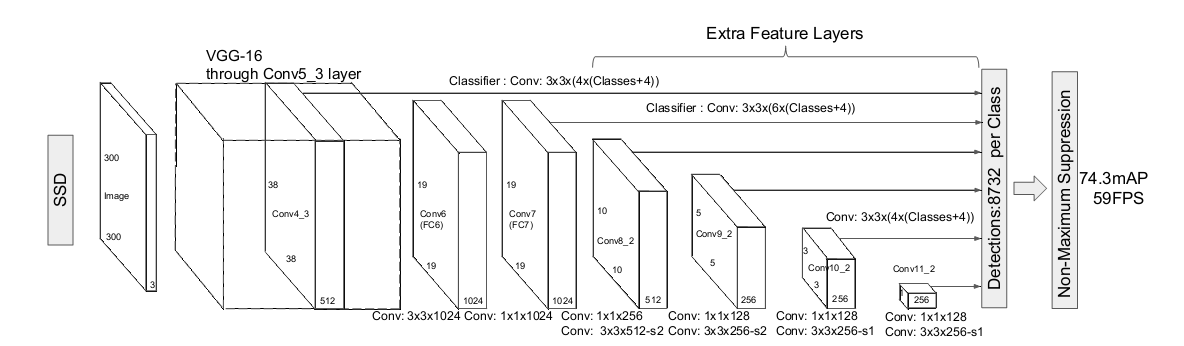
1 ###定义网络结构,将不同卷积层存储在end_points中。此部分用了tensorflow.slim模块,类似于keras
end_points = {} 2 with tf.variable_scope(scope, 'ssd_300_vgg', [inputs], reuse=reuse): 3 # Original VGG-16 blocks. 4 net = slim.repeat(inputs, 2, slim.conv2d, 64, [3, 3], scope='conv1') 5 end_points['block1'] = net 6 net = slim.max_pool2d(net, [2, 2], scope='pool1') 7 # Block 2. 8 net = slim.repeat(net, 2, slim.conv2d, 128, [3, 3], scope='conv2') 9 end_points['block2'] = net 10 net = slim.max_pool2d(net, [2, 2], scope='pool2') 11 # Block 3. 12 net = slim.repeat(net, 3, slim.conv2d, 256, [3, 3], scope='conv3') 13 end_points['block3'] = net 14 net = slim.max_pool2d(net, [2, 2], scope='pool3') 15 # Block 4. 16 net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv4') 17 end_points['block4'] = net 18 net = slim.max_pool2d(net, [2, 2], scope='pool4') 19 # Block 5. 20 net = slim.repeat(net, 3, slim.conv2d, 512, [3, 3], scope='conv5') 21 end_points['block5'] = net 22 net = slim.max_pool2d(net, [3, 3], stride=1, scope='pool5') 23 24 # Additional SSD blocks. 25 # Block 6: let's dilate the hell out of it! 26 net = slim.conv2d(net, 1024, [3, 3], rate=6, scope='conv6') 27 end_points['block6'] = net 28 net = tf.layers.dropout(net, rate=dropout_keep_prob, training=is_training) 29 # Block 7: 1x1 conv. Because the fuck. 30 net = slim.conv2d(net, 1024, [1, 1], scope='conv7') 31 end_points['block7'] = net 32 net = tf.layers.dropout(net, rate=dropout_keep_prob, training=is_training) 33 34 # Block 8/9/10/11: 1x1 and 3x3 convolutions stride 2 (except lasts). 35 end_point = 'block8' 36 with tf.variable_scope(end_point): 37 net = slim.conv2d(net, 256, [1, 1], scope='conv1x1') 38 net = custom_layers.pad2d(net, pad=(1, 1)) 39 net = slim.conv2d(net, 512, [3, 3], stride=2, scope='conv3x3', padding='VALID') 40 end_points[end_point] = net 41 end_point = 'block9' 42 with tf.variable_scope(end_point): 43 net = slim.conv2d(net, 128, [1, 1], scope='conv1x1') 44 net = custom_layers.pad2d(net, pad=(1, 1)) 45 net = slim.conv2d(net, 256, [3, 3], stride=2, scope='conv3x3', padding='VALID') 46 end_points[end_point] = net 47 end_point = 'block10' 48 with tf.variable_scope(end_point): 49 net = slim.conv2d(net, 128, [1, 1], scope='conv1x1') 50 net = slim.conv2d(net, 256, [3, 3], scope='conv3x3', padding='VALID') 51 end_points[end_point] = net 52 end_point = 'block11' 53 with tf.variable_scope(end_point): 54 net = slim.conv2d(net, 128, [1, 1], scope='conv1x1') 55 net = slim.conv2d(net, 256, [3, 3], scope='conv3x3', padding='VALID') 56 end_points[end_point] = net
