性能指标
性能优化的两个核心指标——"吞吐"和"延迟",这是从应用负载的视角来进行考察系统性能,直接影响了产品终端的用户体验。与之对应的是从系统资源的视角出发的指标,比如资源使用率、饱和度等。
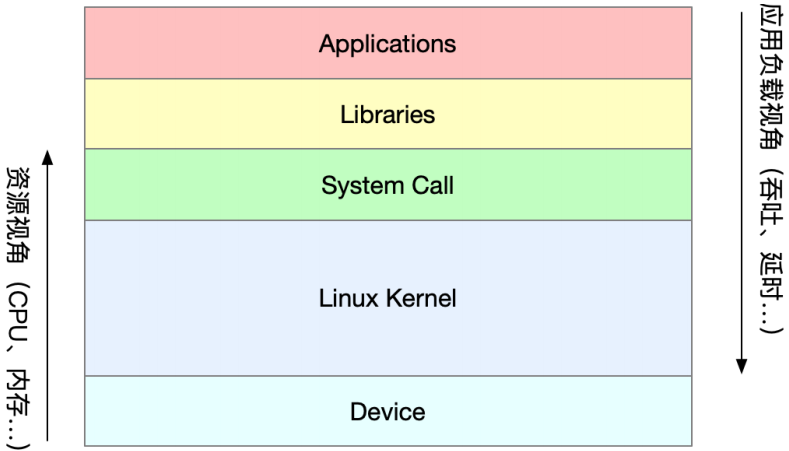
我们知道,随着应用负载的增加,系统资源的使用也会升高,甚至达到极限。而性能问题的本质,就是系统资源已经达到瓶颈,但请求的处理却还不够快,无法支撑更多的请求。
性能分析,其实就是找出应用或系统的瓶颈,并设法去避免或者缓解他们,从而更高效地利用系统资源处理更多的请求。这包含了一系列的步骤,比如下面这六个步骤。
-
选择指标评估应用程序和系统的性能
-
为应用程序和系统设置性能目标
-
进行性能基准测试
-
性能分析定位瓶颈
-
优化系统和应用程序
-
性能监控和告警
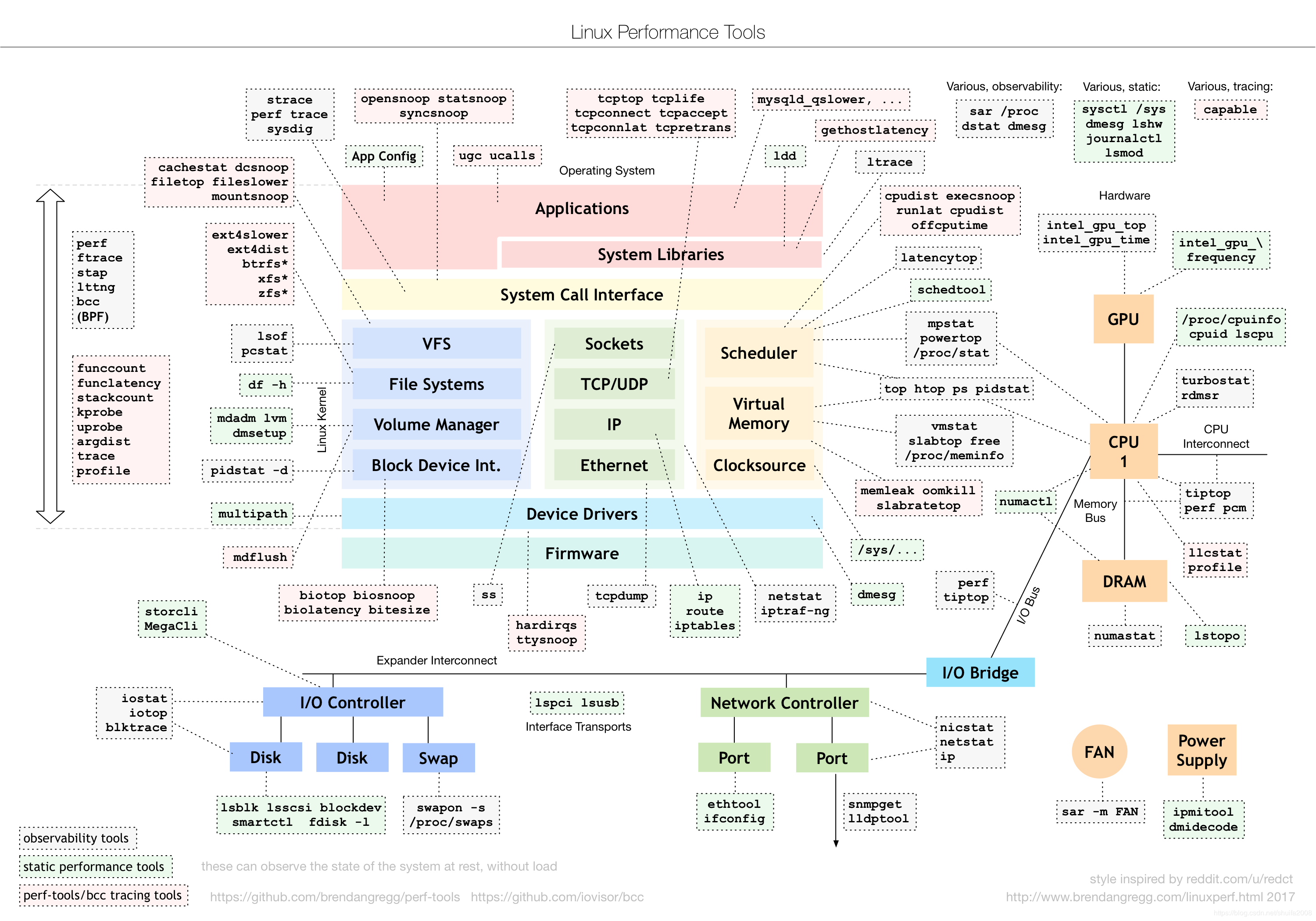
这个图是Linux性能分析最重要的参考资料之一,它告诉你,在Linux不同子系统出现性能问题后,应该用什么样的工具来观测和分析。
比如,当遇到IO性能问题时,可以参考图片下方的IO子系统,使用iostat、iotop、blktrace等工具分析磁盘IO的瓶颈。
理解平均负载
平均负载
平均负载是指单位时间内,系统处于可运行状态和不可中断状态的平均进程数,也就是平均活跃进程数,它和CPU使用率并没有直接关系。
可运行状态的进程,是指正在使用CPU或者正在等待CPU的进程,也就是ps命令查看进程状态中的R状态(Running或Runnable)。
不可中断状态的进程,是指正处于内核态关键流程中的进程,并且这些流程是不可打断的,比如最长间的是等待硬件设备的IO响应,也就是ps命令查看进程状态中的D状态。例如,当一个进程向磁盘读取数据时,为了保证数据的一致性,在得到磁盘回复前,它是不能被其他进程或者中断打断,这个时候的进程处于不可中断状态。如果此时的进程被打断,就容易出现磁盘数据与进程数据不一致的问题。所以,不可中断状态实际上是系统对进程和硬件设备的一种保护机制。因此平均负载可以理解为平均活跃进程数。平均进程活跃数,直观上的理解就是单位时间内的活跃进程数,但实际上是活跃进程数的指数衰减平均值,可以直接理解为活跃进程数的平均值。
如果当平均负载为2时,就意味着
-
在只有2个CPU的系统上,意味着所有的CPU都刚好被完全占用。
-
在4个CPU的系统上,意味着CPU有50%的空闲。
-
在1个CPU的系统中,意味着有一半的进程竞争不到CPU
平均负载为多少时合理
平均负载最理想的情况是等于CPU个数,所以在评判平均负载时,首先要知道系统有几个CPU,有了CPU个数,我们可以判断出,当平均负载比CPU个数还大的时候,系统已经出现了过载。
三个不同时间间隔的平均负载,其实给我们提供了,分析系统负载趋势的数据来源,让我们更能全面、更立体地理解目前的负载情况。
-
如果1分钟、5分钟、15分钟的三个值基本相同,或者相差不大,那就说明系统负载很平稳。
-
但如果1分钟的值远小于15分钟的值,就说明系统最近1分钟的负载在减少,而过去15分钟内却有很大的负载
-
如果1分钟的值远大于15分钟的值,就说明最近1分钟的负载在增加,这种增加有可能只是临时性的,也有可能还会持续增加下去,所以就需要持续观察。一旦1分钟的平均负载接近或者超过CPU的个数,就意味着系统正在发生过载的问题,这时就得分析调查是哪里导致的问题,并要想办法优化。
分析排查负载过高的问题需要把系统的平均负载监控起来,然后根据更多的历史数据,判断负载的变化趋势,当发生负载有明显升高趋势时,比如说负载翻倍了,再去做分析和调查
平均负载与CPU使用率
-
CPU密集型进程,使用大量CPU会导致平均负载升高
-
IO密集型进程,等待IO也会导致平均负载升高,单CPU使用率不一定很高。
-
大量等待CPU的进程调度也会导致平均负载升高,此时的CPU使用率也会比较高。
分析负载工具
CPU场景监控
mpstat是一个常用的多核CPU性能分析工具,用来实时查看每个CPU的性能指标,以及所有CPU的平均指标
[root@localhost ~]# mpstat 2 Linux 2.6.32-431.el6.x86_64 (localhost.localdomain) 04/27/2020 _x86_64_ (4 CPU) 05:49:27 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 05:49:29 PM all 0.50 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.00 05:49:31 PM all 0.38 0.00 0.38 0.00 0.00 0.00 0.00 0.00 99.25 05:49:33 PM all 0.25 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.25 05:49:35 PM all 0.25 0.00 0.50 0.00 0.00 0.00 0.00 0.00 99.25
pidstat是一个常用的进程性能分析工具,用来实时查看进程的CPU、内存、IO以及山下文切换等性能指标。
[root@localhost ~]# stress --cpu 1 --timeout 600 stress: info: [6168] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd [root@localhost ~]# uptime 17:59:36 up 405 days, 8:51, 2 users, load average: 0.99, 0.75, 0.35 [root@localhost ~]# mpstat -P ALL 2 3 Linux 2.6.32-431.el6.x86_64 (localhost.localdomain) 04/27/2020 _x86_64_ (4 CPU) 05:57:44 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 05:57:46 PM all 25.41 0.00 0.50 0.00 0.00 0.00 0.00 0.00 74.09 05:57:46 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 05:57:46 PM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 05:57:46 PM 2 1.01 0.00 0.00 0.00 0.00 0.00 0.00 0.00 98.99 05:57:46 PM 3 0.00 0.00 2.01 0.00 0.00 0.00 0.00 0.00 97.99 05:57:46 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 05:57:48 PM all 25.37 0.00 0.50 0.00 0.00 0.00 0.00 0.00 74.12 05:57:48 PM 0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 100.00 05:57:48 PM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 05:57:48 PM 2 1.00 0.00 0.50 0.00 0.00 0.00 0.00 0.00 98.50 05:57:48 PM 3 1.00 0.00 1.49 0.00 0.00 0.00 0.00 0.00 97.51 [root@localhost ~]# pidstat -u 5 1 Linux 2.6.32-431.el6.x86_64 (localhost.localdomain) 04/27/2020 _x86_64_ (4 CPU) 06:08:20 PM PID %usr %system %guest %CPU CPU Command 06:08:25 PM 3360 0.00 0.20 0.00 0.20 0 