原文链接:http://tecdat.cn/?p=8214
M / M / 1系统
该系统的基本参数::

![]()
使用M / M / 1系统进行仿真非常简单 。
lambda <- 2
mu <- 4
rho <- lambda/mu # = 2/4
..
例如, 可以快速可视化随时间变化的资源使用情况。在下面,我们可以看到仿真如何收敛到系统中理论上的平均客户数。
# Theoretical value
mm1.N <- rho/(1-rho)
graph + geom_hline(yintercept=mm1.N)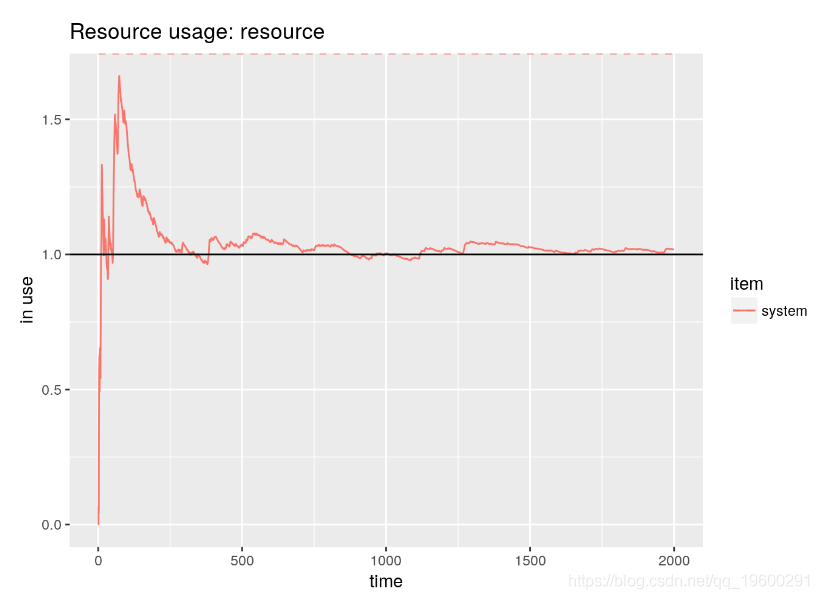
![]()
例如,还可以通过使用参数items和来可视化各个元素的瞬时steps。
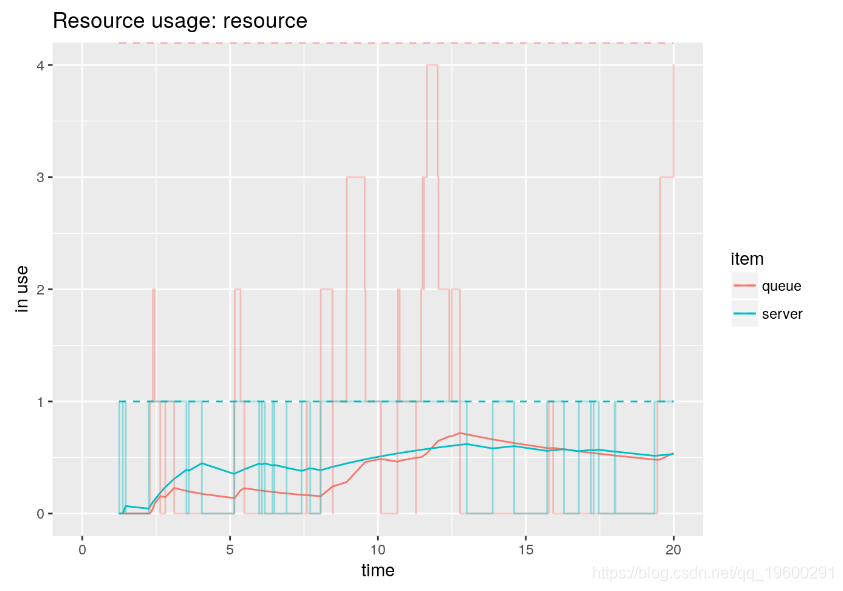
![]()
我们可以获取系统中每个客户花费的时间,并将平均值与理论表达式进行比较。
## [1] 0.5## [1] 0.5012594看来它与理论值非常吻合。
并行化的缺点是,当每个线程完成时,我们会丢失基础的C ++对象 。让我们执行一个简单的测试:
library(dplyr)
t_system <- get_mon_arrivals(envs) %>%
mutate(t_system = end_time - start_time) %>%
group_by(replication) %>%
summarise(mean = mean(t_system))
t.test(t_system$mean)##
