Tesseract OCR 该软件包包含一个OCR引擎 - libtesseract和一个命令行程序 - tesseract。 Tesseract 4增加了一个基于OCR引擎的新神经网络(LSTM),该引擎专注于线路识别,但仍然支持Tesseract 3的传统Tesseract OCR引擎,该引擎通过识别字符模式来工作。通过使用Legacy OCR Engine模式(--oem 0)启用与Tesseract 3的兼容性。它还需要训练有素的数据文件,这些文件支持传统引擎,例如来自tessdata存储库的文件
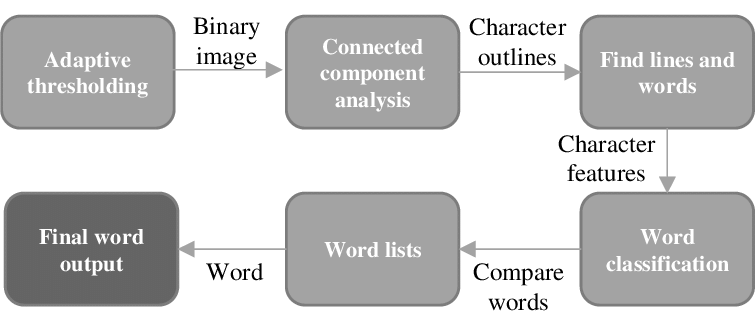
tesseract 4.0已经加入LSTM了,在用命令行执行的时候,添加 “–oem 1”参数即可,但是pythonocr模块里并没有提供使用oem参数的init函数,查看tesseract的源码,capi.cpp定位到257行有
在外部调用的时候,只需要将以前的
- handle = tesseract_raw.init(lang='eng')
修改成:
- handle = tesseract_raw.init(lang='eng', oem=1)
即可。下载最新支持lstm的tessdata数据包,识别结果会比之前有大大的提高!如何在调用API的时候使用多语言,就如同命令行下的 -l eng+chi这种,还在摸索中
tesseract 4.0: https://digi.bib.uni-mannheim.de/tesseract/
安装包:https://github.com/UB-Mannheim/tesseract/wiki

安装完后测试:

参考资料