1 EventTime的引入
在Flink的流式处理中,绝大部分的业务都会使用eventTime,一般只在eventTime无法使用时,才会被迫使用ProcessingTime或者IngestionTime。
如果要使用EventTime,那么需要引入EventTime的时间属性,引入方式如下所示:
val env = StreamExecutionEnvironment.getExecutionEnvironment // 从调用时刻开始给env创建的每一个stream追加时间特征 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
2 Watermark
2.1 基本概念
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
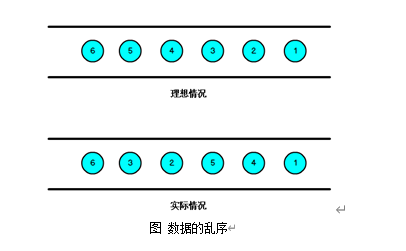
那么此时出现一个问题,一旦出现乱序,如果只根据eventTime决定window的运行,我们不能明确数据是否全部到位,但又不能无限期的等下去,此时必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了,这个特别的机制,就是Watermark。
Watermark是一种衡量Event Time进展的机制,它是数据本身的一个隐藏属性,数据本身携带着对应的Watermark。
Watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用Watermark机制结合window来实现。
数据流中的Watermark用于表示timestamp小于Watermark的数据,都已经到达了,因此,window的执行也是由Watermark触发的。
Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延时时长t,每次系统会校验已经到达的数据中最大的maxEventTime,然后认定eventTime小于maxEventTime - t的所有数据都已经到达,如果有窗口的停止时间等于maxEventTime – t,那么这个窗口被触发执行。
有序流的Watermarker如下图所示:(Watermark设置为0)

乱序流的Watermarker如下图所示:(Watermark设置为2)

当Flink接收到每一条数据时,都会产生一条Watermark,这条Watermark就等于当前所有到达数据中的maxEventTime - 延迟时长,也就是说,Watermark是由数据携带的,一旦数据携带的Watermark比当前未触发的窗口的停止时间要晚,那么就会触发相应窗口的执行。由于Watermark是由数据携带的,因此,如果运行过程中无法获取新的数据,那么没有被触发的窗口将永远都不被触发。
上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为7s的事件对应的Watermark是5s,时间戳为12s的事件的Watermark是10s,如果我们的窗口1是1s~5s,窗口2是6s~10s,那么时间戳为7s的事件到达时的Watermarker恰好触发窗口1,时间戳为12s的事件到达时的Watermark恰好触发窗口2。
Watermark 就是触发前一窗口的“关窗时间”,一旦触发关门那么以当前时刻为准在窗口范围内的所有所有数据都会收入窗中。
只要没有达到水位那么不管现实中的时间推进了多久都不会触发关窗。
2.2 Watermark的引入
val textWithEventTimeDstream: DataStream[(String, Long, Int)] = textWithTsDstream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(1000)) {
override def extractTimestamp(element: (String, Long, Int)): Long = {
return element._2
}
})
7.3 EvnetTimeWindow API
3.1 滚动窗口(TumblingEventTimeWindows)
def main(args: Array[String]): Unit = {
// 环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val dstream: DataStream[String] = env.socketTextStream("hadoop1",7777)
val textWithTsDstream: DataStream[(String, Long, Int)] = dstream.map { text =>
val arr: Array[String] = text.split(" ")
(arr(0), arr(1).toLong, 1)
}
val textWithEventTimeDstream: DataStream[(String, Long, Int)] = textWithTsDstream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(1000)) {
override def extractTimestamp(element: (String, Long, Int)): Long = {
return element._2
}
})
val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDstream.keyBy(0)
textKeyStream.print("textkey:")
val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(TumblingEventTimeWindows.of(Time.seconds(2)))
val groupDstream: DataStream[mutable.HashSet[Long]] = windowStream.fold(new mutable.HashSet[Long]()) { case (set, (key, ts, count)) =>
set += ts
}
groupDstream.print("window::::").setParallelism(1)
env.execute()
}
}
结果是按照Event Time的时间窗口计算得出的,而无关系统的时间(包括输入的快慢)。
3.2 滑动窗口(SlidingEventTimeWindows)
def main(args: Array[String]): Unit = { // 环境 val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val dstream: DataStream[String] = env.socketTextStream("hadoop1",7777) val textWithTsDstream: DataStream[(String, Long, Int)] = dstream.map { text => val arr: Array[String] = text.split(" ") (arr(0), arr(1).toLong, 1) } val textWithEventTimeDstream: DataStream[(String, Long, Int)] = textWithTsDstream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(1000)) { override def extractTimestamp(element: (String, Long, Int)): Long = { return element._2 } }) val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDstream.keyBy(0) textKeyStream.print("textkey:") val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(SlidingEventTimeWindows.of(Time.seconds(2),Time.milliseconds(500))) val groupDstream: DataStream[mutable.HashSet[Long]] = windowStream.fold(new mutable.HashSet[Long]()) { case (set, (key, ts, count)) => set += ts } groupDstream.print("window::::").setParallelism(1) env.execute() }
3.3 会话窗口(EventTimeSessionWindows)
相邻两次数据的EventTime的时间差超过指定的时间间隔就会触发执行。如果加入Watermark, 会在符合窗口触发的情况下进行延迟。到达延迟水位再进行窗口触发。
def main(args: Array[String]): Unit = {
// 环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val dstream: DataStream[String] = env.socketTextStream("hadoop1",7777)
val textWithTsDstream: DataStream[(String, Long, Int)] = dstream.map { text =>
val arr: Array[String] = text.split(" ")
(arr(0), arr(1).toLong, 1)
}
val textWithEventTimeDstream: DataStream[(String, Long, Int)] = textWithTsDstream.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor[(String, Long, Int)](Time.milliseconds(1000)) {
override def extractTimestamp(element: (String, Long, Int)): Long = {
return element._2
}
})
val textKeyStream: KeyedStream[(String, Long, Int), Tuple] = textWithEventTimeDstream.keyBy(0)
textKeyStream.print("textkey:")
val windowStream: WindowedStream[(String, Long, Int), Tuple, TimeWindow] = textKeyStream.window(EventTimeSessionWindows.withGap(Time.milliseconds(500)) )
windowStream.reduce((text1,text2)=>
( text1._1,0L,text1._3+text2._3)
) .map(_._3).print("windows:::").setParallelism(1)
env.execute()
}