接下来ssd_multibox_layer 函数为按每一层feature map('block4', 'block7', 'block8', 'block9', 'block10', 'block11')生成不同的anchor进行预测。源码中生成anchor方式与前面所述不太一样。论文中方式提取网络后在不同feature map设置不同大小的anchor,基准的size大小计算方式为![]() ,k为不同的特征层取值,比conv4是k为1.Smax=0.9,Smin为0.2. 每个feature map,以基准SIZE生成4-6个不同比例的anchor,比例分别为{1,2,3,1/2,1/3},其中比例为1时,size为Sk*Sk+1。以输入为300X300尺寸,conv4层的feature map为例。S1=0.2*300=60,选取的比例分别为{1,2,1/2,1‘’}。不同anchor的w分别为{60,60*1.42,60*0.7,112.5}. 但实际函数中不是按这种方法来计算的。接下来分析源码中的计算方式。源码中直接给出了每一层的大小及比例。此函数作用为提取feature map生成预测的位置及类别。此项涉及到提取的feature map数据流通方式。此函数中有两条路线,经过一次batchnorm和卷积,生成类别信息(21*num_anchor*w*h)及位置信息的预测。实际应有三条线?分别生成代码如下:
,k为不同的特征层取值,比conv4是k为1.Smax=0.9,Smin为0.2. 每个feature map,以基准SIZE生成4-6个不同比例的anchor,比例分别为{1,2,3,1/2,1/3},其中比例为1时,size为Sk*Sk+1。以输入为300X300尺寸,conv4层的feature map为例。S1=0.2*300=60,选取的比例分别为{1,2,1/2,1‘’}。不同anchor的w分别为{60,60*1.42,60*0.7,112.5}. 但实际函数中不是按这种方法来计算的。接下来分析源码中的计算方式。源码中直接给出了每一层的大小及比例。此函数作用为提取feature map生成预测的位置及类别。此项涉及到提取的feature map数据流通方式。此函数中有两条路线,经过一次batchnorm和卷积,生成类别信息(21*num_anchor*w*h)及位置信息的预测。实际应有三条线?分别生成代码如下:
1 def ssd_multibox_layer(inputs, 2 num_classes, 3 sizes, 4 ratios=[1], 5 normalization=-1, 6 bn_normalization=False): 7 """Construct a multibox layer, return a class and localization predictions. 8 """ 9 net = inputs 10 if normalization > 0: 11 net = custom_layers.l2_normalization(net, scaling=True) 12 # Number of anchors. 13 num_anchors = len(sizes) + len(ratios) ###4~6,两个sizes代表例为1:1的,sizes代表其他比例的anchor,整体代表一个feature map有几个anchor 14 15 # Location. 对位置进行预测 16 num_loc_pred = num_anchors * 4 17 loc_pred = slim.conv2d(net, num_loc_pred, [3, 3], activation_fn=None, 18 scope='conv_loc') 19 loc_pred = custom_layers.channel_to_last(loc_pred) 20 loc_pred = tf.reshape(loc_pred, 21 tensor_shape(loc_pred, 4)[:-1]+[num_anchors, 4]) 22 # Class prediction. 对类别进行预测 23 num_cls_pred = num_anchors * num_classes 24 cls_pred = slim.conv2d(net, num_cls_pred, [3, 3], activation_fn=None, 25 scope='conv_cls') 26 cls_pred = custom_layers.channel_to_last(cls_pred) 27 cls_pred = tf.reshape(cls_pred, 28 tensor_shape(cls_pred, 4)[:-1]+[num_anchors, num_classes]) 29 return cls_pred, loc_pred ###生成每个feature map每个anchor的预测
接下来是利用上式结果生成默认的anchor.