redis-server 06:08:25 PM 3593 0.20 0.20 0.00 0.40 3 bash 06:08:25 PM 3723 0.60 0.20 0.00 0.80 0 netdata 06:08:25 PM 3748 0.20 0.00 0.00 0.20 0 python 06:08:25 PM 7276 100.00 0.00 0.00 100.00 1 stress 06:08:25 PM 7289 0.00 0.20 0.00 0.20 3 pidstat 06:08:25 PM 25850 0.40 1.00 0.00 1.40 2 apps.plugin Average: PID %usr %system %guest %CPU CPU Command Average: 3360 0.00 0.20 0.00 0.20 - redis-server Average: 3593 0.20 0.20 0.00 0.40 - bash Average: 3723 0.60 0.20 0.00 0.80 - netdata Average: 3748 0.20 0.00 0.00 0.20 - python Average: 7276 100.00 0.00 0.00 100.00 - stress Average: 7289 0.00 0.20 0.00 0.20 - pidstat Average: 25850 0.40 1.00 0.00 1.40 - apps.plugin
首先利用stress模拟一个CPU使用率100%的情况,然后利用uptime观察平均负载的变化情况,最后使用mpstat查看每个CPU使用率的情况;从uptime命令可以看到1分钟内的平均负载==1,而mpstat命令看到CPU1的使用率为100%,且都是在用户态空间使用的CPU,说明导致负载升高是由于CPU使用率比较高引起的负载升高;最后使用pidstat监测,发现是stress进程CPU使用为100%
IO密集型应用
[root@localhost ~]# stress -i 1 --timeout 600 stress: info: [7582] dispatching hogs: 0 cpu, 1 io, 0 vm, 0 hdd [root@localhost ~]# uptime 18:13:11 up 405 days, 9:05, 2 users, load average: 0.80, 0.66, 0.46 [root@localhost ~]# uptime 18:13:16 up 405 days, 9:05, 2 users, load average: 0.82, 0.66, 0.47 [root@localhost ~]# uptime 18:13:24 up 405 days, 9:05, 2 users, load average: 0.84, 0.67, 0.47 [root@localhost ~]# uptime 18:13:30 up 405 days, 9:05, 2 users, load average: 0.86, 0.68, 0.47 [root@localhost ~]# uptime 18:13:39 up 405 days, 9:05, 2 users, load average: 0.88, 0.69, 0.48 [root@localhost ~]# uptime 18:13:47 up 405 days, 9:05, 2 users, load average: 0.90, 0.70, 0.48 [root@localhost ~]# uptime 18:14:05 up 405 days, 9:06, 2 users, load average: 0.92, 0.71, 0.49 [root@localhost ~]# uptime 18:14:22 up 405 days, 9:06, 2 users, load average: 0.94, 0.73, 0.50 [root@localhost ~]# uptime 18:14:47 up 405 days, 9:06, 2 users, load average: 0.96, 0.74, 0.51 [root@localhost ~]# uptime 18:15:28 up 405 days, 9:07, 2 users, load average: 0.98, 0.78, 0.53 [root@localhost ~]# mpstat -P ALL 5 1 Linux 2.6.32-431.el6.x86_64 (localhost.localdomain) 04/27/2020 _x86_64_ (4 CPU) 06:17:07 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle 06:17:12 PM all 0.35 0.00 24.90 0.05 0.00 0.00 0.00 0.00 74.70 06:17:12 PM 0 0.00 0.00 0.40 0.00 0.00 0.00 0.00 0.00 99.60 06:17:12 PM 1 0.00 0.00 97.79 0.00 0.00 0.00 0.00 0.00 2.21 06:17:12 PM 2 0.40 0.00 1.20 0.00 0.00 0.00 0.00 0.00 98.40 06:17:12 PM 3 0.81 0.00 0.60 0.00 0.00 0.00 0.00 0.00 98.59 Average: CPU %usr %nice %sys %iowait %irq %soft %steal %guest %idle Average: all 0.35 0.00 24.90 0.05 0.00 0.00 0.00 0.00 74.70 Average: 0 0.00 0.00 0.40 0.00 0.00 0.00 0.00 0.00 99.60 Average: 1 0.00 0.00 97.79 0.00 0.00 0.00 0.00 0.00 2.21 Average: 2 0.40 0.00 1.20 0.00 0.00 0.00 0.00 0.00 98.40 Average: 3 0.81 0.00 0.60 0.00 0.00 0.00 0.00 0.00 98.59 Linux 2.6.32-431.el6.x86_64 (localhost.localdomain) 04/27/2020 _x86_64_ (4 CPU) Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await r_await w_await svctm %util sda 0.00 6.62 0.00 0.28 0.10 55.18 197.39 0.00 16.34 17.61 16.33 2.20 0.06 sdb 0.00 8.30 0.00 0.14 0.09 67.52 466.32 0.00 19.77 11.13 19.87 1.55 0.02 dm-0 0.00 0.00 0.01 15.34 0.19 122.70 8.01 0.03 2.04 22.82 2.03 0.05 0.08 dm-1 0.00 0.00 0.00 0.00 0.00 0.00 8.00 0.00 9.10 9.16 8.86 6.09 0.00
可以看到结合iostat分析发现导致负载升高的是IO导致系统负载升高
[root@localhost ~]# stress -c 8 --timeout 600 stress: info: [8429] dispatching hogs: 8 cpu, 0 io, 0 vm, 0 hdd
利用stress -c 8 --timeout 600可以模拟更加复杂的场景
Linux是一个多任务操作系统,它支持远大于CPU数量的任务同时运行。当然,这些任务实际上并不是真的在同时运行,而是因为系统在很短的时间内,将CPU轮流分配给它们,造成多任务同时运行的错觉。每个任务运行前,CPU都需要知道任务从哪里加载,又从哪里开始运行,也就是说,需要系统事先帮它设置好CPU寄存器和程序计数器。CPU寄存器,是CPU内置的容量小,但速度极快的内存。程序计数器,则是用来存储CPU正在执行的指令位置,或者即将执行的下一条指令位置。它们都是CPU在运行任务前,必须的依赖环境,因此也被叫做CPU上下文。
