原文链接:http://tecdat.cn/?p=6751
模拟回归模型的数据
验证回归模型的首选方法是模拟来自它们的数据,并查看模拟数据是否捕获原始数据的相关特征。感兴趣的基本特征是平均值。我喜欢这种方法,因为它可以扩展到广义线性模型(logistic,Poisson,gamma,...)和其他回归模型,比如t -regression。
您的标准回归模型假设存在将预测变量与结果相关联的真实/固定参数。但是,当我们执行回归时,我们只估计这些参数。因此,回归软件返回表示系数不确定性的标准误差。
我将用一个例子来证明我的意思。
示范
我将使用泊松回归来证明这一点。我模拟了两个预测变量,使用50的小样本。
n <- 50
set.seed(18050518)
xc的系数为0.5 ,xb的系数为1 。我对预测进行取幂,并使用该rpois()函数生成泊松分布结果。
# Exponentiate prediction and pass to rpois()
summary(dat)
xc xb y
Min. :-2.903259 Min. :0.00 Min. :0.00
1st Qu.:-0.648742 1st Qu.:0.00 1st Qu.:1.00
Median :-0.011887 Median :0.00 Median :2.00
Mean : 0.006109 Mean :0.38 Mean :2.02
3rd Qu.: 0.808587 3rd Qu.:1.00 3rd Qu.:3.00
Max. : 2.513353 Max. :1.00 Max. :7.00
接下来是运行模型。
Call:
glm(formula = y ~ xc + xb, family = poisson, data = dat)
Deviance Residuals:
Min 1Q Median 3Q Max
-1.9065 -0.9850 -0.1355 0.5616 2.4264
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 0.20839 0.15826 1.317 0.188
xc 0.46166 0.09284 4.973 6.61e-07 ***
xb 0.80954 0.20045 4.039 5.38e-05 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
(Dispersion parameter for poisson family taken to be 1)
Null deviance: 91.087 on 49 degrees of freedom
Residual deviance: 52.552 on 47 degrees of freedom
AIC: 161.84
Number of Fisher Scoring iterations: 5
估计的系数与人口模型相距不太远,.21代表截距而不是0,.46而不是.5,而0.81而不是1。
接下来模拟模型中的数据,我想要10,000个模拟数据集,为了捕捉回归系数的不确定性,我假设系数来自多元正态分布,估计系数作为均值,回归系数的方差 - 协方差矩阵作为多元正态分布的方差 - 协方差矩阵。
coefs <- mvrnorm(n = 10000, mu = coefficients(fit.p), Sigma = vcov(fit.p))
检查模拟系数与原始系数的匹配程度。
coefficients(fit.p)
(Intercept) xc xb
0.2083933 0.4616605 0.8095403
colMeans(coefs) # means of simulated coefficients
(Intercept) xc xb
0.2088947 0.4624729 0.8094507
标准错误:
sqrt(diag(vcov(fit.p)))
(Intercept) xc xb
0.15825667 0.09284108 0.20044809
apply(coefs, 2, sd) # standard deviation of simulated coefficients
(Intercept) xc xb
0.16002806 0.09219235 0.20034148
下一步是模拟模型中的数据。我们通过将模拟系数的每一行乘以原始预测变量来实现。然后我们传递预测:
# One row per case, one column per simulated set of coefficients
# Cross product of model matrix by coefficients, exponentiate result,
# then use to simulate Poisson-distributed outcome
for (i in 1:nrow(coefs)) {
sim.dat[, i] <- rpois(n, exp(fit.p.mat %*% coefs[i ]))
}
rm(i, fit.p.mat) # Clean house
现在一个是完成模拟,将模拟数据集与原始数据集至少比较结果的均值和方差:
c(mean(dat$y), var(dat$y)) # Mean and variance of original outcome
[1] 2.020000 3.366939
c(mean(colMeans(sim.dat)), mean(apply(sim.dat, 2, var))) # average of mean and var of 10,000 simulated outcomes
[1] 2.050724 4.167751
模拟结果的平均值略高于原始数据,平均方差更高。平均而言,可以预期方差比平均值更偏离目标。方差也将与一些极高的值正偏差,同时,它的界限为零,因此中位数可能更好地反映了数据的中心:
[1] 3.907143
中位数方差更接近原始结果的方差。
这是模拟均值和方差的分布:
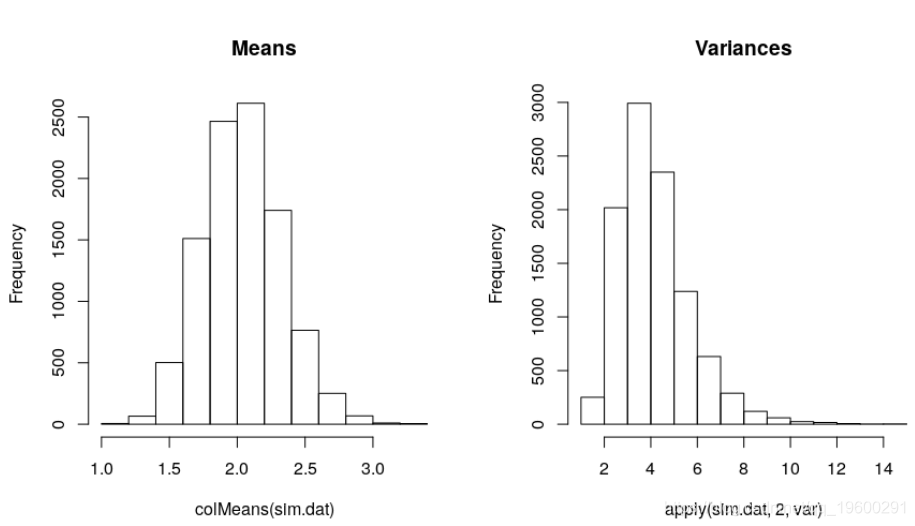
![]()
绘制10,000个模拟数据集中的一些数据集的直方图并将其与原始结果的直方图进行比较也是有用的。还可以测试原始数据和模拟数据集中xb = 1和xb = 0之间结果的平均差异。
回到基础R,它具有simulate()执行相同操作的功能:
sim.default <- simulate(fit.p, 10000)
此代码相当于:
sim.default <- replicate(10000, rpois(n, fitted(fit.p)))
fitted(fit.p)是响应尺度的预测,或指数线性预测器,因为这是泊松回归。因此,我们将使用模型中的单组预测值来重复创建模拟结果。
c(mean(colMeans(sim.default)), mean(apply(sim.default, 2, var)),
[1] 2.020036 3.931580 3.810612
与忽略系数不确定性时相比,均值和方差更接近原始结果的均值和方差。与考虑回归系数的不确定性时相比,这种方法总是会导致方差较小。它要快得多,并且需要零编程来实现,但我不习惯忽略回归系数的不确定性,使模型看起来比它更充分。