原文链接:http://tecdat.cn/?p=6181
Word Mover的距离(WMD)是用于衡量两个文档之间差异的距离度量,它在文本分析中的应用是由华盛顿大学的一个研究小组在2015年引入的。
Word Mover距离的定义
WMD是两个文档之间的距离,作为将所有单词从一个文档移动到另一个文档所需的最小(加权)累积成本。通过解决以下线性程序问题来计算距离。
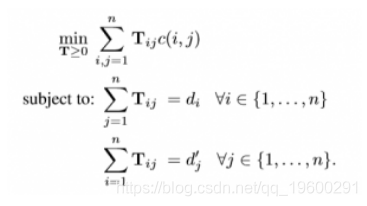
![]()
T ij表示文档d中的单词i在文档d'中移动到单词j的多少;
C(1; j)的表示从文件d中的单词我到文件d '中的单词J‘行进’的费用; 这里的成本是word2vec嵌入空间中的两个词'欧几里德距离;
如果字我出现Ç我在文档d次,我们记
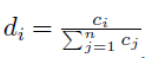
![]()
WMD是地球移动器距离度量(EMD)的一个特例,这是一个众所周知的运输问题。
如何用SAS计算地球移动的距离?
SAS / OR是解决运输问题的工具。图1显示了一个带有四个节点和节点之间距离的传输示例,我从这个Earth Mover的距离文档中复制了这些节点。目标是找出从{x1 ,x2}到{y1,y2}的最小流量。现在让我们看看如何使用SAS / OR解决这个运输问题。
节点的权重和节点之间的距离如下。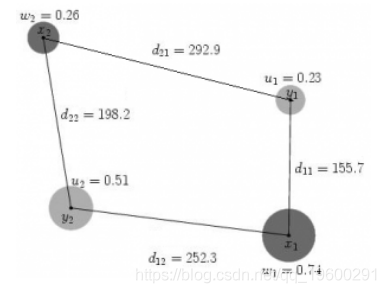
![]()
图-1运输问题
datax_set;input_node_ $ _sd_;datalines;x10.74x20.26;datay_set;input_node_ $ _sd_;datalines;y10.23y20.51;dataarcdata;input_tail_ $ _head_ $ _cost_;datalines;x1 y1155.7x1 y2252.3x2 y1292.9x2 y2198.2;proc optmodel;setxNODES;num w{xNODES};setyNODES;num u{yNODES};set<str,str> ARCS;num arcCost{ARCS}; readdatax_setintoxNODES=[_node_]w=_sd_;readdatay_setintoyNODES=[_node_]u=_sd_;readdataarcdataintoARCS=[_tail_ _head_]arcCost=_cost_;varflow{<i,j>inARCS}>=0;impvar sumY =sum{jinyNODES}u[j];minobj =(sum{<i,j>inARCS}arcCost[i,j]* flow[i,j])/sumY;con con_y{jinyNODES}:sum{<i,(j)>inARCS}flow[i,j]= u[j];con con_x{iinxNODES}:sum{<(i),j>inARCS}flow[i,j]<= w[i]; solve with lp / algorithm=ns scale=none logfreq=1;print flow;quit; SAS / OR的解决方案如表-1所示,EMD是目标值:203.26756757。
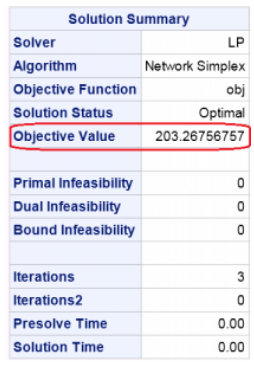
![]()
表-1 EMD用SAS / OR计算
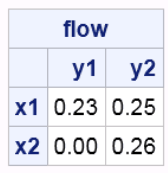
我用SAS / OR表2得到的流量数据显示如下,与上述地球移动器距离文档中公布的图表相同。
![]()
表-2 SAS / OR的流量数据
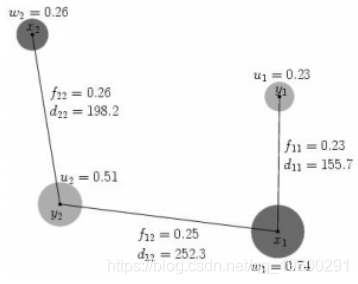
![]()
图-2运输问题流程图
如何用SAS计算Word Mover的距离
本文从Word嵌入到文档距离,通过删除WMD的第二个约束来减少计算,提出了一个名为放松的Word Mover距离(RWMD)的新度量。由于我们需要读取文字嵌入数据,因此我将向您展示如何使用SAS Viya计算两个文档的RWMD。
/* start CAS server */cas casauto host="host.example.com"port=5570;libnamesascas1 cas;/* load documents into CAS */datasascas1.documents;infiledatalines delimiter='|'missover;lengthtext varchar(300);inputtext$ did;datalines;Obama speaks to the mediainIllinois.|1The President greets the pressinChicago.|2;run;/* create stop list*/datasascas1.stopList;infiledatalines missover;lengthterm $20;inputterm$;datalines;thetoin;run;/* load word embedding model */proc cas;loadtable path='datasources/glove_100d_tab_clean.txt'caslib="CASTestTmp"importOptions={fileType="delimited",delimiter=' ',getNames=True,guessRows=2.0,varChars=True}casOut={name='glove'replace=True};run;quit;%macrocalculateRWMD(textDS=documents,documentID=did,text=text,language=English,stopList=stopList,word2VectDS=glove,doc1_id=1,doc2_id=2);/* text parsing and aggregation */proc cas;textParse.tpParse/table={name="&textDS",where="&documentID=&doc1_id or &documentID=&doc2_id"}docId="&documentID",language="&language",stemming=False,nounGroups=False,tagging=False,offset={name="outpos",replace=1},text="&text";run; textparse.tpaccumulate/parent={name="outparent1",replace=1}language="&language",offset='outpos',stopList={name="&stoplist"},terms={name="outterms1",replace=1},child={name="outchild1",replace=1},reduce=1,cellweight='none',termWeight='none';run;quit;/* terms of the two test documents */proc cas;loadactionset"fedsql";execdirect casout={name="doc_terms",replace=true}query="