CPU上下文切换,就是先把前一个任务的CPU上下文保存起来,然后加载新任务的上下文到这些寄存器和程序计数器,最后再跳转到程序计数器所指的新位置,运行新任务。而这些保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再次加载进来。这样就能保证任务原来的状态不受影响,让任务看起来还是连续执行。
根据任务的不同,CPU的上下文切换就可以分为进程上下文切换、线程上下文切换以及中断上下文切换。
Linux按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中,CPU特权等级的Ring0和Ring3。
-
内核空间(Ring0)具有最高权限,可以直接访问所有资源;
-
用户空间(Ring3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源。
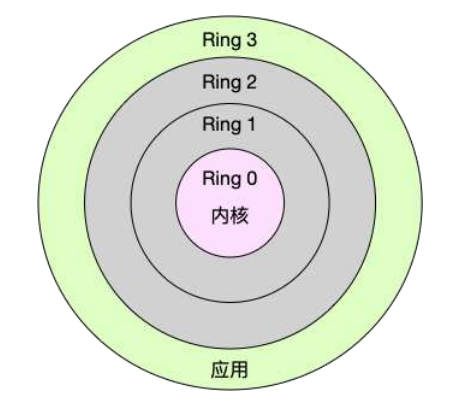
也就是说,进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态。
从用户态到内核态的转变,需要通过系统调用来完成。比如,当我们查看文件内容时,就需要多次系统调用来完成:首先调用open()打开文件,然后调用read()读取文件内容,并调用write()将内容写到标准输出,最后再调用close()关闭文件。
CPU寄存器里原来用户态的指令位置,需要先保存起来。接着,为了执行内核态代码,CPU寄存器需要更新为内核态指令的新位置,最后才是跳转到内核态运行内核任务。
而系统调用结束后,CPU寄存器需要恢复原来保存的用户态,然后在切换到用户空间,继续运行进程。所以,一次系统调用的过程,其实是发生了两次CPU上下文切换。
不过,需要注意的是,系统调用过程中,并不会涉及到虚拟内存等进程用户的资源,也不会切换进程。这与我们通常所说的进程上下文切换是不一样的:
-
进程上下文切换,是指从一个进程切换到另一个进程运行。
-
而系统调用过程中一直是同一个进程在运行。
所以,系统调用过程通常称为特权模式切换,而不是上下文切换。但实际上,系统调用过程中,CPU的上下文切换还是无法避免的。
进程上下文切换跟系统调用的区别:
首先,需要知道,进程是由内核来管理和调度的,进程的切换只能发生在内核态。所以,进程的上下文不仅包括了虚拟内存、栈、全局变量等用户空间的资源,还包括了内核堆栈、寄存器等内核空间的状态。
因此,进程上下文切换就比系统调用多了一步:在保存当前进程的内核状态和CPU寄存器之前,需要先把该进程的虚拟内存、栈等保存下来;而加载了下一进程的内核态后,还需要刷新进程的虚拟内存和用户栈。
如下图所示,保存上下文和恢复上下文的过程并不是免费的,需要内核在CPU上运行才能完成。

根据研究表明,每次上下文切换都需要几十纳秒到数微秒的CPU时间,这个时间还是相当可观的,特别是在进程上下文切换次数较多的情况下,很容易导致CPU将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了真正运行进程的时间。这也是导致平均负载上升的一个重要因素。
Linux通过TLB来管理虚拟内存到物理内存的映射关系。当虚拟内存更新后,TLB也需要刷新,内存的访问也会随之变慢。特别是在多处理系统上,缓存是被多个处理器共享的,刷新缓存不仅会影响当前处理器的进程,还会影响共享缓存的其他处理器的进程。
显然,进程切换时才需要切换上下文,换句话说,只有在进程调度的时候,才需要切换上下文。Linux为每个CPU都维护了一个就绪队列,将活跃进程(即正在运行和正在等待CPU的进程)按照优先级和等待CPU的时间排序,然后选择最需要CPU的进程,这也就是优先级最高和等待CPU时间最长的进程来运行。
触发进程调度的场景:
-
为了保证所有进程可以得到公平调度,CPU时间被划分为一段段的时间片,这些时间片再被轮流分配给各个进程。这样,当某个进程的时间片耗尽了,就会被系统挂起,切换到其它正在等待CPU的进程执行。
-
进程在系统资源不足时,要等到资源满足后才可以运行,这个时候进程也会被挂起,并由系统调度其它进程运行。
-
当进程通过睡眠函数sleep这样的方法将自己主动挂起时,自然也会重新调度。
-
当有优先级更高的进程运行时,为了保证高优先级进程的运行,当前进程会被挂起,由高优先级进程来运行。
-
当发生硬中断时,CPU上的进程会被挂起,转而执行内核中的中断服务程序。
线程上下文切换
线程与进程最大的区别在于,线程是调度的基本单位,而进程则是资源拥有的基本单位。所谓内核中的任务调度,实际上的调度对象是线程;而进程只是给线程提供了虚拟内存、全局变量等资源。所以,对于线程和进程可以这么理解:
-
当进程只有一个线程时,可以认为进程就等于线程。
-
当进程拥有多个线程时,这些线程会共享相同的虚拟内存和全局变量等资源。这些资源在上下文切换时是不需要修改的。
-
线程也有自己的私有数据,比如栈和寄存器等,这些在上下文切换时也是需要保存的。
因此,线程的上下文切换其实就可以分为两种情况:
第一种,前后两个线程属于不同进程。此时,资源不同享,所以切换过程就跟进程上下文切换是一样的。
第二种,前后两个线程属于同一个进程。此时,虚拟内存是共享的,所以在切换时,虚拟内存这些资源就保持不动,只需要切换线程的私有数据、寄存器等不同享数据。
通过以上情况可以发现,虽然同为上下文切换,但同进程内的线程切换,要比多进程间切换消耗更少的资源,而这,也正是多线程代替多进程的一个优势。
中断上下文切换
切换进程CPU上下文,其实就是中断上下文切换。为了快速响应硬件的事件,中断处理会打断进程的正常调度和执行,转而调用中断处理程序,响应设备事件。而在打断其他进程时,就需要将进程当前状态保存下来,这样在中断结束后,进程仍然可以从原来的状态恢复运行。
跟进程上下文不同,中断上下文切换并不涉及到进程的用户态。所以,即便中断过程打断了一个正处在用户态的进程,也不需要保存和恢复这个进程的虚拟内存、全局变量等用户态资源。中断上下文,其实只包括内核态中断服务程序执行所必须的状态,包括CPU寄存器、内核堆栈、硬件中断参数等。
对同一个CPU来说,中断处理比进程拥有更高的优先级,所以中断上下文切换并不会与进程上下文切换同时发生。同样道理,由于中断会打断正常进程的调度和执行,所以大部分中断处理程序都短小精悍,以便尽可能快的执行结束。
另外,跟进程上下文切换一样,中断上下文切换也需要消耗CPU,切换次数过多也会消耗大量的CPU,甚至严重降低系统的整体性能。所以,当发现中断次数过多时,就需要注意去排查它是否会给系统带来严重的性能问题。
CPU上下文切换分析
查看系统上下文
利用vmstat工具来进行查看上下文切换,例如:
[root@localhost ~]# vmstat 2 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 384 1303264 215296 12506412 0 0 0 15 0 0 1 1 98 0 0 0 0 384 1303256 215296 12506412 0 0 0 0 237 201 0 0 99 0 0 0 0 384 1303000 215296 12506412 0 0 0 8 290 227 1 1 99 0 0 0 0 384 1302884 215296 12506412 0 0 0 0 227 206 0 1 99 0 0 0 0 384 1302628 215296 12506412 0 0 0 0 250 231 0 1 99 0 0
-
cs是每秒上下文切换的次数
-
in则是每秒钟中断的次数
-
r是就绪队列的长度,也就是正在运行和等待CPU的进程数
-
b则是出于不可中断睡眠状态的进程数
可以看到,这个例子中的上线文切换次数cs是201次,而系统中断in则是237次,而就绪队列长度r和不可中断状态进程数b都是0。
vmstat只给出了系统总体的上下文切换情况,要向查看每个进程的详细情况,就需要使用到pidstat了,如下:
[root@localhost ~]# pidstat -w 5 Linux 2.6.32-431.el6.x86_64 (localhost.localdomain) 04/29/2020 _x86_64_ (4 CPU) 05:00:25 PM PID cswch/s nvcswch/s Command 05:00:30 PM 3 0.20 0.00 migration/0 05:00:30 PM 4 0.20 0.00 ksoftirqd/0 05:00:30 PM 7 0.40 0.00 migration/1 05:00:30 PM 9 0.20 0.00 ksoftirqd/1 05:00:30 PM 13 0.20 0.00 ksoftirqd/2 05:00:30 PM 15 0.60 0.00 migration/3 05:00:30 PM 17 2.40 0.00 ksoftirqd/3 05:00:30 PM 19 1.20 0.00 events/0 05:00:30 PM 20 1.00 0.00 events/1 05:00:30 PM 21 1.00 0.00 events/2 05:00:30 PM 22 1.00 0.00 events/3 05:00:30 PM 28 0.20 0.00 sync_supers 05:00:30 PM 29 0.20 0.00 bdi-default 05:00:30 PM 197 1.00 0.00 mpt_poll_0 05:00:30 PM 353 0.20 0.00 flush-253:0 05:00:30 PM 598 1.00 0.00 vmmemctl 05:00:30 PM 1202 0.40 0.00 master 05:00:30 PM 1231 1.00 0.00 zabbix_agentd 05:00:30 PM 1235 1.00 0.00 zabbix_agentd 05:00:30 PM 2912 2.00 0.00 bash 05:00:30 PM 3360 10.98 0.00 redis-server 05:00:30 PM 3748 1.00 0.20 python 05:00:30 PM 5830 0.40 0.00 showq 05:00:30 PM 5883 0.20 0.00 pidstat 05:00:30 PM 29194 1.00 1.60 apps.plugin
这个结果中有两列内容是我们重点关注的对象。一个是cswch,表示每秒自愿上下文切换的次数,另一个则是mbcswch,表示每秒非自愿上下文切换的次数。
这两个概念意味着不同的性能问题:
-
自愿上下文切换,是指进程无法获取所需自愿,导致上下文切换。比如,IO、内存等系统资源不足时,就会发生自愿上下文切换。
-
非自愿上下文切换,则是指进程由于时间片已到等原因,被系统强制调度,进而发生的上下文切换。比如说,大量进程都在争抢CPU时,就容易发生非自愿上下文切换。
模拟场景
使用sysbench来模拟系统多线程调度切换的情况。
sysbench是一个多线程的基准测试工具,一般用来评估不同系统参数下的数据库负载情况,可以用来模拟上下文切换过多的问题。
测试前的数据查看情况
[root@localhost ~]# vmstat 1 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 0 0 384 1302564 215296 12506416 0 0 0 15 0 0 1 1 98 0 0 0 0 384 1302556 215296 12506416 0 0 0 0 257 207 1 1 99 0 0 0 0 384 1302556 215296 12506416 0 0 0 0 223 192 1 1 99 0 0 0 0 384 1302440 215296 12506416 0 0 0 0 257 219 1 1 99 0 0 0 0 384 1302176 215296 12506416 0 0 0 4 248 225 0 0 99 0 0 0 0 384 1302176 215296 12506416 0 0 0 0 218 203 1 1 99 0 0 0 0 384 1303044 215296 12506416 0 0 0 0 371 239 1 1 98 0 0 0 0 384 1302804 215296 12506416 0 0 0 0 232 213 0 1 99 0 0
在终端离运行sysbench,模拟系统多线程调度的瓶颈:
[root@localhost ~]# sysbench --threads=10 --max-time=300 threads run WARNING: --max-time is deprecated, use --time instead sysbench 1.0.17 (using system LuaJIT 2.0.4) Running the test with following options: Number of threads: 10 Initializing random number generator from current time Initializing worker threads... Threads started!
执行sysbench后,使用vmstat来进行监控:
[root@localhost ~]# vmstat 2 procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu----- r b swpd free buff cache si so bi bo in cs us sy id wa st 1 0 384 1297912 215400 12509840 0 0 0 15 0 0 1 1 98 0 0 2 0 384 1298036 215400 12509840 0 0 0 10 279 214 1 1 99 0 0 1 0 384 1298052 215400 12509840 0 0 0 0 241 202 1 1 99 0 0 8 0 384 1296716 215400 12509840 0 0 0 0 7069 257920 3 39 57 0 0 8 0 384 1296468 215400 12509840 0 0 0 0 17640 477390 7 80 13 0 0 10 0 384 1295592 215400 12509840 0 0 0 0 18891 657740 6 85 9 0 0 8 0 384 1295724 215400 12509840 0 0 0 0 19504 597917 7 82 11 0 0
观测数据可以发现:
-
r列:就绪队列的长度已经到8,远远超过了系统CPU的个数2,所以肯定会有大量的CPU竞争。
-
us和sy列:这两列的CPU使用率加起来上升到了100%,其中系统CPU使用率,也就是sy列高达80%左右,说明CPU主要是被内核占用了。
-
in列:中断次数也上升到了将近2万左右,说明中断处理也是个潜在的问题。
vmstat详解如下:
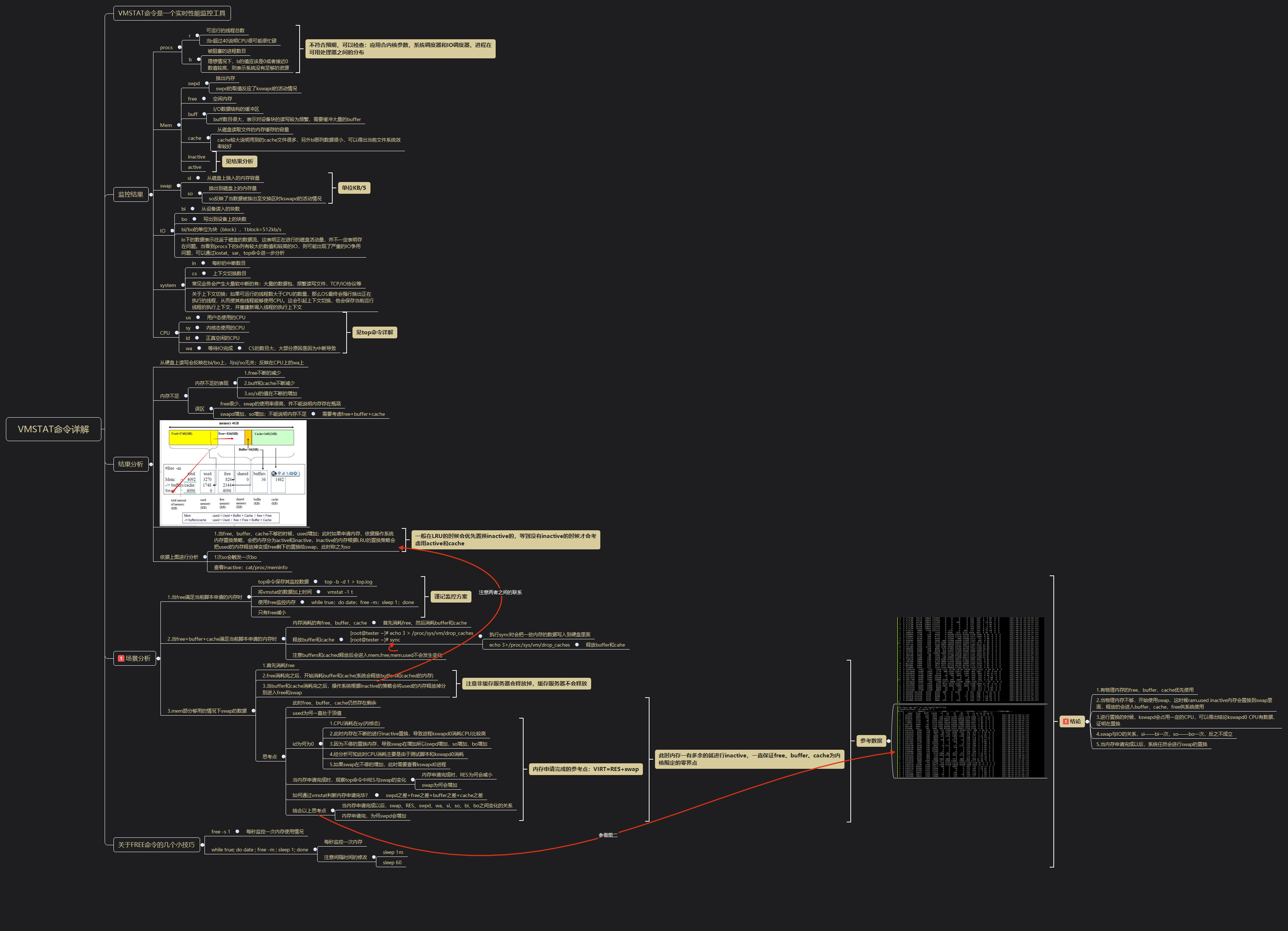
综合这几个指标,可以知道,系统的就绪队列过长,也就是正在运行和等待CPU的进程数过多,导致了大量的上下文切换,而上下文切换又导致了系统CPU的占用率升高。
