Python简介
Python ,是一种面向对象的解释型计算机程序设计语言,由荷兰人Guido van Rossum于1989年发明,第一个公开发行版发行于1991年。
解释器执行原理
Python在执行时,首先会将.py文件中的源代码编译成Python的字节码,然后再由Python虚拟机来执行这些编译好的字节码。这种机制的基本思想跟Java,.NET是一致的。然而,Python虚拟机与Java或.NET的虚拟机不同的是,Python的虚拟机是一种更高级的虚拟机。这里的高级并不是通常意义上的高级,不是说Python的虚拟机比Java或.NET的功能更强大,而是说和Java 或.NET相比,Python的虚拟机距离真实机器的距离更远。或者可以这么说,Python的虚拟机是一种抽象层次更高的虚拟机。基于C的Python编译出的字节码文件,通常是.pyc格式。
字符编码/注释/变量/缩进
字符编码:Unicode固然统一了编码方式,但是它的效率不高,比如UCS-4(Unicode的标准之一)规定用4个字节存储一个符号,那么每个英文字母前都必然有三个字节是0,这对存储和传输来说都很耗资源。为了提高Unicode的编码效率,于是就出现了UTF-8编码。UTF-8可以根据不同的符号自动选择编码的长短。比如英文字母可以只用1个字节就够了。在python文件中,如果有中文,就一定要在文件的第一行标记使用的编码类型,例如 #-*-encoding=utf-8-*- ,就是使用utf-8的编码。
注释:#
变量:计算机语言中能储存计算结果或能表示值抽象概念。变量可以通过变量名访问。
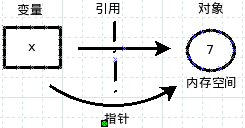 在机器的内存中,系统分配一个空间,这里面就放着所谓的对象,有时候放数字,有时候放字符串。如果放数字,就是int类型,如果放字符串,就是str类型。接下来的事情,就是变量用自己所拥有的能力,把对象和自己连接起来(指针连接对象空间),这就是引用。引用完成,就实现了赋值。
在机器的内存中,系统分配一个空间,这里面就放着所谓的对象,有时候放数字,有时候放字符串。如果放数字,就是int类型,如果放字符串,就是str类型。接下来的事情,就是变量用自己所拥有的能力,把对象和自己连接起来(指针连接对象空间),这就是引用。引用完成,就实现了赋值。
缩进:对于Python而言代码缩进是一种语法,Python没有像其他语言一样采用{}或者begin...end分隔代码块,而是采用代码缩进和冒号来区分代码之间的层次。缩进的空白数量是可变的,但是所有代码块语句必须包含相同的缩进空白数量,这个必须严格执行。
流程控制:
if语句、for语句、range函数、break 和 continue 语句,循环时使用else、pass语句
1 if 语句 >>> x = int(input("Please input a number: ")) Please input a number: 3 >>> x 3 >>> if x < 0: ... x = 0 ... print ('Negative number') ... elif x == 0: ... print ('Zero') ... elif x == 1: ... print ('Single') ... else: ... print ('More') ... More 2 for 语句 Python 中的 for 语句和 C 或者 Pascal 中的for语句有所不同,在c中,for 语句通常由 判断语句,条件判断,值变化 三部分 构成,python 中 for 语句结构是在一个序列上遍历: >>> # Measure some string ... words = ['cat', 'windows', 'linux'] >>> for w in words: ... print (w, len(w)) ... cat 3 windows 7 linux 5 3 range函数 如果你想在一个数字序列上迭代,那么range函数可能对你有用,从下面的例子中体会range 的不同表达式的含义: >>> range (5) [0, 1, 2, 3, 4] >>> range (2,5) [2, 3, 4] >>> range (5,10,1) [5, 6, 7, 8, 9] >>> range (5,10,2) [5, 7, 9] >>> range (5,10,3) [5, 8] 如果想使用下标在一个序列上迭代,可以使用range函数 >>> words ['cat', 'windows', 'linux'] >>> for i in range(len(words)): ... print (i, words[i]) ... 0 cat 1 windows 2 linux 多数情况下,enumerate函数会更方便。我们在后面的章节会介绍。
4 break 和 continue 语句,循环时使用else braak:直接跳出整个循环,continue:停止本次循环,直接开始下一次的循环 else可以用于for循环,当循环自然终止,即没有被break中止时,会执行else下的语句 >>> for n in range (2,10): ... for x in range (2,n): ... if n % x == 0: ... print (n, 'equals', x, '*', n/x) ... break ... else: ... print (n, 'is a prime number') ... 2 is a prime number 3 is a prime number 4 equals 2 * 2 5 is a prime number 6 equals 2 * 3 7 is a prime number 8 equals 2 * 4 9 equals 3 * 3 continue语句,从C语言中借鉴而来,直接转入循环的下一次迭代。 >>> for num in range(2,10): ... if num % 2 == 0: ... print (num, 'is an even number') ... continue ... print (num, 'is not an even number') ... 2 is an even number 3 is not an even number 4 is an even number 5 is not an even number 6 is an even number 7 is not an even number 8 is an even number 9 is not an even number 5 pass语句 pass 语句什么都不做,用于需要一个语句以符合语法,但又什么都不需要做时, 也可以用于写一个空函数 >>> while True: ... pass #busy-wait for keyboard interrupt (Ctrl+c) ... ^CTraceback (most recent call last): File "<stdin>", line 1, in <module> KeyboardInterrupt >>> class myEmptyClass: ... pass ... >>> def initlog(*args): ... pass # Remember to implement this ...
