必须要懂的交叉熵:
https://cloud.tencent.com/developer/article/1539723

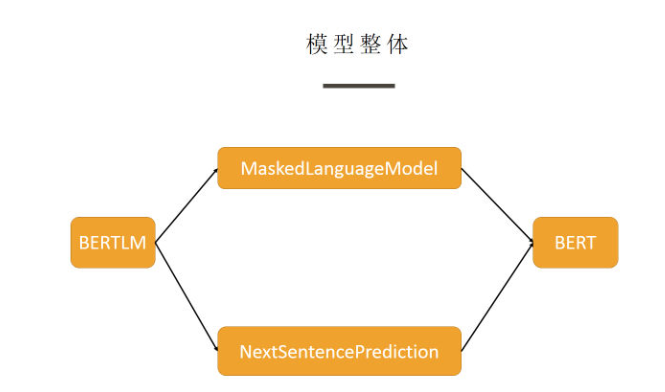
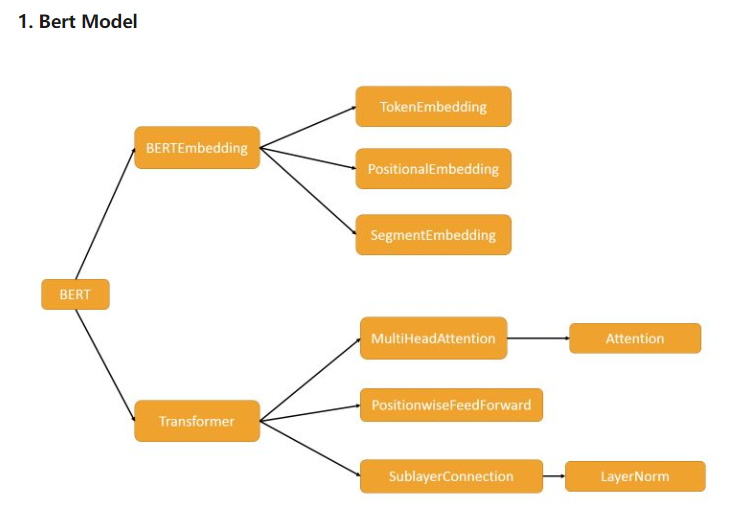
这部分其实就是 Transformer Encoder 部分 + BERT Embedding, 如果不熟悉 Transformer 的同学,恰好可以从此处来加深理解。
这部分源码阅读建议可先大致浏览一下整体, 有一个大致的框架,明白各个类之间的依赖关系,然后从细节到整体逐渐理解,即从上图看,从右往左读,效果会更好。
1. BERTEmbedding
分为三大部分:
- TokenEmbedding : 对 token 的编码,继承于
nn.Embedding, 默认初始化为 :N(0,1) - SegmentEmbedding: 对句子信息编码,继承于
nn.Embedding, 默认初始化为 :N(0,1) - PositionalEmbedding: 对位置信息编码, 可参见论文,生成的是一个固定的向量表示,不参与训练
这里面需要注意的就是 PositionalEmbedding, 因为有些面试官会很抠细节,而我对这些我觉得对我没有啥帮助的东西,一般了解一下就放过了,细节没有抠清楚,事实证明,吃亏了。
2. Transformer
这里面的东西十分建议对照论文一起看,当然,如果很熟的话可以略过。 我在里面关键的地方都加上了注释,如果还是看不懂的话可以提 issue, 这里就不赘述了。

我们说的contextualized word embedding 就是取中间这个部分的向量出来,这里是上文的所有信息。
高烧退了
丞退了
这两个向量都是不同的
elmo直接用两个参数相加更新, 全都要
h = a1*h1 + a2*h2
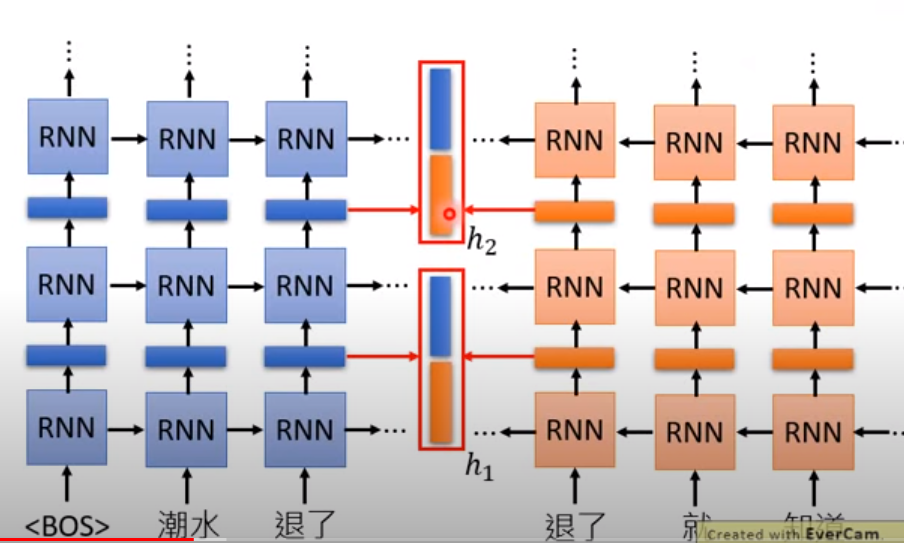
bert抽取出来的[mask 词]的embedding 一定要够准,要不然linear classifier本来就是一个很弱的分类器,他认不出词语的
BERT 其實就是 Transformer 中的 Encoder,只是有很多層

bert情感分类问题:(只在开头做一个输出)
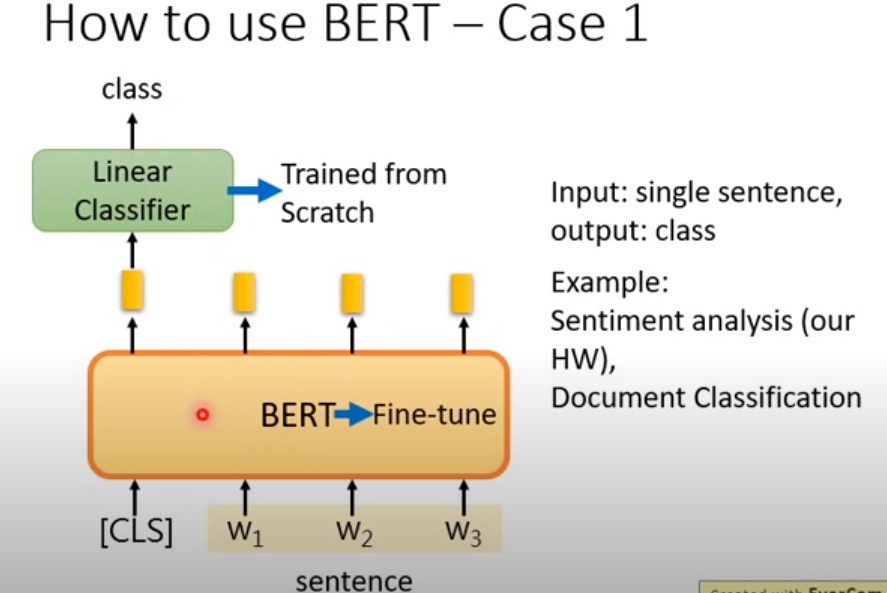