[root@localhost ~]# pidstat -w -u 1 Linux 2.6.32-431.el6.x86_64 (localhost.localdomain) 04/29/2020 _x86_64_ (4 CPU) 05:25:40 PM PID %usr %system %guest %CPU CPU Command 05:25:41 PM 17 0.00 0.98 0.00 0.98 3 ksoftirqd/3 05:25:41 PM 3360 0.98 0.98 0.00 1.96 1 redis-server 05:25:41 PM 3723 1.96 0.98 0.00 2.94 1 netdata 05:25:41 PM 7661 28.43 100.00 0.00 100.00 1 sysbench 05:25:41 PM 7698 0.00 0.98 0.00 0.98 3 pidstat 05:25:41 PM 29194 0.98 0.98 0.00 1.96 1 apps.plugin 05:25:40 PM PID cswch/s nvcswch/s Command 05:25:41 PM 4 7.84 0.00 ksoftirqd/0 05:25:41 PM 9 1.96 0.00 ksoftirqd/1 05:25:41 PM 13 10.78 0.00 ksoftirqd/2 05:25:41 PM 17 10.78 0.00 ksoftirqd/3 05:25:41 PM 19 0.98 0.00 events/0 05:25:41 PM 20 0.98 0.00 events/1 05:25:41 PM 21 0.98 0.00 events/2 05:25:41 PM 22 0.98 0.00 events/3 05:25:41 PM 29 0.98 0.00 bdi-default 05:25:41 PM 61 0.98 0.00 khugepaged 05:25:41 PM 197 0.98 0.00 mpt_poll_0 05:25:41 PM 598 0.98 0.00 vmmemctl 05:25:41 PM 1231 0.98 0.00 zabbix_agentd 05:25:41 PM 1235 0.98 0.00 zabbix_agentd 05:25:41 PM 3360 10.78 0.00 redis-server 05:25:41 PM 3748 0.98 116.67 python 05:25:41 PM 7109 2.94 78.43 bash 05:25:41 PM 7698 0.98 1.96 pidstat 05:25:41 PM 29194 0.98 313.73 apps.plugin
从pidstat的输出可以发现,CPU使用率的升高是由于sysbench导致的,它的CPU使用率已经达到了100%,但上下文切换则是来自其他进程,包括自愿上下文切换频率较高的redis-server和内核进程ksoftirqd/2、ksoftirqd/3,以及非自愿上下文切换频率比较高的python和apps.plugnin。
由于Linux调度的最小单位是线程,而sysbench模拟的也是线程的调度问题,因此vmstat显示的中断次数远大于pidstat中显示的次数,在pidstat后面加上选项-t,对线程进行监控:如下
[root@localhost ~]# pidstat -w -t -u 1 Linux 2.6.32-431.el6.x86_64 (localhost.localdomain) 04/29/2020 _x86_64_ (4 CPU) 06:05:28 PM TGID TID %usr %system %guest %CPU CPU Command 06:05:29 PM 13 - 0.00 0.97 0.00 0.97 2 ksoftirqd/2 06:05:29 PM - 13 0.00 0.97 0.00 0.97 2 |__ksoftirqd/2 06:05:29 PM - 3726 0.00 0.97 0.00 0.97 1 |__netdata 06:05:29 PM - 3738 0.00 0.97 0.00 0.97 2 |__netdata 06:05:29 PM - 4020 0.00 0.97 0.00 0.97 0 |__python 06:05:29 PM 10405 - 33.98 100.00 0.00 100.00 1 sysbench 06:05:29 PM - 10406 4.85 36.89 0.00 41.75 1 |__sysbench 06:05:29 PM - 10407 2.91 31.07 0.00 33.98 2 |__sysbench 06:05:29 PM - 10408 2.91 33.01 0.00 35.92 2 |__sysbench 06:05:29 PM - 10409 2.91 33.98 0.00 36.89 2 |__sysbench 06:05:29 PM - 10410 3.88 33.98 0.00 37.86 3 |__sysbench 06:05:29 PM - 10411 3.88 33.01 0.00 36.89 2 |__sysbench 06:05:29 PM - 10412 1.94 31.07 0.00 33.01 2 |__sysbench 06:05:29 PM - 10413 4.85 33.01 0.00 37.86 3 |__sysbench 06:05:29 PM - 10414 2.91 33.01 0.00 35.92 1 |__sysbench 06:05:29 PM - 10415 3.88 34.95 0.00 38.83 0 |__sysbench 06:05:29 PM 10428 - 0.97 1.94 0.00 2.91 0 pidstat 06:05:29 PM - 10428 0.97 1.94 0.00 2.91 0 |__pidstat 06:05:29 PM 29194 - 0.00 0.97 0.00 0.97 2 apps.plugin 06:05:29 PM - 29194 0.00 0.97 0.00 0.97 2 |__apps.plugin 06:05:28 PM TGID TID cswch/s nvcswch/s Command 06:05:29 PM 4 - 9.71 0.00 ksoftirqd/0 06:05:29 PM - 4 9.71 0.00 |__ksoftirqd/0 06:05:29 PM 9 - 7.77 0.00 ksoftirqd/1 06:05:29 PM - 9 7.77 0.00 |__ksoftirqd/1 06:05:29 PM 13 - 7.77 0.00 ksoftirqd/2 06:05:29 PM - 13 7.77 0.00 |__ksoftirqd/2 06:05:29 PM 17 - 15.53 0.00 ksoftirqd/3 06:05:29 PM - 17 15.53 0.00 |__ksoftirqd/3 06:05:29 PM 19 - 0.97 0.00 events/0 06:05:29 PM - 19 0.97 0.00 |__events/0 06:05:29 PM 20 - 0.97 0.00 events/1 06:05:29 PM - 20 0.97 0.00 |__events/1 06:05:29 PM 21 - 0.97 0.00 events/2 06:05:29 PM - 21 0.97 0.00 |__events/2 06:05:29 PM 22 - 0.97 0.00 events/3 06:05:29 PM - 22 0.97 0.00 |__events/3 06:05:29 PM 28 - 0.97 0.00 sync_supers 06:05:29 PM - 28 0.97 0.00 |__sync_supers 06:05:29 PM 197 - 0.97 0.00 mpt_poll_0 06:05:29 PM - 197 0.97 0.00 |__mpt_poll_0 06:05:29 PM 598 - 0.97 0.00 vmmemctl 06:05:29 PM - 598 0.97 0.00 |__vmmemctl 06:05:29 PM 1202 - 0.97 0.00 master 06:05:29 PM - 1202 0.97 0.00 |__master 06:05:29 PM 1231 - 0.97 0.00 zabbix_agentd 06:05:29 PM - 1231 0.97 0.00 |__zabbix_agentd 06:05:29 PM 1235 - 1.94 0.00 zabbix_agentd 06:05:29 PM - 1235 1.94 0.00 |__zabbix_agentd 06:05:29 PM 3360 - 10.68 0.00 redis-server 06:05:29 PM - 3360 10.68 0.00 |__redis-server 06:05:29 PM - 3725 0.97 31.07 |__netdata 06:05:29 PM - 3726 0.97 0.00 |__netdata 06:05:29 PM - 3727 0.97 0.00 |__netdata 06:05:29 PM - 3728 2.91 0.00 |__netdata 06:05:29 PM - 3729 49.51 2.91 |__netdata 06:05:29 PM - 3730 0.97 0.00 |__netdata 06:05:29 PM - 3733 0.97 0.00 |__netdata 06:05:29 PM - 3738 0.97 87.38 |__netdata 06:05:29 PM - 3740 1.94 0.00 |__netdata 06:05:29 PM - 3743 0.97 0.00 |__netdata 06:05:29 PM - 3744 0.97 0.00 |__netdata 06:05:29 PM - 3745 0.97 0.00 |__netdata 06:05:29 PM - 3751 0.97 0.00 |__netdata 06:05:29 PM 3748 - 0.97 0.00 python 06:05:29 PM - 3748 0.97 0.00 |__python 06:05:29 PM - 4020 3.88 6.80 |__python 06:05:29 PM - 4021 3.88 2.91 |__python 06:05:29 PM 7109 - 0.97 52.43 bash 06:05:29 PM - 7109 0.97 52.43 |__bash 06:05:29 PM 9337 - 1.94 0.00 showq 06:05:29 PM - 9337 1.94 0.00 |__showq 06:05:29 PM - 10406 18642.72 45331.07 |__sysbench 06:05:29 PM - 10407 20953.40 42127.18 |__sysbench 06:05:29 PM - 10408 17404.85 44594.17 |__sysbench 06:05:29 PM - 10409 18404.85 45963.11 |__sysbench 06:05:29 PM - 10410 12807.77 61773.79 |__sysbench 06:05:29 PM - 10411 19445.63 38708.74 |__sysbench 06:05:29 PM - 10412 17883.50 40695.15 |__sysbench 06:05:29 PM - 10413 17189.32 49639.81 |__sysbench 06:05:29 PM - 10414 18169.90 45739.81 |__sysbench 06:05:29 PM - 10415 14832.04 47845.63 |__sysbench 06:05:29 PM 10428 - 0.97 96.12 pidstat 06:05:29 PM - 10428 0.97 96.12 |__pidstat 06:05:29 PM - 21200 1.94 0.00 |__grafana-server 06:05:29 PM - 21202 0.97 0.00 |__grafana-server 06:05:29 PM - 21206 1.94 0.00 |__grafana-server 06:05:29 PM - 21209 0.97 0.00 |__grafana-server 06:05:29 PM - 25021 1.94 0.00 |__grafana-server 06:05:29 PM 29194 - 0.97 150.49 apps.plugin 06:05:29 PM - 29194 0.97 150.49 |__apps.plugin
可以看到sysbench进程的上下文切换看起来并不多,但是sysbench的子线程的上下文切换次数却很多,我们发现进程的上下文切换发生很多同时中断次数也上升到将近2万,具体是什么类型的中断上升还需要继续进行监测。
由于中断发生在内核态,而pidstat只是一个进程的性能分析工具,因此他并不能提供任何关于中断的详细信息。因此需要从/proc/interrupts这个只读文件中读取。/proc实际上是Linux的一个虚拟文件系统,用于内核空间与用户空间之间的通信。/proc/interrupts就是这种通信机制的一部分,提供了一个只读的中断使用情况。
[root@localhost ~]# watch -d cat /proc/interrupts [root@localhost ~]# cat /proc/interrupts CPU0 CPU1 CPU2 CPU3 0: 117486 0 0 0 IO-APIC-edge timer 1: 7 0 0 1 IO-APIC-edge i8042 7: 0 0 0 0 IO-APIC-edge parport0 8: 1 0 0 0 IO-APIC-edge rtc0 9: 0 0 0 0 IO-APIC-fasteoi acpi 12: 108 1 0 0 IO-APIC-edge i8042 14: 0 0 0 0 IO-APIC-edge ata_piix 15: 13 17 19 27 IO-APIC-edge ata_piix 17: 3128770 3092486 3307137 3143451 IO-APIC-fasteoi ioc0 24: 0 0 0 0 PCI-MSI-edge pciehp 25: 0 0 0 0 PCI-MSI-edge pciehp 26: 0 0 0 0 PCI-MSI-edge pciehp 27: 0 0 0 0 PCI-MSI-edge pciehp 28: 0 0 0 0 PCI-MSI-edge pciehp 29: 0 0 0 0 PCI-MSI-edge pciehp 30: 0 0 0 0 PCI-MSI-edge pciehp 31: 0 0 0 0 PCI-MSI-edge pciehp 32: 0 0 0 0 PCI-MSI-edge pciehp 33: 0 0 0 0 PCI-MSI-edge pciehp 34: 0 0 0 0 PCI-MSI-edge pciehp 35: 0 0 0 0 PCI-MSI-edge pciehp 36: 0 0 0 0 PCI-MSI-edge pciehp 37: 0 0 0 0 PCI-MSI-edge pciehp 38: 0 0 0 0 PCI-MSI-edge pciehp 39: 0 0 0 0 PCI-MSI-edge pciehp 40: 0 0 0 0 PCI-MSI-edge pciehp 41: 0 0 0 0 PCI-MSI-edge pciehp 42: 0 0 0 0 PCI-MSI-edge pciehp 43: 0 0 0 0 PCI-MSI-edge pciehp 44: 0 0 0 0 PCI-MSI-edge pciehp 45: 0 0 0 0 PCI-MSI-edge pciehp 46: 0 0 0 0 PCI-MSI-edge pciehp 47: 0 0 0 0 PCI-MSI-edge pciehp 48: 0 0 0 0 PCI-MSI-edge pciehp 49: 0 0 0 0 PCI-MSI-edge pciehp 50: 0 0 0 0 PCI-MSI-edge pciehp 51: 0 0 0 0 PCI-MSI-edge pciehp 52: 0 0 0 0 PCI-MSI-edge pciehp 53: 0 0 0 0 PCI-MSI-edge pciehp 54: 0 0 0 0 PCI-MSI-edge pciehp 55: 0 0 0 0 PCI-MSI-edge