1 def ssd_anchor_one_layer(img_shape, 2 feat_shape, 3 sizes, 4 ratios, 5 step, 6 offset=0.5, 7 dtype=np.float32): 8 ##函数作用:生成每一层feature map的不同方格的不同anchor的中心坐标和w,h并返回 9 ##生成每层feature map中每个小方框的中心坐标位置 *step/img_shape结果为在原图中相对位置 10 y, x = np.mgrid[0:feat_shape[0], 0:feat_shape[1]] 11 y = (y.astype(dtype) + offset) * step / img_shape[0] 12 x = (x.astype(dtype) + offset) * step / img_shape[1] 13 14 # Expand dims to support easy broadcasting. 15 y = np.expand_dims(y, axis=-1) 16 x = np.expand_dims(x, axis=-1) 17 18 # Compute relative height and width. 19 # Tries to follow the original implementation of SSD for the order. 20 ###每个feature map的每个小方格,有4-6个anchor,这4-6个anchor比例不同,分别为{1,2,3,1/2,1/3}。但是同一个feature map的不同小方格,对应的anchor 21 ####w,h是相通的 22 num_anchors = len(sizes) + len(ratios) ###anchor个数 23 h = np.zeros((num_anchors, ), dtype=dtype) 24 w = np.zeros((num_anchors, ), dtype=dtype) 25 # Add first anchor boxes with ratio=1. 1:1的anchor的w,h 26 h[0] = sizes[0] / img_shape[0] 27 w[0] = sizes[0] / img_shape[1] 28 di = 1 29 if len(sizes) > 1: ###另外一个1:1的anchor的w,h 30 h[1] = math.sqrt(sizes[0] * sizes[1]) / img_shape[0] 31 w[1] = math.sqrt(sizes[0] * sizes[1]) / img_shape[1] 32 di += 1 33 for i, r in enumerate(ratios): ####其他比例的anchor的w,h比如{2,3,1/2,1/3}计算方式已写 34 h[i+di] = sizes[0] / img_shape[0] / math.sqrt(r) 35 w[i+di] = sizes[0] / img_shape[1] * math.sqrt(r) 36 return y, x, h, w 37 38 39 def ssd_anchors_all_layers(img_shape, 40 layers_shape, 41 anchor_sizes, 42 anchor_ratios, 43 anchor_steps, 44 offset=0.5, 45 dtype=np.float32): 46 """Compute anchor boxes for all feature layers. 47 生成不同层feature map的anchor并返回 48 """ 49 layers_anchors = [] 50 for i, s in enumerate(layers_shape): 51 anchor_bboxes = ssd_anchor_one_layer(img_shape, s, 52 anchor_sizes[i], 53 anchor_ratios[i], 54 anchor_steps[i], 55 offset=offset, dtype=dtype) 56 layers_anchors.append(anchor_bboxes) 57 return layers_anchors
上面通过网络生成了预测的anchor坐标接下来便是ground Truth的处理,用到的函数主要为tf_ssd_bboxes_encode_layer。此函数的作用是对每一层feature map的预测框进行处理,去除掉不满足要求的预测框(即设为0),同时对满足要求的预测框找出与真实框的对应关系。
1 def tf_ssd_bboxes_encode_layer(labels, 2 bboxes, 3 anchors_layer, 4 num_classes, 5 no_annotation_label, 6 ignore_threshold=0.5, 7 prior_scaling=[0.1, 0.1, 0.2, 0.2], 8 dtype=tf.float32): 9 """Encode groundtruth labels and bounding boxes using SSD anchors from 10 one layer. 11 12 Arguments: 13 labels: 1D Tensor(int64) containing groundtruth labels; 14 bboxes: Nx4 Tensor(float) with bboxes relative coordinates; 15 anchors_layer: Numpy array with layer anchors; 16 matching_threshold: Threshold for positive match with groundtruth bboxes; 17 prior_scaling: Scaling of encoded coordinates. 18 19 Return: 20 (target_labels, target_localizations, target_scores): Target Tensors. 21 """ 22 # Anchors coordinates and volume. 23 yref, xref, href, wref = anchors_layer ###固定生成的anchor的中心坐标及w,h等 24 ymin = yref - href / 2. 