初识文件操作
读取文件内容
#要以一个读的模式打开一个文件,使用open()函数,r 表示以read的模式打开 f = open('test.text','r') #使用read()可以一次性读取文件的全部内容,python把内容读到内存,用一个str表示 print(f.read()) #使用close关闭文件,文件使用完毕后必须关闭,不让文件对象会占用操作系统的资源 f.close()
写内容进文件 #创建一个新文件,w 表示以wirte的模式创建一个新文件 f = open('NewFile.text','w') #往创建的文件里面写东西 f.write('This is frist line!!! ') f.write('This is second line!!! ') #关闭文件 f.close()
追加文件内容 #以追加的模式打开文件 f = open('test.text','a') #往文件里写东西 f.write('this line is append!!!! ') f.close()
修改文件的内容 #打开文件 f = open('test.text','r') new_f = open('new_test.text','w') for line in f: if 'old' in line:#判断需要修改的内容是否在这一行 line = line.replace(line,'---new--- ')#替换 new_f.write(line)#往新建的文件里写东西 f.close() new_f.close()
f = open('test.text','r') print(f.mode) # f.mode 显示文件打开的格式 f.close() f = open('test.text','r') print(f.read())#f.read把文件一次性读到内存 f.close() f = open('test.text','r') print(f.readline())#f.readline读第一行到内存 print(f.readline())#f.readline读第二行到内存 print(f.readline())#f.readline读第三行到内存 f.close() f = open('test.text','r') print(f.readlines()) #把文件都读到内存,并且每行转换成列表中的一个元素 f.close()
f.tell()#显示程序光标所在该文件中的当前位置
f.seek(0)#跳到指定位置,0即表示文件开始位置
f = open('test.text','r+')
f.truncate(4)#从文件开头截取4个字节,超出的都删除
f.close()
li = ['one','two','three','four']
f = open('test.text','r+')
f.writelines(li)#参数需为一个列表,将列表中的每个元素都写入文件
f.close()
f.xreadlines()#以迭代的形式循环文件,在处理大文件是极为有效,只记录文件开头和结尾,每循环一次,只读取一行,因此不需要一次性把文件加载到内存,而使用readlines()则需要把文件全部加载到内存中
数据类型内置方法
number1 = 123 #整数 number2 = 'abc' #字符串 number3 = [1,2,3] #列表 number4 =(1,2,3) #元组 number5 = {1:'a',2:'b'} #字典 print(type(number1)) print(type(number2)) print(type(number3)) print(type(number4)) print(type(number5)) <class 'int'> <class 'str'> <class 'list'> <class 'tuple'> <class 'dict'>
字符串格式化
| 格式化符号 | 说明 |
|---|---|
| %c | 转换成字符(ASCII 码值,或者长度为一的字符串) |
| %r | 优先用repr()函数进行字符串转换(Python2.0新增) |
| %s | 优先用str()函数进行字符串转换 |
| %d / %i | 转成有符号十进制数 |
| %u | 转成无符号十进制数 |
| %o | 转成无符号八进制数 |
| %x / %X | (Unsigned)转成无符号十六进制数(x / X 代表转换后的十六进制字符的大 小写) |
| %e / %E | 转成科学计数法(e / E控制输出e / E) |
| %f / %F | 转成浮点数(小数部分自然截断) |
| %g / %G | %e和%f / %E和%F 的简写 |
| %% | 输出% |
当然,还有一些辅助符号,如下表所示:
| 辅助符号 | 说明 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号(+) |
| <sp> | 在正数前面显示空格 |
| # | 在八进制数前面显示零(0),在十六进制前面显示“0x”或者“0X”(取决于用的是“x”还是“X”) |
| 0 | 显示的数字前面填充“0”而不是默认的空格 |
| m.n | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
注意:辅助符号要在百分号(%)和格式化符号之间。
charA = 65 charB = 66 print("ASCII码65代表:%c" % charA) print("ASCII码66代表:%c" % charB) Num1 = 0xFFFF Num2 = 0xFFFFFFFFFFFFFFFF print('转换成十进制分别为:%u和%u' % (Num1, Num2)) Num3 = 1200000 print('转换成科学计数法为:%e' % Num3) Num4 = 108 print("%#X" % Num4) Num5 = 234.567890 print("%.4f" % Num5)
