原文链接: http://tecdat.cn/?p=24647
原文出处:拓端数据部落公众号
背景和定义
线性混合模型假设 N 个受试者的群体是同质的,并且在群体水平上由独特的曲线 Xi(t)β 描述。相比之下,潜在类别混合模型在于假设人口是异质的,并且由 G 潜在类别的受试者组成,其特征是 G 平均轨迹曲线。
潜类别混合模型
潜在类别成员由离散随机变量 ci 定义,如果主题 i 属于潜在类别 g (g = 1, …,G),则该变量等于 g。变量 ci 是潜在的;根据协变量 Xci 使用多项逻辑模型描述其概率:
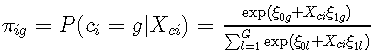
其中 ξ0g 是 g 类的截距,ξ1g 是与时间无关协变量 Xci 的 q1 向量相关的类特定参数的 q1 向量。当没有协变量预测潜在类成员资格时,该模型将简化为特定于类的概率。
对于连续和高斯变量,Y 的轨迹通过线性混合模型有条件地定义为潜在类。因此,以类 g 为条件,在 j 时为主题 i 定义模型:
![]()
其中 X2ij、X3ij 和 Zij 是协变量的向量,它们分别与类 β 上的常见固定效应、特定于类的固定效应 γg 以及称为 big 的单个随机效应 bi|ci=g 相关,其分布现在是特定于类的。X2 和 X3 不能有公共变量。
后验分类
在涉及潜在类别的模型中,可以对每个潜在类别中的主体进行后验分类。它基于类成员概率的后验计算,用于表征对象的分类以及评估模型的拟合优度(Proust-Lima et al. 2014 ).
使用贝叶斯定理计算后类成员概率作为给定收集信息的潜在类的概率。在纵向模型中,它们为主题 ii 和潜在类别 g 定义为:
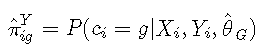
其中: θ^G 是 G 潜在类模型中估计的参数向量。
高斯数据示例
在这个例子中,我们研究了一个认知指标的二次方轨迹,简易智能量表评分(MMSE)预先规范化(具有高斯分布),在对老年人(纳入时年龄在65岁及以上)的样本进行了长达15年的跟踪,并对教育水平进行了调整。该模型在此不考虑交互作用,尽管可以考虑任何回归。
数据集
子样本
这是来自原始前瞻性研究 的 500 名受试者的子样本。该数据集不能用于流行病学目的,因为子样本不代表原始队列(特别是痴呆病例已被过度采样)。