25 xmin = xref - wref / 2. 26 ymax = yref + href / 2. 27 xmax = xref + wref / 2. 28 vol_anchors = (xmax - xmin) * (ymax - ymin) ###预测框四个角的坐标及面积 29 30 # Initialize tensors... 31 shape = (yref.shape[0], yref.shape[1], href.size) ###S*S*(4-6) 32 feat_labels = tf.zeros(shape, dtype=tf.int64) ##每个预测框的标签 33 feat_scores = tf.zeros(shape, dtype=dtype)##每个预测框的得分 34 ###每个预测框四个点的坐标 35 feat_ymin = tf.zeros(shape, dtype=dtype) 36 feat_xmin = tf.zeros(shape, dtype=dtype) 37 feat_ymax = tf.ones(shape, dtype=dtype) 38 feat_xmax = tf.ones(shape, dtype=dtype) 39 ####计算预测框与真实框的IOU ,box为真实框的坐标 40 def jaccard_with_anchors(bbox): 41 """Compute jaccard score between a box and the anchors. 42 """ 43 int_ymin = tf.maximum(ymin, bbox[0]) 44 int_xmin = tf.maximum(xmin, bbox[1]) 45 int_ymax = tf.minimum(ymax, bbox[2]) 46 int_xmax = tf.minimum(xmax, bbox[3]) 47 h = tf.maximum(int_ymax - int_ymin, 0.) 48 w = tf.maximum(int_xmax - int_xmin, 0.) 49 # Volumes. 50 inter_vol = h * w 51 union_vol = vol_anchors - inter_vol 52 + (bbox[2] - bbox[0]) * (bbox[3] - bbox[1]) 53 jaccard = tf.div(inter_vol, union_vol) 54 return jaccard 55 ####score得分即为重叠部分/预测框面积 56 def intersection_with_anchors(bbox): 57 """Compute intersection between score a box and the anchors. 58 """ 59 int_ymin = tf.maximum(ymin, bbox[0]) 60 int_xmin = tf.maximum(xmin, bbox[1]) 61 int_ymax = tf.minimum(ymax, bbox[2]) 62 int_xmax = tf.minimum(xmax, bbox[3]) 63 h = tf.maximum(int_ymax - int_ymin, 0.) 64 w = tf.maximum(int_xmax - int_xmin, 0.) 65 inter_vol = h * w 66 scores = tf.div(inter_vol, vol_anchors) 67 return scores 68 69 def condition(i, feat_labels, feat_scores, 70 feat_ymin, feat_xmin, feat_ymax, feat_xmax): 71 """Condition: check label index. 72 """ 73 r = tf.less(i, tf.shape(labels)) 74 return r[0] 75 76 def body(i, feat_labels, feat_scores, 77 feat_ymin, feat_xmin, feat_ymax, feat_xmax): 78 """Body: update feature labels, scores and bboxes. 79 Follow the original SSD paper for that purpose: 80 - assign values when jaccard > 0.5; 81 - only update if beat the score of other bboxes. 82 """ 83 # Jaccard score. 84 label = labels[i] 85 bbox = bboxes[i] 86 jaccard = jaccard_with_anchors(bbox) 87 # Mask: check threshold + scores + no annotations + num_classes. 88 mask = tf.greater(jaccard, feat_scores) 89 # mask = tf.logical_and(mask, tf.greater(jaccard, matching_threshold)) 90 mask = tf.logical_and(mask, feat_scores > -0.5) 91 mask = tf.logical_and(mask, label < num_classes) ####逻辑判断,那些项IOU大于阈值 92 imask = tf.cast(mask, tf.int64) 93 fmask = tf.cast(mask, dtype) 94 # Update values using mask.更新那些满足要求的预测框,使他们类别,四个点的坐标位置和置信度分别为真实框的值,否则为0 95 feat_labels = imask * label + (1 - imask) * feat_labels 96 feat_scores = tf.where(mask, jaccard, feat_scores) 97 98 feat_ymin = fmask * bbox[0] + (1 - fmask) * feat_ymin 99 feat_xmin = fmask * bbox[1] + (1 - fmask) * feat_xmin 100 feat_ymax = fmask * bbox[2] + (1 - fmask) * feat_ymax 101 feat_xmax = fmask * bbox[3] + (1 - fmask) * feat_xmax 102 103 # Check no annotation label: ignore these anchors... 