bert序列标注问题
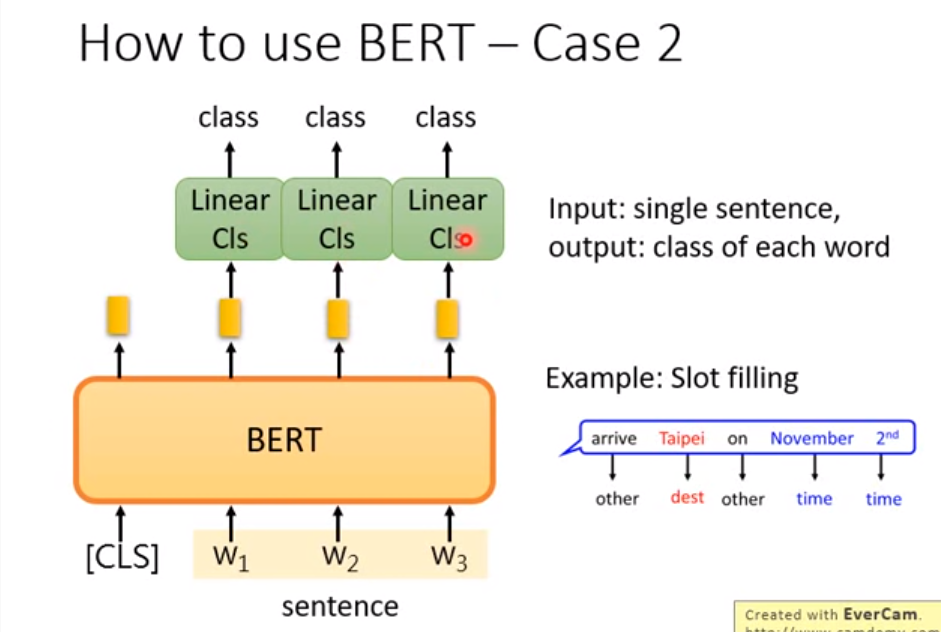
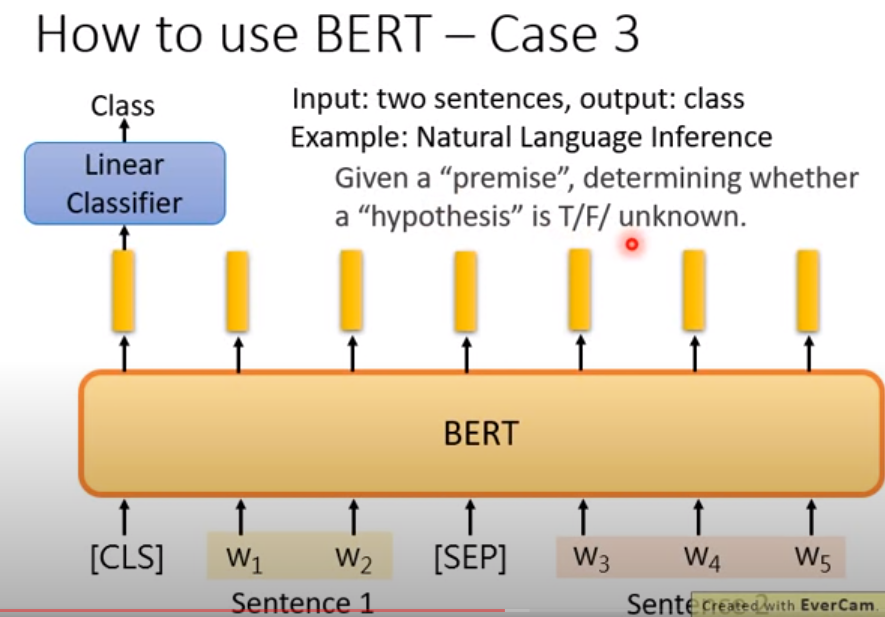
bert在NLI问题(句子匹配,问句匹配)
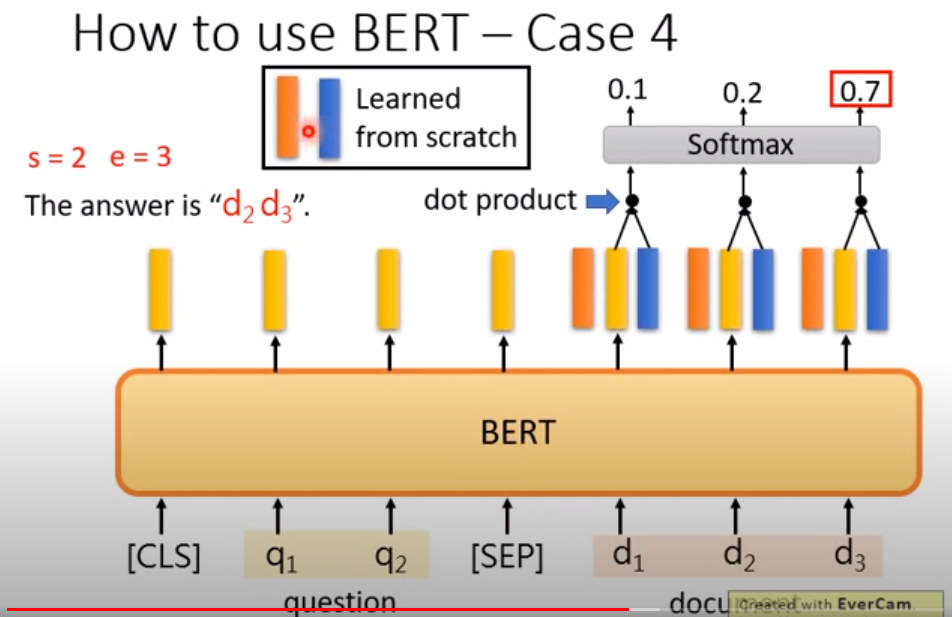
bert在信息抽取,阅读理解上面的应用

橙色和蓝色的vector和黄色的其实是一个模型出来的,但是为了表示不同的主题(问句和文档),因此才划分成三种。
最后用1(橙色和黄色) 2(黄色和蓝色)分别做一个人softmax的映射,找出1 2 对应的位置信息
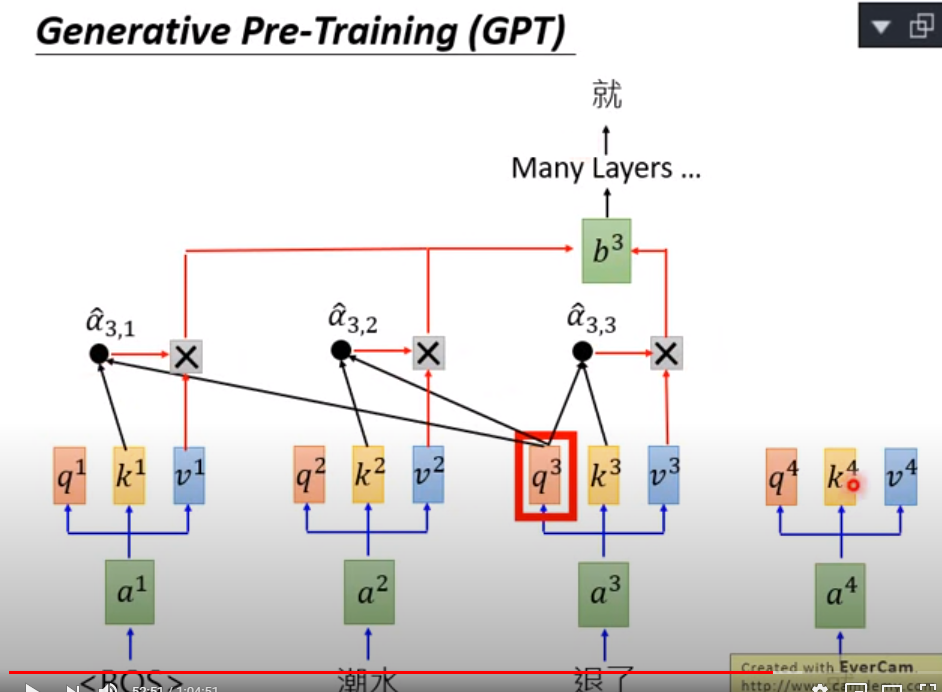