数据采用纵向格式,包括一些变量,例如 3 项心理测量测试 MMSE、BVRT、IST、抑郁症状量表 和变量 年龄、痴呆前的年龄、是否痴呆、教育水平和是否男性。
用于可视化数据(仅限表头):
head(data)

在不同的时间收集不同的标记。在数据集中,时间尺度是年龄。
获取数据的快速摘要:
-
-
-
summary(data)
-
-
-
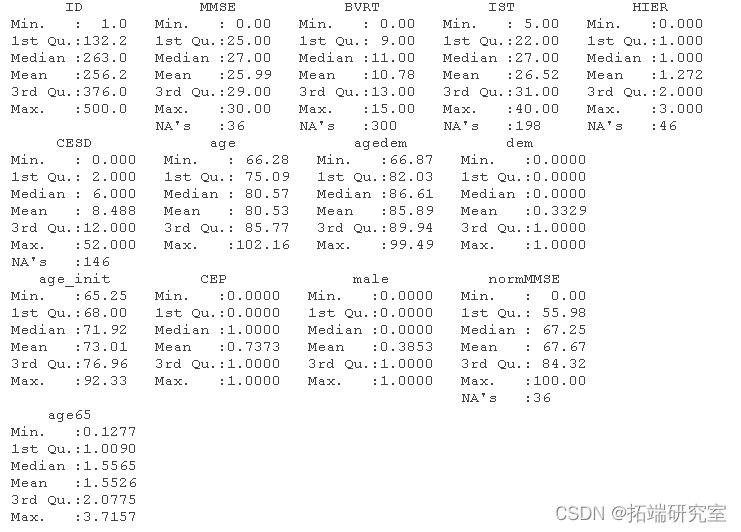
一些变量有缺失值。
简易智能量表评分结果
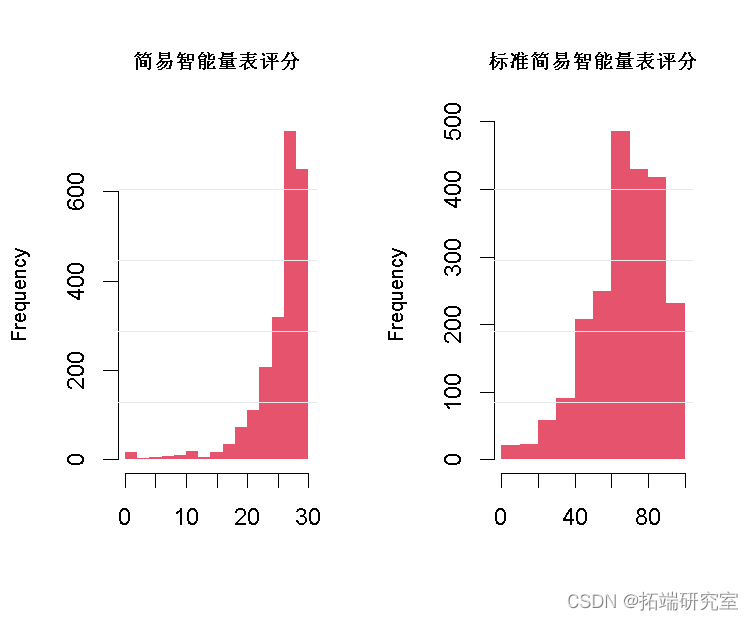
简易智能量表评分通常被视为结果。简易智能量表评分是一种非常常见的神经心理学测试,用于测量老年人的整体认知功能。它具有非常不对称的分布,因此通常将其归一化以应用于高斯变量的方法。预归一化函数完成的:
-
-
hist( MMSE )
-
-
hist( norm )
-
-
-
要建模单个重复测量是:
-
-
-
color <-ID
-
-
xyplot
-
-
-
考虑的模型
我们考虑以下潜在类线性混合模型,其中 g 表示类别,i表示主题,j 表示重复测量:
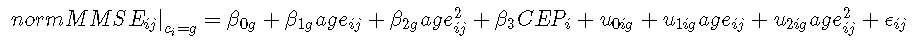
其中:
![]() 和
和 ![]()
固定效应部分 是 ![]() 混合
混合 ![]() 和
和 ![]() ; 在 随机效应部分 是
; 在 随机效应部分 是 ![]() ,
,
因变量:归一化 简易智能量表评分
由于 简易智能量表评分的分布非常倾斜,我们使用标准化版本
-
normMMSE <- norm
-
估计只有一个类的模型 (G=1)
根据年龄进行分析。为了避免任何数值问题,我们重新调整和标准化年龄:
-
-
-
-
age65 <- (age - 65)/10
-
-
我们为 norm 拟合线性混合模型:
-
-
-
lme(norm ~ age65+I(age65^2)+CEP rand =~ age65+I(age65^2) subject = 'ID'
-
-
-
估计具有多个类的模型 (G > 1)
从通过假设单个潜在类估计的模型,我们现在可以搜索异构概况。下一行提供了使用 G>1 时初始值对 2 个潜在类的模型的估计。
-
-
-
-
#考虑到2类的估计
-
