全文链接:http://tecdat.cn/?p=28031
原文出处:拓端数据部落公众号
作者:Yuling Zhang
运用Python 3.8.1版本,爬取网络数据,基于卷积神经网络(CNN)的图像处理原理,搭建口罩识别技术训练集,构建人脸识别系统,最终建立高校师生行踪查询管理系统。
数据来源及环境准备
通过网络搜集,得到3073张不同性别、年龄以及不同场景中的人佩戴口罩的照片,而未佩戴口罩的人脸图片从中选取了3249张图片。以此作为本次研究的数据集,通过对数据集进行预处理,来训练人脸口罩检测的模型。
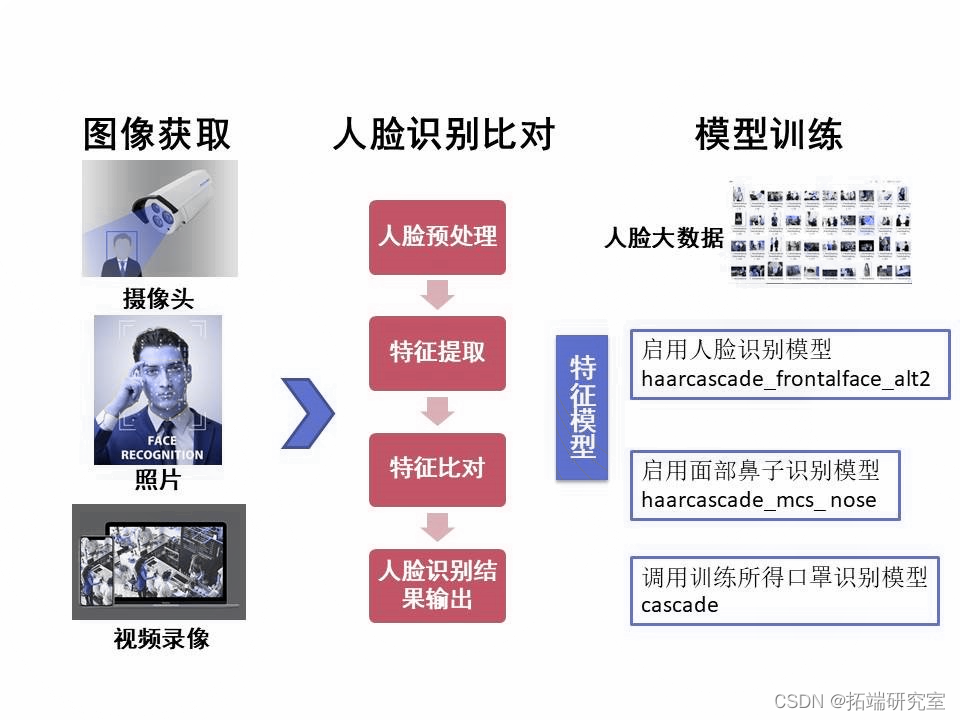 二、确定人脸及口罩识别整体操作流程
二、确定人脸及口罩识别整体操作流程
图1
具体流程
(1)对数据集中的人脸进行检测和对齐
由于有的照片中脸和口罩的比例比较小,其他部位比如手、肩膀等占据了很大的空间,这些对于模型来说都是噪音,会增加CPU的计算量并且会干扰模型。所以我们需要对获取到的照片进行处理,将人脸裁剪出来。我们利用OpenCv和dlib对数据集进行了人脸的检测和对齐,以便后续对模型进行训练。人脸检测是指将一张图片中的人脸圈出来,即找到人脸所处的位置,人脸对齐则是基于已经检测到的人脸,自动找到脸轮廓和眼睛鼻子嘴等标志性特征位置。我们使用dlib对数据集进行了人脸68个特征点的检测,并将人脸进行对齐,最后将每张照片上的人脸数和对齐的人脸数打印出来。

图2 检测人脸68个特征点

图3 人脸数及对齐人脸数
因为识别有一定的误差,所以需要对裁剪后的照片进行筛选,将极少数对齐不准确的照片手动删除,并将数据集的照片进行重命名,便于后续数据集路径的创建。最后得到戴口罩的照片1010张,作为该模型的正样本,未戴口罩的照片3030张,作为该模型的负样本,正负样本的比例为1:3。
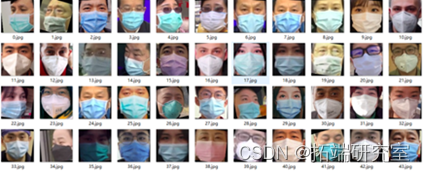

图4 裁剪后的正负样本集
(2)正负样本数据集灰度处理及像素处理
对数据集进行灰度处理可以增强图像对比度,增大图片的动态范围,让图像更清晰,特征更明显,能够更好的对模型进行训练。除此之外,还需要将正负样本各自的照片像素设为相同的值,正样本数据集的像素最佳设为20x20,这样的模型训练精度更高,而负样本数据集像素则应不低于50x50,如此可以加快模型训练的速度,此处我们将负样本的数据集像素调节为80 x80。最后通过cmd命令分别生成佩戴有口罩和未佩戴口罩的图片路径的txt文件。