GPT的意思就是三个主要参数,和前面的做一个交互(self-attention),然后两个交互项目之间做一个weighted sum ,最后预测下一个词
我们说的self-attention 其实外部看起来作用和biRNN 很像,都是一个sequence进出
同时输出的每个每个信息都是带有上下文信息的

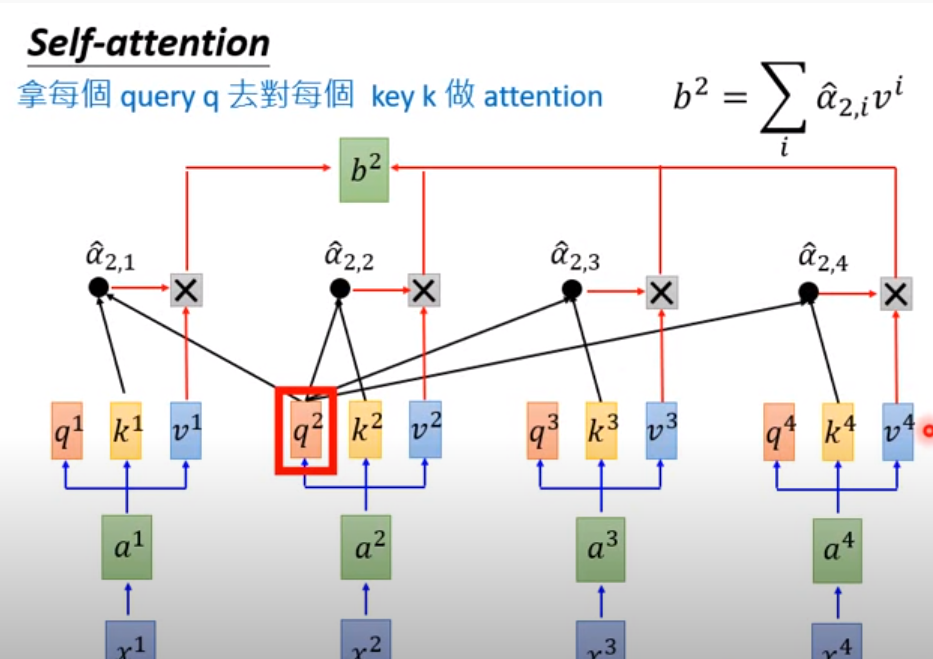
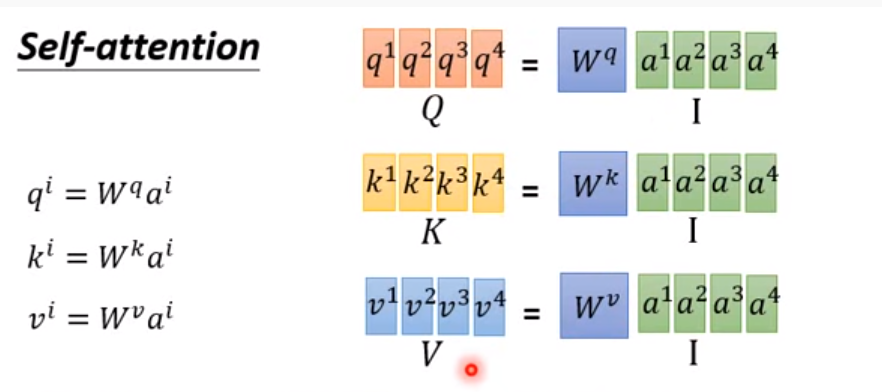
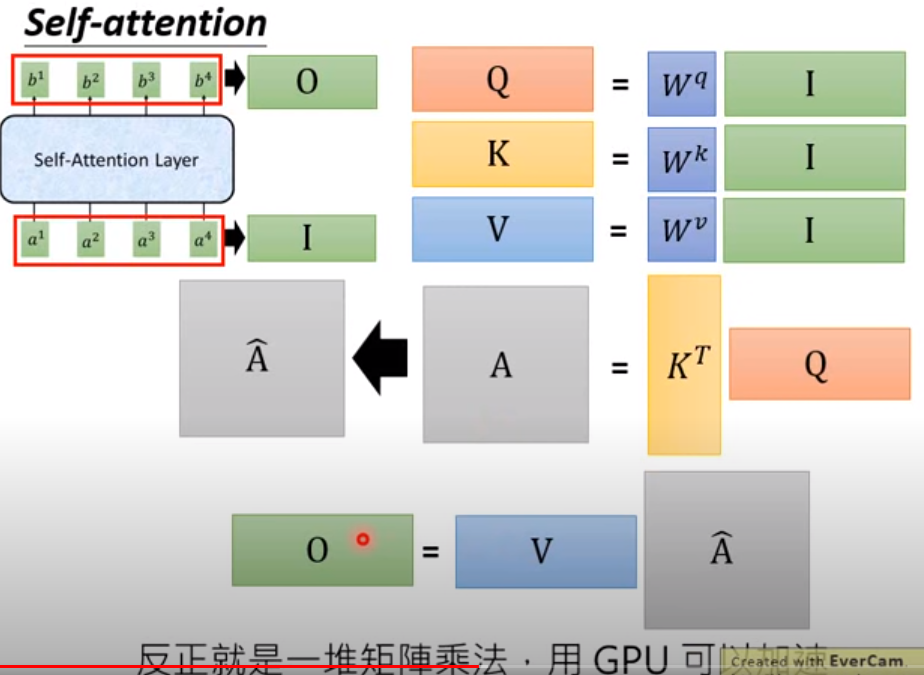
注意QKV三个参数的不同表示
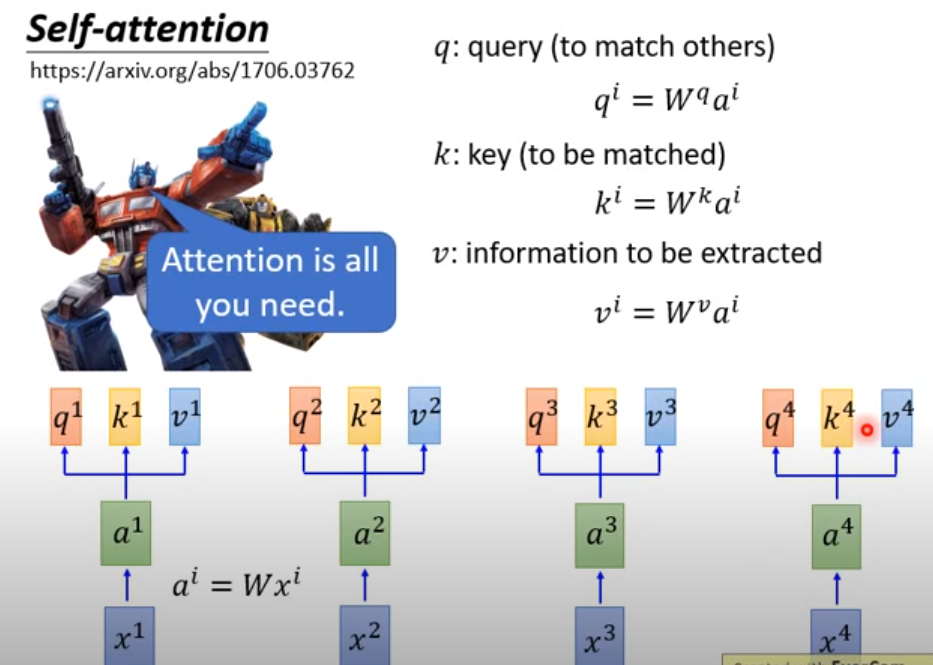
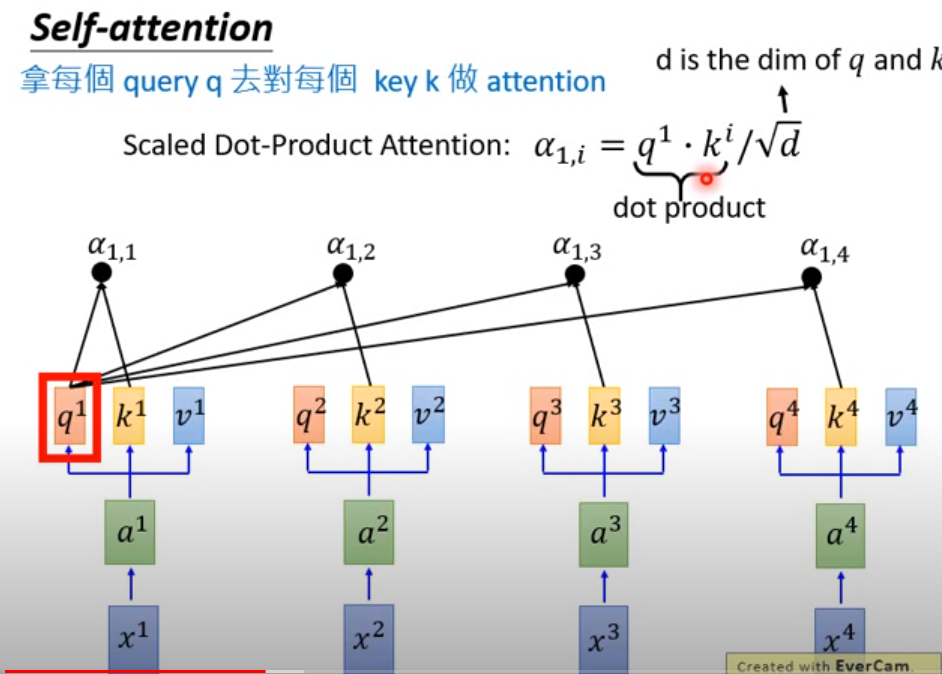