select outparent1.*,_term_
from outparent1
left join outterms1
on outparent1._termnum_ = outterms1._termnum_
where _Document_=&doc1_id or _Document_=&doc2_id;
";run;quit;/* term vectors and counts of the two test documents */proc cas;loadactionset"fedsql";execdirect casout={name="doc1_termvects",replace=true}query="
select word2vect.*
from &word2VectDS word2vect, doc_terms
where _Document_=&doc2_id and lowcase(term) = _term_;
";run; execdirect casout={name="doc1_terms",replace=true}query="
select doc_terms.*
from &word2VectDS, doc_terms
where _Document_=&doc2_id and lowcase(term) = _term_;
";run; simple.groupBy /table={name="doc1_terms"}inputs={"_Term_","_Count_"}aggregator="n"casout={name="doc1_termcount",replace=true};run;quit;proc cas;loadactionset"fedsql";execdirect casout={name="doc2_termvects",replace=true}query="
select word2vect.*
from &word2VectDS word2vect, doc_terms
where _Document_=&doc1_id and lowcase(term) = _term_;
";run; execdirect casout={name="doc2_terms",replace=true}query="
select doc_terms.*
from &word2VectDS, doc_terms
where _Document_=&doc1_id and lowcase(term) = _term_;
";run; simple.groupBy /table={name="doc2_terms"}inputs={"_Term_","_Count_"}aggregator="n"casout={name="doc2_termcount",replace=true};run;quit;/* calculate Euclidean distance between words */datadoc1_termvects;setsascas1.doc1_termvects;run;datadoc2_termvects;setsascas1.doc2_termvects;run;proc iml;use doc1_termvects;read allvar_char_intolterm;read allvar_num_intox;closedoc1_termvects; use doc2_termvects;read allvar_char_intorterm;read allvar_num_intoy;closedoc2_termvects; d = distance(x,y); lobs=nrow(lterm);robs=nrow(rterm);d_out=j(lobs*robs, 3, ' ');doi=1to lobs;doj=1to robs;d_out[(i-1)*robs+j,1]=lterm[i];d_out[(i-1)*robs+j,2]=rterm[j];d_out[(i-1)*robs+j,3]=cats(d[i,j]);end;end;createdistancefromd_out;appendfromd_out;closedistance;run;quit;/* calculate RWMD between documents */datax_set;setsascas1.doc1_termcount;rename_term_=_node_;_weight_=_count_;run;datay_set;setsascas1.doc2_termcount;rename_term_=_node_;_weight_=_count_;run;dataarcdata;setdistance;renamecol1=_tail_;renamecol2=_head_;length_cost_8;_cost_= col3;run;proc optmodel;setxNODES;num w{xNODES};setyNODES;num u{yNODES};set<str,str> ARCS;num arcCost{ARCS}; readdatax_setintoxNODES=[_node_]w=_weight_;readdatay_setintoyNODES=[_node_]u=_weight_;readdataarcdataintoARCS=[_tail_ _head_]arcCost=_cost_;varflow{<i,j>inARCS}>=0;impvar sumY =sum{jinyNODES}u[j];minobj =(sum{<i,j>inARCS}arcCost[i,j]* flow[i,j])/sumY;con con_y{jinyNODES}:sum{<i,(j)>inARCS}flow[i,j]= u[j];/* con con_x {i in xNODES}: sum {<(i),j> in ARCS} flow[i,j] <= w[i];*/solve with lp / algorithm=ns scale=none logfreq=1;callsymput('obj', strip(put(obj,best.)));createdataflowDatafrom[i j]={<i, j="">inARCS: flow[i,j].sol >0}col("cost")=arcCost[i,j]col("flowweight")=flow[i,j].sol;run;quit;%putRWMD=&obj;%mendcalculateRWMD; %calculateRWMD(textDS=documents,documentID=did,text=text,language=English,stopList=stopList,word2VectDS=glove,doc1_id=1,doc2_id=2);
<str,str>
<str,str>proc printdata=flowdata;run;quit;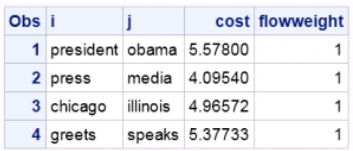
![]()
WMD方法不仅可以测量文档的相似性,还可以通过可视化流数据来解释为什么这两个文档是相似的。