运算符
按你的理解去理解
输入输出
str = input("请输入:"); print ("你输入的内容是: ", str)
三元运算
python没有三元运算符,代替方案
num = -10 print("正数") if num > 0 else print("负数")#先判断if后面的条件,满足条件执行if前面的语句,不满足则执行else后面的语句
collections模块
我们都知道,Python拥有一些内置的数据类型,比如str, int, list, tuple, dict等, collections模块在这些内置数据类型的基础上,提供了几个额外的数据类型:
- namedtuple(): 生成可以使用名字来访问元素内容的tuple子类
- deque: 双端队列,可以快速的从另外一侧追加和推出对象
- Counter: 计数器,主要用来计数
- OrderedDict: 有序字典
- defaultdict: 带有默认值的字典
列表、字典、元组、集合
列表:列表可以当成普通的数组,每当用到引用时,Python总是会将这个引用指向一个对象,所以程序只需处理对象的操作。当把一个对象赋给一个数据结构元素或变量名时,Python总是会存储对象的引用,而不是对象的一个拷贝。list的官方内置函数可用dir(list)与help(list) 命令进行查看。
L = ['qypt','ctc'] #创建列表 li = [1,2,3,4,['a','b','c'],'abc','abc','a','a','a',9,5] #创建列表 print( li[1],' ', #list的索引,左1索引为0,右1索引为-1 li[1:5:2],' ', #list的切片,切一部分,范围为索引[1,5),即1、2、3、4不包括5,隔2取1个值 li[4][1],' ', #列表支持嵌套 li.append('append_number'),' ', #追加元素,加在最后 li.insert(1,'index_num') ,' ', #在index的位置追加元素,位置就是索引 li.pop(),' ', #从list中删除最后一个元素,并返回该元素 li.remove('a'),' ', #删除第一次出现的该元素 li.count('a'),' ', #该元素在列表中出现的个数 li.index(4),' ', #该元素的位置(索引号),无则抛异常 #li.sort(),' ', #排序,列表元素需为int类型 li.extend(L),' ', #追加list,即合并L到li上,两个列表合并 li.reverse() #原地翻转列表,从前到后变成从后向前 ) print(li) -----------------------------------------------------------------------------------------------------------> 运行结果:
2 [2, 4] b None None append_number None 2 4 None None ['ctc', 'qypt', 5, 9, 'a', 'a', 'abc', 'abc', ['a', 'b', 'c'], 4, 3, 2, 'index_num', 1]
字典:字典就是一个关联数组,是一个通过关键字索引的对象的集合,使用键-值(key-value)进行存储,查找速度快,嵌套可以包含列表和其他的字典等,因为是无序,故不能进行序列操作,但可以在远处修改,通过键映射到值。字典是唯一内置的映射类型(键映射到值的对象)。字典存储的是对象引用,不是拷贝,和列表一样。字典的key是不能变的,list不能作为key,字符串、元祖、整数等都可以。
d = {'Name':'ctc','Addr':'qypt','Tel':'130***6'} # 创建dict
print(d['Name']) # 找出key为Name的值 d['Name'] == 'ctc'
d['Name'] = 'chentaicheng' # 更新key为Name的值 Name对应的值从ctc改为chentaicheng
print(d['Name']) # 找出key为Name的值 d['Name'] == 'chentaicheng'
del d['Name'] # 删除key为Name的值和该key d = {'Name': 'chentaicheng'}
d.clear() #删除字典d中的所有元素 d = {}
d.pop('Addr') #删除字典d中key为'Addr'的值和该键
d.copy() # 返回字典d的浅复制副本
seq = ('name','addr','tel')
dict = d.fromkeys(seq,10) # 创建一个新的字典,设置键为seq 和值为value
print(dict)
D = d.get('Name') #返回该键key的值
D = d.items() # 返回字典的(键,值)元组对的列表
D =d.keys() # 返回字典的键的列表
D = d.values() # 返回字典d的值列表
print(D)
d.iteritems() # (键,值)项的一个迭代器
d.iterkeys() # 字典d中键的一个迭代器
d.itervalues() # 字典d中值的一个迭代器
d.viewitems() # 像对象一样提供字典d中项的一个视图
d.viewkeys() # 像对象一样提供字典d中key的一个视图
d.viewvalues() # 像对象一样提供字典d中value的一个视图
元组:有序集合,通过偏移存取,属于不可变序列类型.固定长度、异构、任意嵌套,与列表相似,元祖是对象引用的数组。