lme(ng = 2, mix=~age65+I(age65^2))
-
-
-
初始值
初始值在参数中指定 B。该选项会 B=m1 根据 1 类模型(此处为m1)的最大似然估计自动生成初始值 。不指定B 或 不指定 B=NULL 是不推荐的,因为它会导致 G=1G=1 的模型的内部预估计(即 m1),这可能会显着增加计算时间。
用户预先指定的值
在以下示例中,初始值由用户预先指定:方差协方差的参数取自线性混合模型的估计值,并针对特定于类尝试任意初始值:
-
-
lme( B = c(0, 50, 30, 3, -1))
-
-
-
随机生成的值
另一种方法是从 1 类模型的估计值的渐近分布中随机生成初始值(此处为 m1):
-
-
lme(rand(m1))
-
-
-
网格搜索
最后,grid可用于运行自动网格搜索。在接下来的示例中,G=2 和 G=3 类, hlme 从 100 个初始值的随机向量运行最多 30 次迭代。然后,仅针对在 30 次迭代后提供最佳对数似然的偏离完成估计程序。
-
-
grid(lme iter=30,)
推荐使用此方法,因为它可以在重复次数足够大且迭代次数相当大时更好地探索参数空间。
选择最佳模型
一组模型(通常具有不同数量的潜在类)的估计过程可以用 来概括 summary。
-
-
-
summary

我们在这里总结了我们之前估计的 6 个模型。我们可以看到所有的 2-class 模型都收敛于同一个估计点。
这个例子说明了定义“潜在类的最佳数量”的复杂性。事实上,根据推荐的 BIC,应该保留 2 类模型(因为它提供了最低值)。但是 AIC 和 Size 调整 BIC(涉及较小的惩罚)都支持 3-class 模型。熵也有利于 3 类模型,因为它具有更好的判别能力(熵接近 1)。最后,3-class 模型创建了一个非常小的类,这通常不是那些搜索和感兴趣的异质性。在这个例子中,根据统计和临床标准,2-或 3-可以保留类模型。下面,我们保留了最终输出描述的 2-class 模型。
2-class 线性混合模型的描述
模型概要
-
-
-
-
summary(m2d)
-
-




模型的预测
只要模型中指定的所有协变量都包含在数据框中,就可以为数据框中包含的任何数据计算特定于类的预测。在接下来的几行中,通过生成年龄值介于 65 和 95 之间的向量并将 CEP定义为 1 或 0,来创建这样的数据框 。计算和绘制 预测 。
