1. 什么是字符编码:将人识别的字符转换计算机能识别的01,转换的规则就是字符编码表
2. 常用的编码表:ascii、unicode、GBK、Shift_JIS、Euc-kr
3. 编码操作:编码encode()、解码decode()
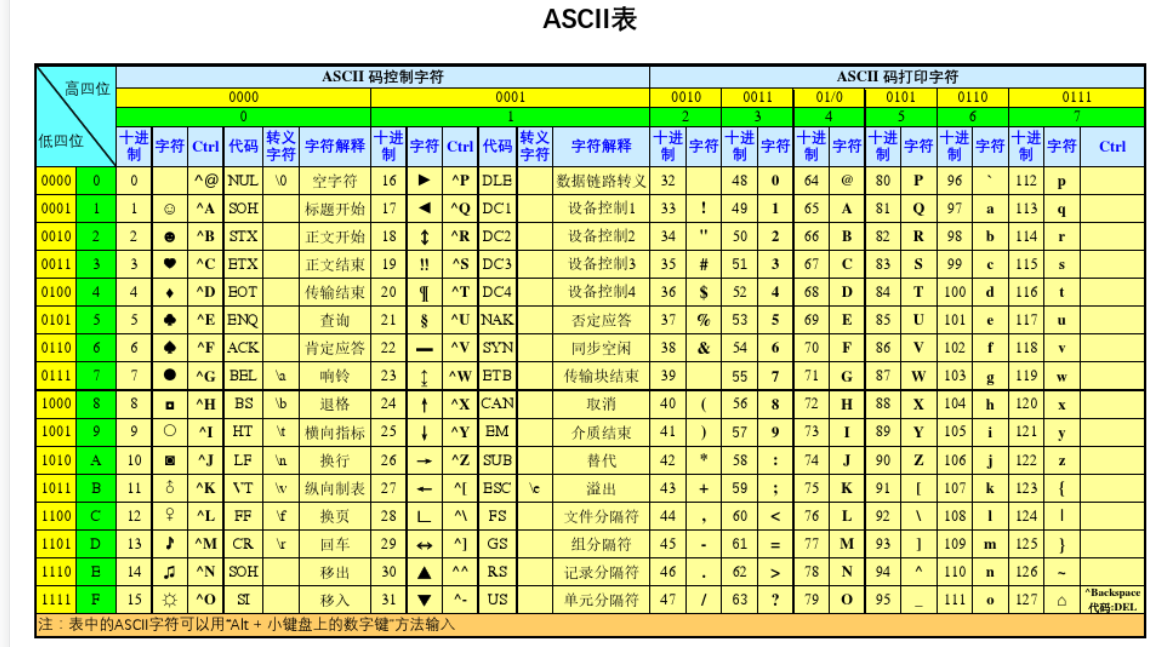
现代计算机起源于美国,所以最先考虑仅仅是让计算机识别英文字符,于是诞生了ASCII表
1.什么是ASCII表:英文字符、数字与机器能识别的字符的对应关系表
2.特点:
#1.只有英文字符与数字的一一对应关系
#2.一个英文字符对应1Bytes,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字
#3.python2采用的默认编码是ASCII,早期并不支持中文编程
二.GBK编码
为了让计算机能够识别中文和英文,中国人定制了GBK
特点:
1、只有中文字符、英文字符与数字的一一对应关系 2、一个英文字符对应1Bytes 一个中文字符对应2Bytes 补充说明: 1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符 2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
补充:
# Shift_JIS表的特点: 1、只有日文字符、英文字符与数字的一一对应关系 # Euc-kr表的特点: 1、只有韩文字符、英文字符与数字的一一对应关系
unicode万国码
简介
1.世间中常用国家的常用字符与机器能识别的字符的对应关系表
2.unicode于1990年开始研发,1994年正式公布,具备两大特点:
#1.存在所有语言中的所有字符与数字的一一对应关系,即兼容万国字符
#2.与传统的字符编码的二进制数都有对应关系,
详解
# 均采用Unicode编码表,只是存放数据采用字节数不一致,utf-8与utf-16是Unicode编码表的两种体现方式 # utf-8:以1个字节存放英文,欧洲的是2个字节,以3 | 6个字节存放汉字,在英文数据过多时,更深空间,用来传输效率更高 # utf-16:所有支持的符号都采用2个字节存放,读存数据采用定长,不用计算,读存效率高 # 硬盘到内存需要数据的传输,内存到CPU需要数据的传输,所有都采用utf-8 # 内存需要高速读写,采用utf-16
编码与解码
# 学习的结晶:编码与解码要统一编码 # 操作文本字符 res = "汉字呵呵".encode('utf-8') # 编码:将普通字符串转化为二进制字符串 print(res) # b'xe6xb1x89xe5xadx97xe5x91xb5xe5x91xb5' res = b'xe5x91xb5xe5x91xb5'.decode('GBK') # 解码:将二进制字符串转化为普通字符串 print(res) # 鍛靛懙 乱码了 res = b'xe5x91xb5xe5x91xb5'.decode('utf-8') print(res) # 呵呵 读写编码统一后就不乱码了