图5 灰度、像素处理后的正负样本
训练级联分类器时使用的是opencv3.4.1版中的opencv_createsamples.exe和opencv_traincascade.exe两个程序。opencv_traincascade 支持不仅支持 Haar特征也支持 LBP特征,同时还可以增强其他的特征。在检测时上述两种特征的准确率都依赖于训练时的训练参数以及训练数据的质量。此次我们在训练口罩识别模型时提取了Haar特征,其最主要的优势在于它的计算较为迅速。可以用opencv_createsamples来准备用于训练的测试数据和正样本数据, 这些数据能够被opencv_traincascade 程序支持。
在测试时,我们还加入了对人脸鼻子的识别,即当识别到人脸时若还识别到鼻子,则显示为未佩戴口罩,能够更加有效地对口罩佩戴是否规范。

图6 口罩识别系统实践效果图
(4)口罩识别训练模型评价
训练集运行结果如下:
-
===== TRAINING 4-stage =====
-
<BEGIN
-
POS count : consumed 800 : 813
-
NEG count : acceptanceRatio 2600 : 0.00584079
-
Precalculation time: 25.945
如图所示,执行该命令时,一些参数信息被终端首先输出。然后输出级联分类器中每级强分类器的训练信息,我们设置的numStages为10,于是一共有10个强分类器:0-stage至9-stage。图中是第4级强分类器的信息。我们分别分析这些信息如下所示:
-
===== TRAINING 4-stage =====
-
-
<BEGIN
表示开始训练第4级强分类器。
【POS count : consumed800: 813】在训练本级强分类器时,能够使用的800个正样本图像是从813个正样本图像集中选取出来的,说明此时没有被识别出来的正样本有13个。此时的识别率为98.4%(800/813=0.984).
【NEG count : acceptanceRatio 2600 : 0.00584079】可用2600个负样本图像训练本级强分类器,该数是opencv_traincascade.exe命令中参数numNeg指定的数量,后面的0.00584079表示当前级联分类器预测的这些被预测为正样本而实际为负样本的2600幅图像是从多少个负样本图像中得到的。当前已得到了4个强分类器:O-stage、1-stage、2-stage、3-stage。当即将训练的第5个强分类器4-stage运行结束后,这5个强分类器构成的级联分类器的最大错误率为:0.25x0.25x0.25x0.25=0.000976,已经满足了要求,无需继续训练,系统会停止运行。
【Precalculation time: 25.945】这表示,在没有构建强分类器之前,我们计算好了一部分特征值,这时预先计算的特征值所消耗的时间。该值由opencv_traincascade.exe命令中的参数precalcValBufSize和precalcldxBufSize决定,如果我们在此设置了更大的内存,就能存储更多特征值,与此同时所花费的时间就越长。
表示此时该级的强分类器已经得到,因为识别率和错误率都满足了要求,所以此级强分类器的训练结束。
【Training until now has taken 0 days 0 hours 39 minutes 53 seconds】表示到目前为止,训练级联分类器共用时39分53秒。此时,就训练得到了我们需要的级联分类器数据,我们利用它就可以识别出人脸。
本项目的主要工作可以概括为以下几点:
一、基于卷积神经网络的人脸识别。达到以下效果:
1、从视频中识别人脸,并实时标出面部特征点。2、建cv2摄像头对象,我们使用电脑自带摄像头(若安装外部摄像头,则自动切换到外部摄像头)。3、针对高清视频的多帧连续对照识别、对监控设备的视频数据进行解码,并分离数据帧、形成每帧视频的图像数据,从而将人脸识别率呈指数级大幅提升。4、设置每帧数据延时为1ms,使用人脸检测器检测每一帧图像中的人脸做灰度处理,并输出人脸数。5、对每个人脸定位画出方框,显示识别结果。6、添加快捷功能并在识别页面添加按键说明:按下s键截图保存,按下q键退出。
二、口罩识别
基于卷积神经网络的口罩识别。对于检测到的三类情况:①戴口罩(捂住口鼻)②戴口罩(未捂住口鼻)③未戴口罩做出了no mask ;no mask; have mask的判断。
三、搭建了师生端疫情防控平台,实时查询个人进出校内公共场所及进出校内外情况。提供了一个核查与监督的平台。
关于作者

在此对Yuling Zhang对本文所作的贡献表示诚挚感谢,她专长深度学习、数据采集、回归预测。

最受欢迎的见解
3.python用遗传算法-神经网络-模糊逻辑控制算法对乐透分析
4.R语言结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
5.Python TensorFlow循环神经网络RNN-LSTM神经网络预测股票市场价格时间序列和MSE评估准确性
6.Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
7.用于NLP的seq2seq模型实例用Keras实现神经机器翻译
8.R语言用FNN-LSTM假近邻长短期记忆人工神经网络模型进行时间序列深度学习预测
9.Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID-19新冠疫情新增人数时间序列预测