这里是self-attention的计算方式(简单来说就是用Q去match其他的K,就是用新的值去表示两者之间的距离)
为什么是这个值,是因为这个值类似余弦相似度的计算:
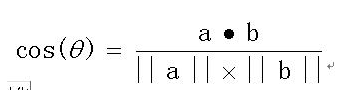
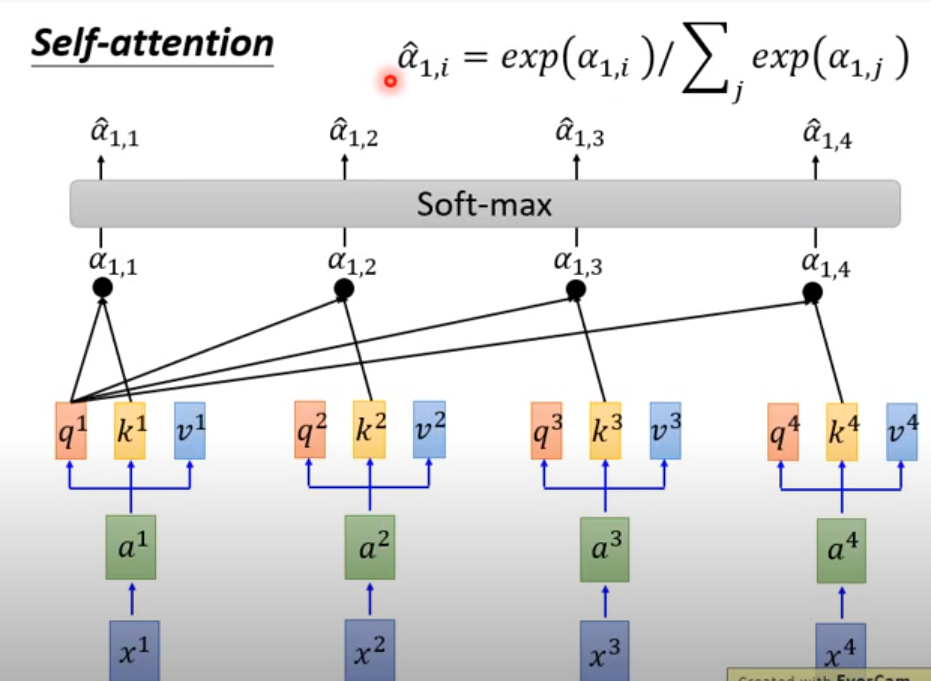
为了让a的值适合训练一点,做一个softmax的计算,得到a head^
z最后出来的序列是【b1,b2,b3,...bn】这里才是带有句子信息的新的表示
对于a head ,他就类似一个weighted sum --》 得到b
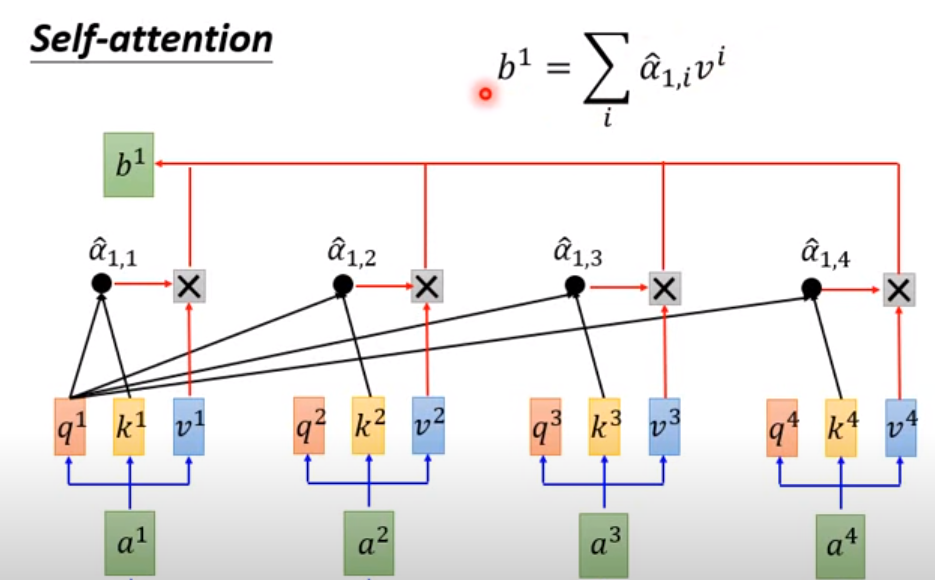
再来一次:
【b1,b2,b3,...bn】以上的都是平行计算出来的(用矩阵)
计算过程(矩阵平行计算的过程)

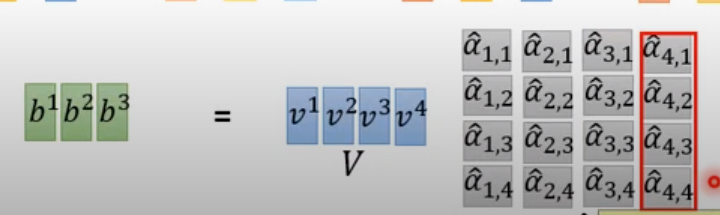
总的流程如下
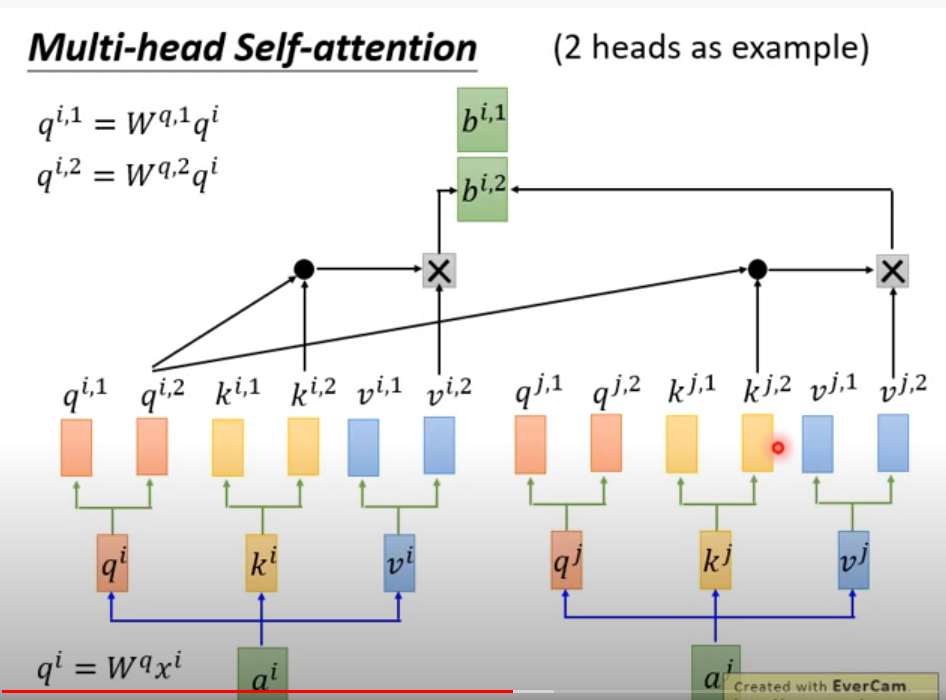
multi head 的做法,其实就是从开头那里开始就乘多一个矩阵,一个参数变两个,整体的参数量多两倍
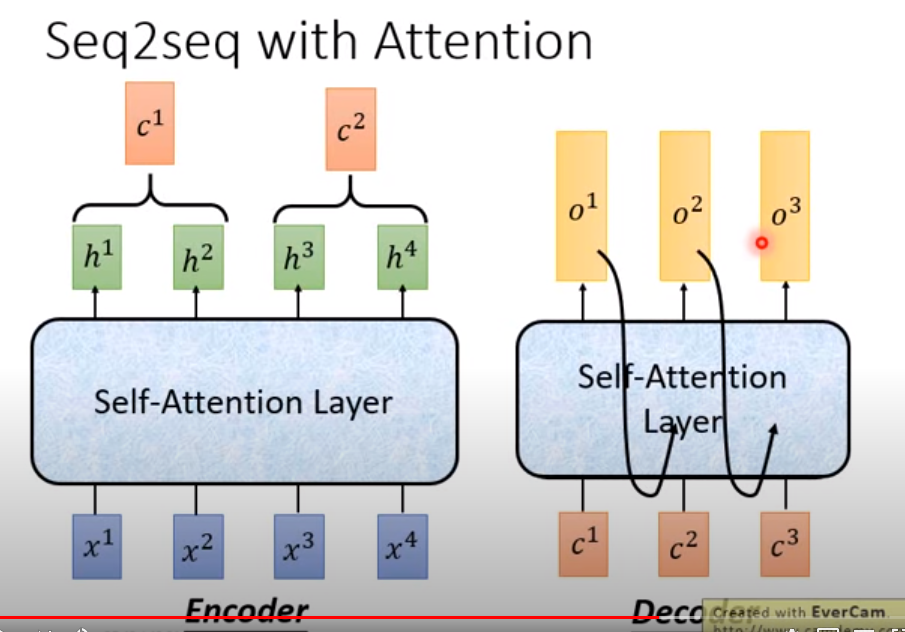
bert的话只用到了encoder的这一层,注意区别
https://www.youtube.com/watch?v=ugWDIIOHtPA
(动图在37.10)很明显看出差别
机器学习--machine learning
1/ encoder部门,先把 机器学习 表示成一个序列,然后预测出下一个词<BOS>.
2/ 然后再结合《 机器学习 + BOS》 预测出下一个词machine
3/ 最后《 机器学习 + BOS + machine》 预测出下一个词learning
batch norm 是对一个batch 来做normalization
layer norm是对一个层来做,不考虑batch 数据分布(常和RNN一起来做)
下面这个add就是把self attention处理过的信息【b1b2...bn】+[a1,a2...an]
这个做法类似信息的highway

masked的部分是表示要预测的部分。参考动图应该是《 机器学习 + BOS》 >>>>>> 【machine + **】