pciehp 56: 12676123 621337444 15964441 14094017 PCI-MSI-edge eth0-rxtx-0 57: 12934876 27740827 549375875 13481933 PCI-MSI-edge eth0-rxtx-1 58: 12958840 27092299 22935606 555653407 PCI-MSI-edge eth0-rxtx-2 59: 533414281 24804405 22861636 20169043 PCI-MSI-edge eth0-rxtx-3 60: 0 0 0 0 PCI-MSI-edge eth0-event-4 NMI: 0 0 0 0 Non-maskable interrupts LOC: 3073899782 2932109969 2836889656 2806862212 Local timer interrupts SPU: 0 0 0 0 Spurious interrupts PMI: 0 0 0 0 Performance monitoring interrupts IWI: 18 16 18 15 IRQ work interrupts RES: 486603569 505967773 471350449 492621309 Rescheduling interrupts CAL: 75258 1646 73324 1735 Function call interrupts TLB: 33950017 55405448 32837754 52628068 TLB shootdowns TRM: 0 0 0 0 Thermal event interrupts THR: 0 0 0 0 Threshold APIC interrupts MCE: 0 0 0 0 Machine check exceptions MCP: 117332 117332 117332 117332 Machine check polls ERR: 0 MIS: 0
通过观察发现,变化速度最快的是重调度中断RES,这个中断类型表示,唤醒空闲状态的CPU来调度薪的任务运行,这是多处理器系统中,调度器用来分散任务导不同CPU的机制,通常也被称为处理器间中断
所以,这里的中断升高还是因为过多任务的调度问题,跟前面上下文切换次数的分析结果是一致的。
上下文切换正常的数值取决于系统本身的CPU性能。如果系统的上下文切换次数比较稳定,那么从数百到1万以内,都应该算是正常。当上下文切换次数超过一万次,或者切换次数出现数量级的增长时,就很有可能出现了性能问题。
这个时候需要依据上下文切换的类型,在做具体分析:
-
自愿上下文切换变多了,说明进程都在等待自愿,有可能发生了IO等其他问题;
-
非自愿上下文切换变多了,说明进程都在被强制调度,也就是都在争抢CPU,说明CPU的确成了瓶颈;
-
中断次数变多了,说明CPU被中断处理程序占用了,还需要通过查看/proc/interrupts文件来分析具体的中断类型
CPU使用率
Linux作为一个多任务操作系统,将每个CPU的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。
为了维护CPU时间,Linux通过事先定义的节拍率(内核中表示为HZ),触发时间中断,并使用全局变量Jiffies记录了开机以来的节拍数。每发生一次时间中断,Jiffies的值就加1。
节拍率HZ是内核的可配选项,可以配置为100、250、1000等。不同的系统可能设置不同的数值,可以通过查询/boot/config内核选项来查看它的配置(CONFIG_HZ=1000)。比如在我的服务器系统中,节拍率设置成了1000,也就是每秒钟触发1000次时间中断。
[root@localhost ~]# grep 'CONFIG_HZ=' /boot/config-2.6.32-431.el6.x86_64 CONFIG_HZ=1000
正因为节拍率HZ是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率USER_HZ,它总是固定为100,也就是1/100秒。这样,用户空间程序并不需要关心内核中HZ被设置成了多少,因为它看到的总是固定值USER_HZ。
Linux通过/proc虚拟文件系统,向用户空间提供了系统内部状态的信息,而/proc/stat提供的就是系统的CPU和任务统计信息。如果只需要关注CPU,可以执行如下命令:
[root@localhost ~]# cat /proc/stat |grep ^cpu cpu 182993898 729 117810616 13772680802 1631791 13585 2713967 0 0 cpu0 44712915 43 27980485 3442961333 378691 3216 649777 0 0 cpu1 45582701 297 30219438 3442511274 419280 3848 738211 0 0 cpu2 46830450 48 28005111 3445732783 420358 3273 676506 0 0 cpu3 45867831 339 31605580 3441475411 413462 3246 649470 0 0
这里输出结果是一个表格。其中,第一列表示的是CPU编号,如cpu0、cpu1、cpu2、cpu3,而第一行没有编号的cpu,表示的是所有CPU的累加。而其他列表示不同场景下CPU的累加节拍数,她的单位是USER_HZ,也就是10ms(1/100秒),所以这其实就是不同场景下的CPU时间。
-
user(通常缩写为us),代表用户态CPU时间。注意,它不包含下面的nice时间,但包括了gust时间。
-
nice(通常缩写为ni),代表低级优先级用户态CPU时间,也就是进程的nice值被调整为1-19之间的CPU时间,这里注意nice可取值范围是-20到19,数值越大,优先级反而越低。
-
system(通常缩写为sys),代表内核态CPU时间。
-
idle(通常缩写为id),代表空闲时间。注意,它不包括等待IO的时间(iowait)。
-
iowait(通常缩写为wa),代表等待IO的CPU时间。
-
irq(通常缩写为hi),代表处理硬中断的CPU时间。
-
softirq(通常缩写为si),代表处理软中断的CPU时间。
-
steal(通常缩写为st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的CPU时间。
-
guest(通常缩写为guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的CPU时间、
-
guest_nice(通常缩写为gnice),代表低优先级运行虚拟机的时间。
通常所说的CPU使用率,就是除了空闲时间外的其他时间占用CPU时间的百分比,用公式表示就是

根据这个公式,我们就可以从/proc/stat中的数据,很容易地计算出CPU使用率。当然,也可以用每一个场景的CPU时间,除以总的CPU时间,计算出每个场景的CPU使用率。
查看/proc/stat中的数据,显示的是开机以来的节拍数累加值,所以直接算出来的,是开机以来的平均CPU使用率,一般没有什么参考价值。
事实上,为了计算CPU使用率,性能工具一般都会间隔一段时间的两次值,作差后,再计算出这段时间内平均CPU使用率。

这个公式,就是我们用各种性能工具所看到的CPU使用率的实际计算方法。
进程的CPU使用率方法与系统指标类似,Linux也给每个进程提供了运行情况的统计信息,也就是/proc/[pid]/stat。不过,这个文件包含的数据就比较丰富了,总共有52列的数据。
性能分析工具给出的都是间隔一段时间的平均CPU使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证他们用的是相同的间隔时间。
比如,对比一下top和ps这两个工具报告的CPU使用率,默认的结果很可能不一样,因为top默认使用3秒时间间隔,而ps使用的却是进程的整个生命周期。
查看CPU使用率
top和ps是最常用的性能分析工具:
-