-
data.frame(age=seq(65,95,l=50))
-
-
在点估计中为每个类计算预测:
-
predictY
-
-
-
然后可以绘制预测:
-
-
-
plot(prd0)
-
-
plot(prd1,add=TRUE)
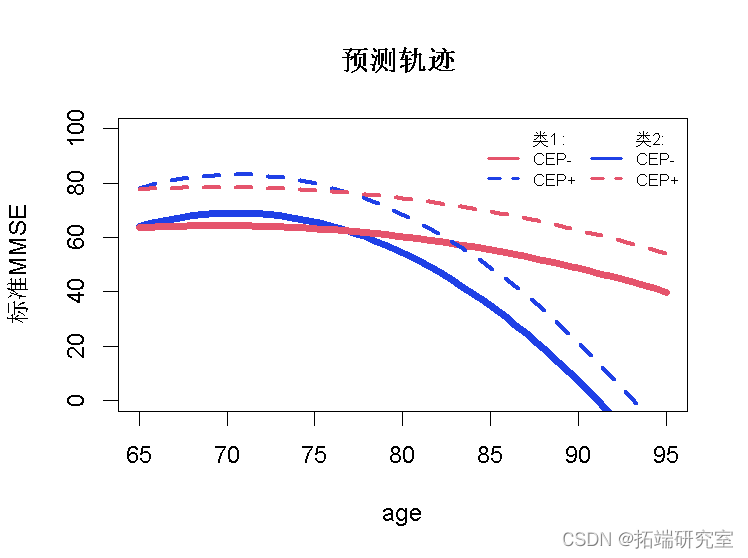
如果我们想了解可变性,我们可以计算具有置信区间的预测并绘制它们:
-
-
plot(IC,, shades=TRUE)
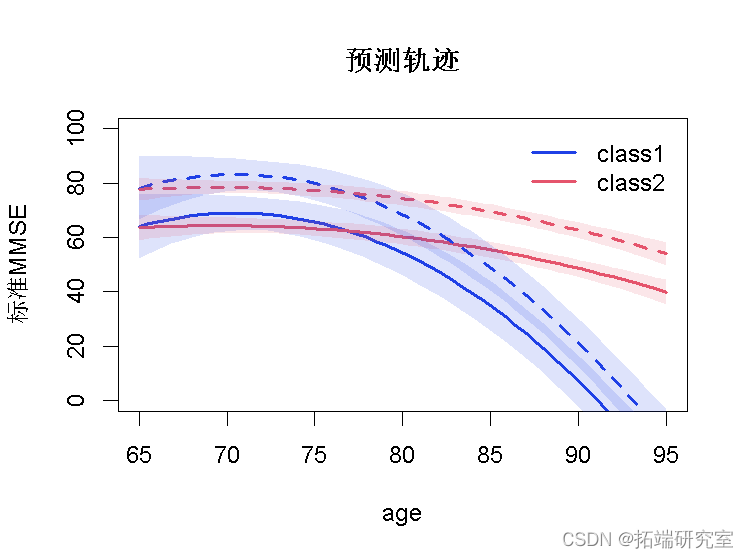
最后,1 类、2 类和 3 类模型的预测轨迹可以一起表示在下图中:
-
-
-
par(mfrow=c(1,3))
-
-
plot(pr1 )
-
-
plot(pr0
-
-
plot(pr3)
-
-
-
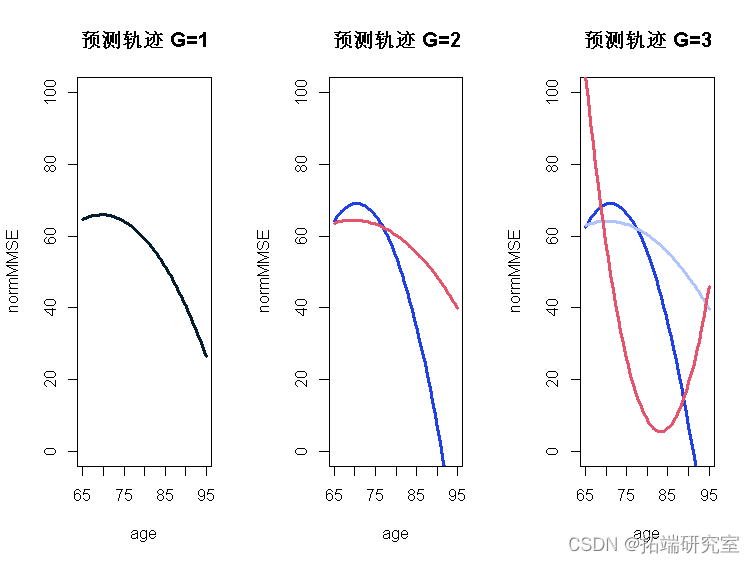
最终潜在类混合模型的评估
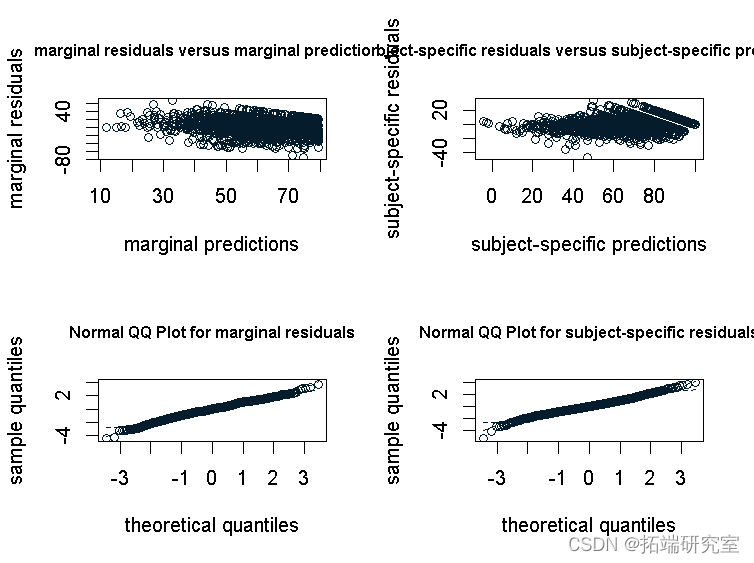
残差图
-
-
-
-
plot(m)
-
-
-
预测与观察的图表
为了评估所选模型的拟合,我们同时绘制每个潜在类别的观察值和预测值。
-
-
-
plot(m, shad = TRUE)
-
-
-
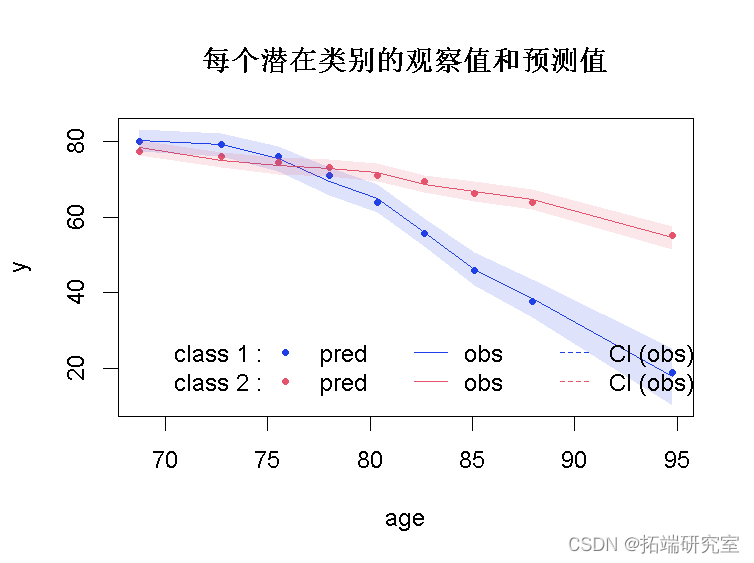
该图在此处显示了对数据的非常好的拟合。
分类
模型的后验分类通过以下方式获得:
-
-
-
postprob(m2d)
-
-
-


Class 1 由 62 个样本 (12.4%) 组成,而 438 个样本属于第二类。
我们还可以通过以下方式查看有关模型辨别能力的信息:
-
后验分类表:分类在
class 1(resp.class 2) 中的对象属于该类的平均概率为 0.8054 (resp. 0.8730)。这显示了类别的良好区分。 - 高于阈值的分类的比例:这里 90.18%(分别为 61.29%)的第 1 类(分别为 2)的后验概率大于 70%。

最受欢迎的见解
2.R语言用Rshiny探索lme4广义线性混合模型(GLMM)和线性混合模型(LMM)
6.线性混合效应模型Linear Mixed-Effects Models的部分折叠Gibbs采样