104 # interscts = intersection_with_anchors(bbox) 105 # mask = tf.logical_and(interscts > ignore_threshold, 106 # label == no_annotation_label) 107 # # Replace scores by -1. 108 # feat_scores = tf.where(mask, -tf.cast(mask, dtype), feat_scores) 109 110 return [i+1, feat_labels, feat_scores, 111 feat_ymin, feat_xmin, feat_ymax, feat_xmax] 112 # Main loop definition. 113 i = 0 114 [i, feat_labels, feat_scores, 115 feat_ymin, feat_xmin, 116 feat_ymax, feat_xmax] = tf.while_loop(condition, body, 117 [i, feat_labels, feat_scores, 118 feat_ymin, feat_xmin, 119 feat_ymax, feat_xmax]) 120 # Transform to center / size. 121 feat_cy = (feat_ymax + feat_ymin) / 2. 122 feat_cx = (feat_xmax + feat_xmin) / 2. 123 feat_h = feat_ymax - feat_ymin 124 feat_w = feat_xmax - feat_xmin 125 # Encode features. 126 feat_cy = (feat_cy - yref) / href / prior_scaling[0] 127 feat_cx = (feat_cx - xref) / wref / prior_scaling[1] 128 feat_h = tf.log(feat_h / href) / prior_scaling[2] 129 feat_w = tf.log(feat_w / wref) / prior_scaling[3] 130 # Use SSD ordering: x / y / w / h instead of ours. 此处返回的不是坐标值,而是偏差值。此处与SSD不同 131 feat_localizations = tf.stack([feat_cx, feat_cy, feat_w, feat_h], axis=-1) 132 return feat_labels, feat_localizations, feat_scores
接下来便是最重要的部分,即损失函数源码阅读。损失函数在论文中定义如下

分为类别置信度偏差和坐标位移偏差。上式已经有进过网络的的提取的值及经过groundTruth处理后的值,现在把两者结合,进行loss计算。主要的函数为ssd_losses。
1 def ssd_losses(logits, localisations, 2 gclasses, glocalisations, gscores, 3 match_threshold=0.5, 4 negative_ratio=3., 5 alpha=1., 6 label_smoothing=0., 7 device='/cpu:0', 8 scope=None): 9 with tf.name_scope(scope, 'ssd_losses'): 10 lshape = tfe.get_shape(logits[0], 5) 11 num_classes = lshape[-1] 12 batch_size = lshape[0] 13 14 # Flatten out all vectors! 对预测框与groundTruth分别进行reshape,然后组合 15 flogits = [] 16 fgclasses = [] 17 fgscores = [] 18 flocalisations = [] 19 fglocalisations = [] 20 for i in range(len(logits)): 21 flogits.append(tf.reshape(logits[i], [-1, num_classes])) 22 fgclasses.append(tf.reshape(gclasses[i], [-1])) 23 fgscores.append(tf.reshape(gscores[i], [-1])) 24 flocalisations.append(tf.reshape(localisations[i], [-1, 4])) 25 fglocalisations.append(tf.reshape(glocalisations[i], [-1, 4])) 26 # And concat the crap! 27 logits = tf.concat(flogits, axis=0) 28 gclasses = tf.concat(fgclasses, axis=0) 29 gscores = tf.concat(fgscores, axis=0) 30 localisations = tf.concat(flocalisations, axis=0) 31 glocalisations = tf.concat(fglocalisations, axis=0) 32 dtype = logits.dtype 33 34 # Compute positive matching mask... 35 ###筛选IOU>0.5的预测框 36 pmask = gscores > match_threshold 37 fpmask = tf.cast(pmask, dtype) 38 n_positives = tf.reduce_sum(fpmask) 39 40 # Hard negative mining... 