## One Sample t-test
##
## data: t_system$mean
## t = 348.23, df = 999, p-value < 2.2e-16
## alternative hypothesis: true mean is not equal to 0
## 95 percent confidence interval:
## 0.4957328 0.5013516
## sample estimates:
## mean of x
## 0.4985422最后,M / M / 1满足了系统中所用时间的分布,而该分布又是具有平均值的指数随机变量。
qqplot(mm1.t_system, rexp(length(mm1.t_system), 1/mm1.T))
abline(0, 1, lty=2, col="red") 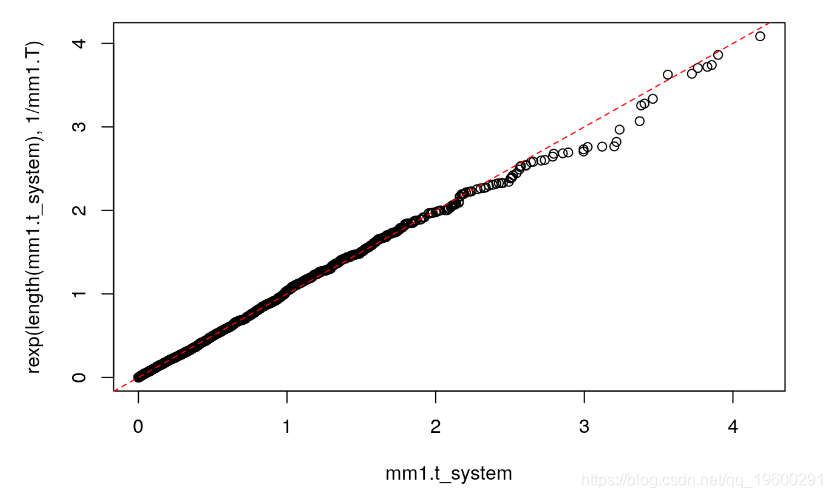
![]()
M / M / c / k系统
M / M / c / k系统保持指数到达和服务时间,但通常具有不止一台服务器和有限的队列,这通常更现实。例如,路由器可能有多个处理器来处理数据包,而输入/输出队列必定是有限的。
这是M / M / 2/3系统(2个服务器,队列中1个位置)的模拟。
lambda <- 2
mu <- 4
mm23.trajectory <- create_trajectory() %>%
...在这种情况下,队列已满时会有拒绝。
## rejection_rate
## 1 0.02009804尽管如此,与M / M / 1情况一样,系统中花费的时间仍遵循指数随机变量,但平均值有所下降。
# Comparison with M/M/1 times
qqplot(mm1.t_system, mm23.t_system)
abline(0, 1, lty=2, col="red")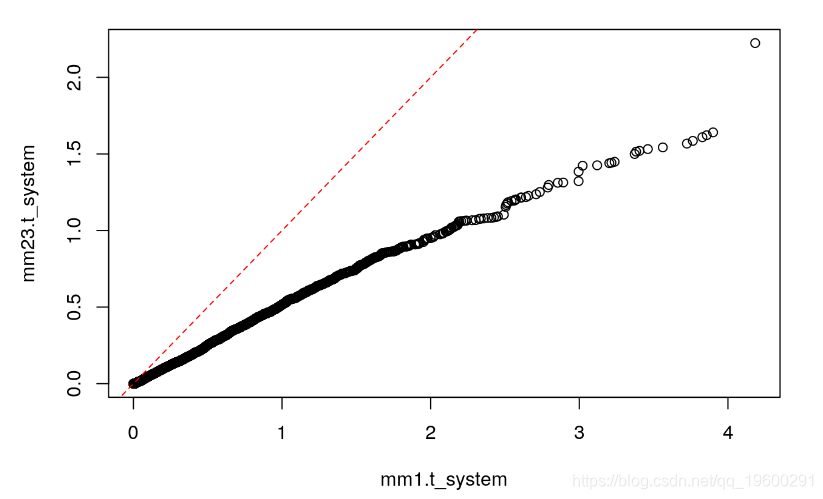
![]()