top显示了系统总体的CPU和内存使用情况,以及各个进程的资源使用情况。
-
ps则只显示了每个进程的资源使用情况。
关于top命令使用见下图详解
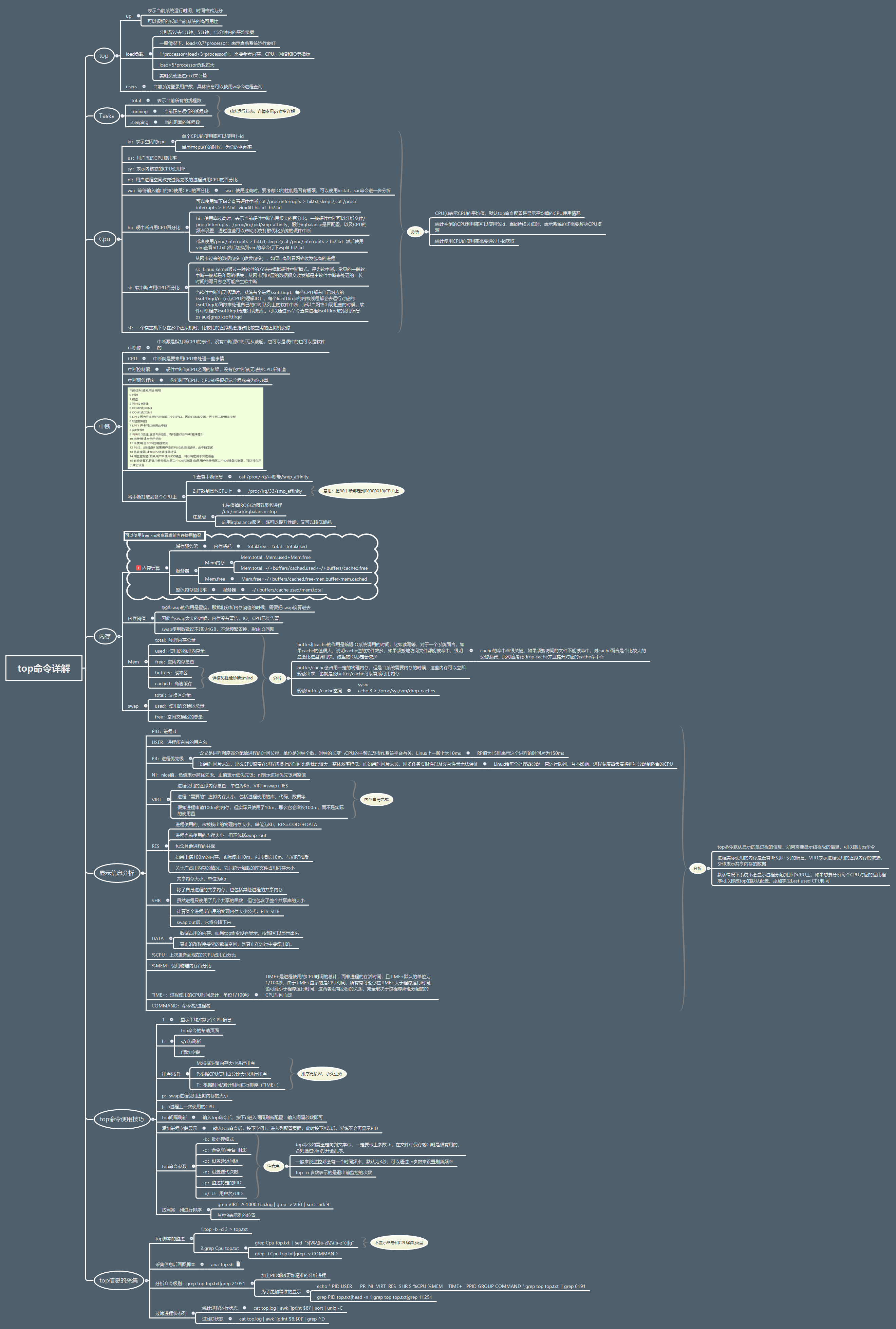
top命令每个进程都有一个%CPU列,表示进程的CPU使用率。它是用户态和内核态CPU使用率的总和,包括进程用户空间使用的CPU、通过系统调用执行的内核空间CPU、以及在就绪队列等待运行的CPU。在虚拟化环境中,它还包括了运行虚拟机占用的CPU,可以发现top命令并没有细分进程的用户态CPU和内核态CPU。
如果想要查看进程CPU使用率的具体情况需要使用pidstat命令来进行观测;
[root@localhost ~]# pidstat 1 5 Linux 2.6.32-431.el6.x86_64 (localhost.localdomain) 04/30/2020 _x86_64_ (4 CPU) 02:29:12 PM PID %usr %system %guest %CPU CPU Command 02:29:13 PM 14734 0.00 0.98 0.00 0.98 3 apps.plugin 02:29:13 PM 29918 0.98 0.98 0.00 1.96 1 pidstat 02:29:13 PM PID %usr %system %guest %CPU CPU Command 02:29:14 PM 3360 0.00 1.00 0.00 1.00 0 redis-server 02:29:14 PM 3723 1.00 0.00 0.00 1.00 0 netdata 02:29:14 PM 14734 1.00 0.00 0.00 1.00 3 apps.plugin 02:29:14 PM 21198 1.00 0.00 0.00 1.00 1 grafana-server 02:29:14 PM 29167 0.00 1.00 0.00 1.00 2 bash 02:29:14 PM 29918 0.00 1.00 0.00 1.00 1 pidstat 02:29:14 PM PID %usr %system %guest %CPU CPU Command 02:29:15 PM 3748 1.00 0.00 0.00 1.00 0 python 02:29:15 PM 14734 0.00 1.00 0.00 1.00 3 apps.plugin 02:29:15 PM 29918 0.00 1.00 0.00 1.00 1 pidstat 02:29:15 PM PID %usr %system %guest %CPU CPU Command 02:29:16 PM 3723 1.00 0.00 0.00 1.00 0 netdata 02:29:16 PM 14734 0.00 1.00 0.00 1.00 3 apps.plugin 02:29:16 PM 21198 0.00 1.00 0.00 1.00 1 grafana-server 02:29:16 PM 29167 1.00 0.00 0.00 1.00 1 bash 02:29:16 PM 29918 1.00 0.00 0.00 1.00 1 pidstat 02:29:16 PM PID %usr %system %guest %CPU CPU Command 02:29:17 PM 3360 1.00 0.00 0.00 1.00 0 redis-server 02:29:17 PM 3723 1.00 1.00 0.00 2.00 0 netdata 02:29:17 PM 14734 1.00 0.00 0.00 1.00 3 apps.plugin 02:29:17 PM 29918 0.00 1.00 0.00 1.00 1 pidstat Average: PID %usr %system %guest %CPU CPU Command Average: 3360 0.20 0.20 0.00 0.40 - redis-server Average: 3723 0.60 0.20 0.00 0.80 - netdata Average: 3748 0.20 0.00 0.00 0.20 - python Average: 14734 0.40 0.60 0.00 1.00 - apps.plugin Average: 21198 0.20 0.20 0.00 0.40 - grafana-server Average: 29167 0.20 0.20 0.00 0.40 - bash Average: 29918 0.40 0.80 0.00 1.20 - pidstat
如上面的pidstat命令,就间隔1秒展示了进程的5组CPU使用率,包括
-
用户态CPU使用率(%usr)
-
内核态CPU使用率(%system);
-
运行虚拟机CPU使用率(%guest);
-
等待CPU使用率(%wait);
-
以及总的CPU使用率(%CPU)
最后Average部分,还计算了5组数据的平均值。
CPU使用率分析
perf是Linux2.6.31以后内置的性能分析工具,它以性能时间采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。
[root@localhost ~]# perf top Samples: 11K of event 'cpu-clock', Event count (approx.):1015 Overhead Shared Object Symbol 9.42% [kernel] [k] kallsyms_expand_symbol 7.03% perf [.] symbols__insert 6.37% perf [.] rb_next 4.51% [kernel] [k] vsnprintf 4.11% [kernel] [k] format_decode 3.71% [kernel] [k] number 3.45% [kernel] [k] strnlen 2.79% [kernel] [k] string 2.52% perf [.] hex2u64 2.12% libc-2.14.so [.] __strcmp_sse42 1.99% libc-2.14.so [.] __memcpy_sse2 1.86% libc-2.14.so [.] _int_malloc 1.59% libc-2.14.so [.] _IO_getdelim 1.59% libc-2.14.so [.] __strchr_sse42 1.46% libc-2.14.so [.] __libc_calloc 1.33% libc-2.14.so [.] __strstr_sse42 1.19% [kernel] [k] get_task_cred 1.19% [kernel] [k] update_iter 1.06% [kernel] [k] module_get_kallsym 1.06% libpthread-2.14.so [.] pthread_rwlock_rdlock
输出结果中,第一行包含三个数据,分别是采样数(Sample)、事件类型(event)和事件总数量(Event count)。例子中,pref总共采集了11K个CPU时钟事件,需要注意如果采样数过少,那下面的排序和百分比就没什么实际参考价值。
-
第一列Overhead,是该符号的性能事情在所有采用中的比例,用百分比来表示。
-
第二列Shared,是该函数或指令所在的动态共享对象,如内核、进程名、动态链接库名、内核模块名等。
-
第三列Object,是动态共享对象的类型。比如[.]表示用户空间的可执行程序、或者动态链接库,而[k]则表示内核空间。
-
最后一列Symbol是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
从上面数据,可以看到,占用CPU时钟最多的是kernel(内核),不过它的比例也只有9.42%,说明系统并没有CPU性能问题。
系统进程分析
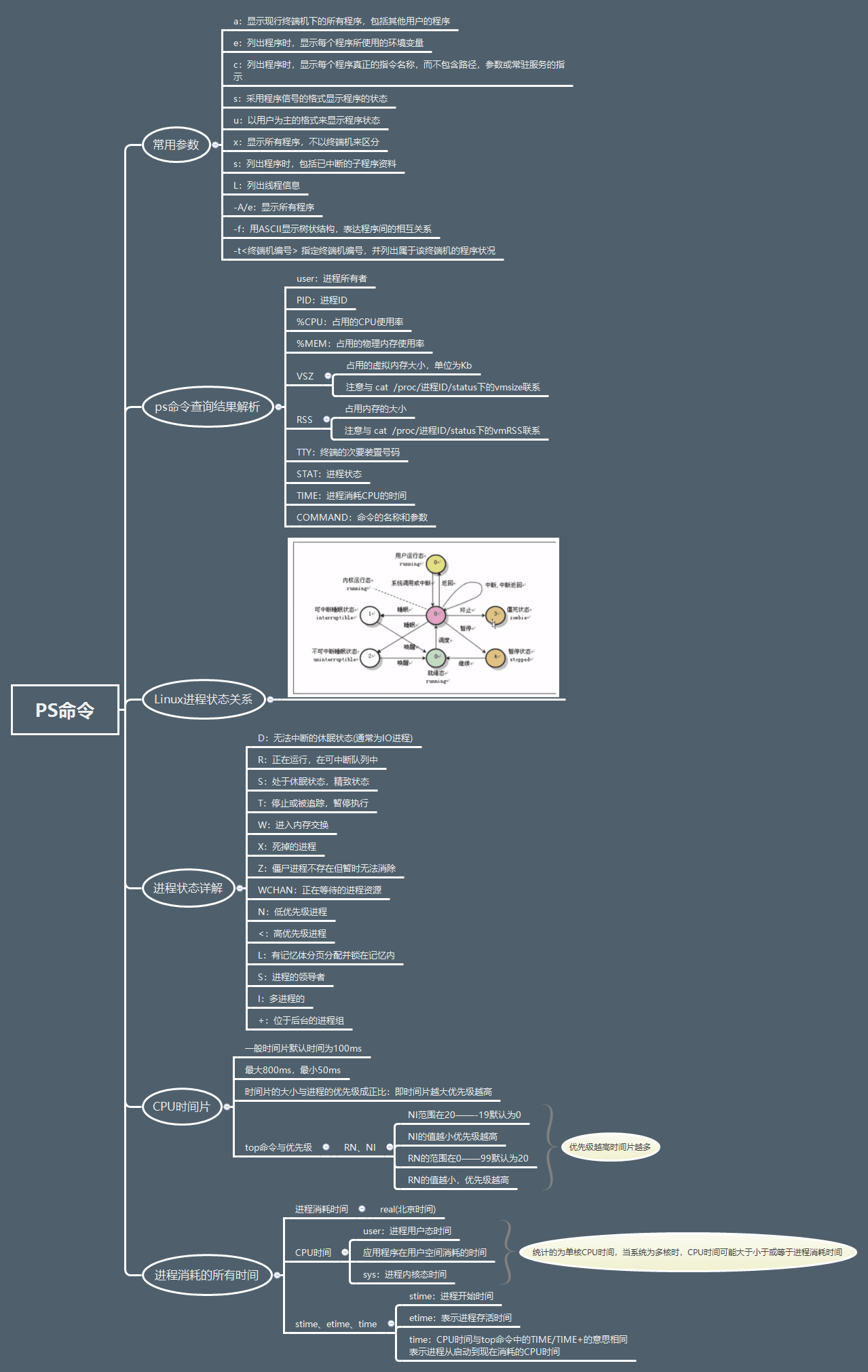
参考ps命令详解,这里不再多说