41 ###对于IOU《0.5的归为负类,即背景,预测项为第0项 42 no_classes = tf.cast(pmask, tf.int32) 43 predictions = slim.softmax(logits) 44 nmask = tf.logical_and(tf.logical_not(pmask), 45 gscores > -0.5) 46 fnmask = tf.cast(nmask, dtype) 47 nvalues = tf.where(nmask, 48 predictions[:, 0], 49 1. - fnmask) 50 nvalues_flat = tf.reshape(nvalues, [-1]) 51 # Number of negative entries to select. 52 ###负类最大比例为正类的3倍 53 max_neg_entries = tf.cast(tf.reduce_sum(fnmask), tf.int32) 54 n_neg = tf.cast(negative_ratio * n_positives, tf.int32) + batch_size 55 n_neg = tf.minimum(n_neg, max_neg_entries) 56 57 val, idxes = tf.nn.top_k(-nvalues_flat, k=n_neg) 58 max_hard_pred = -val[-1] 59 # Final negative mask. 60 nmask = tf.logical_and(nmask, nvalues < max_hard_pred) 61 fnmask = tf.cast(nmask, dtype) 62 63 # Add cross-entropy loss.正类和负类的类别损失函数计算方式不同,主要是因为标签不一样 64 with tf.name_scope('cross_entropy_pos'): 65 loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, 66 labels=gclasses) 67 loss = tf.div(tf.reduce_sum(loss * fpmask), batch_size, name='value') 68 tf.losses.add_loss(loss) 69 70 with tf.name_scope('cross_entropy_neg'): 71 loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits, 72 labels=no_classes) 73 loss = tf.div(tf.reduce_sum(loss * fnmask), batch_size, name='value') 74 tf.losses.add_loss(loss) 75 76 # Add localization loss: smooth L1, L2, ... 77 with tf.name_scope('localization'): ###预测预测损失函数 78 # Weights Tensor: positive mask + random negative. 79 weights = tf.expand_dims(alpha * fpmask, axis=-1) 80 loss = custom_layers.abs_smooth(localisations - glocalisations) 81 loss = tf.div(tf.reduce_sum(loss * weights), batch_size, name='value') 82 tf.losses.add_loss(loss) ###最终的loss
最后一部分就是前面的图像处理及预测之后的图像处理函数了。ssd_vgg_preprocessing.py是对训练或者预测图像进行预处理。就是图像增强这类的工作。
ssd_common.py中tf_ssd_bboxes_decode_layer 函数是对预测后的坐标进行处理,在图像中标出预测框的位置。而np_methods.py中基本是对预测框进行筛选,nms等,找出最合适的预测框
1 def tf_ssd_bboxes_decode_layer(feat_localizations, 2 anchors_layer, 3 prior_scaling=[0.1, 0.1, 0.2, 0.2]): 4 """Compute the relative bounding boxes from the layer features and 5 reference anchor bounding boxes. 6 7 Arguments: 8 feat_localizations: Tensor containing localization features. 9 anchors: List of numpy array containing anchor boxes. 10 11 Return: 12 Tensor Nx4: ymin, xmin, ymax, xmax 13 """ 14 yref, xref, href, wref = anchors_layer 15 16 # Compute center, height and width 基本就是前面处理坐标的逆向过程。anchores_layer为不同anchor的坐标, 17 # feat_locations为预测框的偏差,反过来可以倒推预测框的坐标 18 cx = feat_localizations[:, :, :, :, 0] * wref * prior_scaling[0] + xref 19 cy = feat_localizations[:, :, :, :, 1] * href * prior_scaling[1] + yref 20 w = wref * tf.exp(feat_localizations[:, :, :, :, 2] * prior_scaling[2]) 21 h = href * tf.exp(feat_localizations[:, :, :, :, 3] * prior_scaling[3]) 22 # Boxes coordinates. 23 ymin = cy - h / 2. 24 xmin = cx - w / 2. 25 ymax = cy + h / 2. 26 xmax = cx + w / 2. 27 bboxes = tf.stack([ymin, xmin, ymax, xmax], axis=-1) 28 return bboxes