一直对爬虫感兴趣,学了python后正好看到某篇关于爬取的文章,就心血来潮实战一把吧。
实现目标:抓取豆瓣电影top250,并输出到文件中
1.找到对应的url:https://movie.douban.com/top250
2.进行页面元素的抓取:
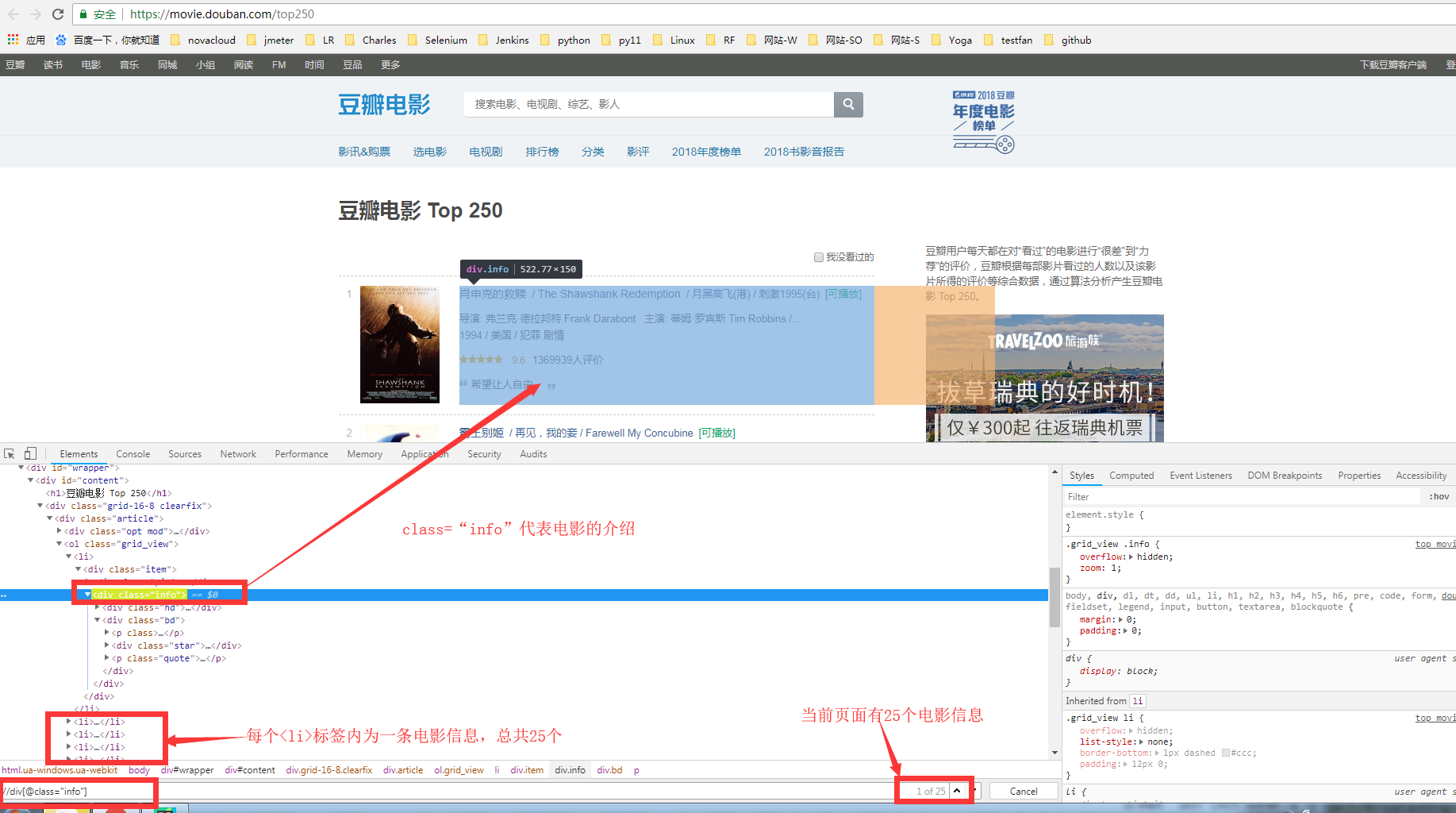
3.编写代码思路:
第一步:实现抓取第一个页面;
第二步:将其他页面的信息也抓取到;
第三步:输出到文件;
4.具体代码实现:
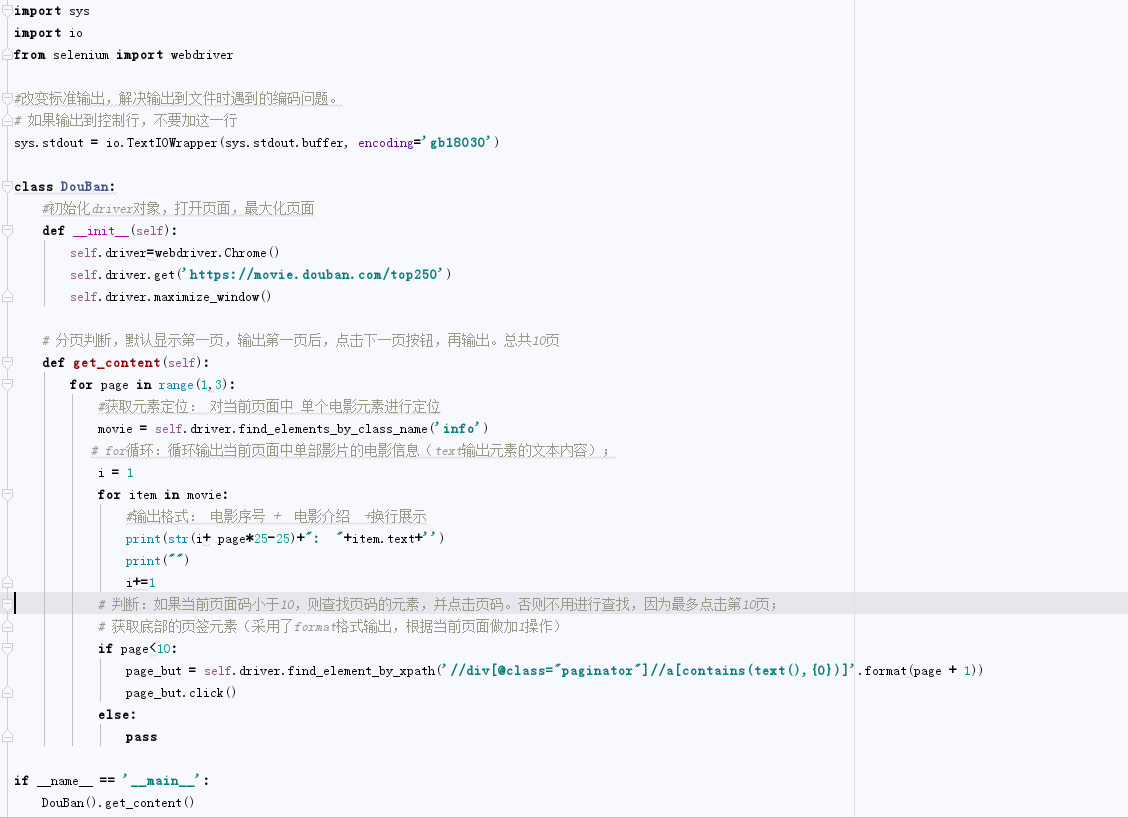
5.结果:
1)控制台输出部分截图:

2)如果想要输出到文件,执行命令并重定向到TXT文件中:
python xxxx.py >d:/out_test.txt
6.遇到的问题:
1.多页时,for循环的数字设置,来回试几次就可以了,不难。
2.输出到文件中(参照博客:https://www.cnblogs.com/feng18/p/5646925.html,讲的比较详细)

真的很简单,有问题留言问我吧~