和list相比
1.比列表操作速度快
2.对数据“写保护“
3.可用于字符串格式化中
4.可作为字典的key
t.count(var) # 该元素在元组中出现的个数 t.index(var) # 该元素的位置(索引号),无则抛异常
集合:set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作。还有一种集合是forzenset( ),是冻结的集合,它是不可变的,存在哈希值,好处是它可以作为字典的key,也可以作为其它集合的元素。缺点是一旦创建便不能更改,没有add,remove方法。
s = set([1,2,3]) # 创建一个数值set,有1,2,3三个元素s == set([1, 2, 3]) se = set('Hello') # 创建一个唯一字符的集合s == set(['H', 'e', 'l', 'o']) a = s | se # s 和 se 的并集 set([1, 2, 3, 'e', 'H', 'l', 'o']) b = s & se # s 和 se 的交集 set([]) 没有相同项为空 c = s - se # 求差集(项在s中,但不在se中) set([1, 2, 3]) d = s ^ se # 对称差集(项在s或se中,但不会同时出现在二者中) print(s) print(se) print(a) print(b) print(c) print(d) -------------------------------------------------------------------------------------------> -------------------------------------------------------------------------------------------> 运行结果 {1, 2, 3} {'H', 'l', 'o', 'e'} {'o', 1, 2, 3, 'H', 'l', 'e'} set() {1, 2, 3} {'o', 1, 2, 3, 'H', 'l', 'e'} ************************************************************************ li = [4,5,6] s = set([10,10,1,2,3,4,5,5,6,6,5,7,9,7,7,7,7,7,7]) t = set([20,10,1,2,3]) print(s.issubset(t)) # 如果s是t的子集,则返回True,否则返回False print(s.issuperset(t)) # 如果t是s的超集,则返回True,否则返回False print(s.union(t)) # 返回一个新集合,该集合是s和t的并集 print(s.intersection(t)) # 返回一个新集合,该集合是s和t的交集 print(s.difference(t)) # 返回一个新集合,该集合是 s 的成员,但不是 t 的成员 print(s.symmetric_difference(t)) # 返回一个新集合,该集合是s或t的成员,但不是s和t共有的成员 print(s.copy()) # 返回一个新集合,它是集合s的浅复制
print(s.pop()) # 删除集合是中的任意一个对象,并返回它
s.update(t) # 用t中的元素修改s,即s现在包含s或t的成员 s.intersection_update(t) # s中的成员是共同属于s和t中的元素 s.difference_update(t) # s中的成员是属于s但不包含在t中的元素 s.symmetric_difference_update(t) # s中的成员更新为那些包含在s或t中,但不是s和t共有的元素 s.add(100) # 在集合s中添加对象obj s.remove(2)# 从集合s中删除对象obj,如果obj不是集合s中的元素,(obj not in s),将引发KeyError s.discard(2) # 如果obj是集合s中的元素,从集合s中删除对象obj s.clear() # 删除集合s中的所有元素
函数: 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可
特性:
- 减少重复代码
- 使程序变的可扩展
- 使程序变得易维护
语法定义 def sayhi():#函数名 print("Hello, I'm kuangluxuanzhadiaofantian!") sayhi() #调用函数
可以带参数 #下面这段代码 a,b = 5,8 c = a**b print(c) #改成用函数写 def calc(x,y): res = x**y return res #返回函数执行结果 c = calc(a,b) #结果赋值给c变量 print(c)
形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值

默认参数 看下面代码 def stu_register(name, age, country, course): print("----注册学生信息------") print("姓名:", name) print("age:", age) print("国籍:", country) print("课程:", course) stu_register("王山炮", 22, "CN", "python_devops") stu_register("张叫春", 21, "CN", "linux") stu_register("刘老根", 25, "CN", "linux")
发现country这个参数基本都是"CN", 就像我们在网站上注册用户,像国籍这种信息,你不填写,默认就会是中国, 这就是通过默认参数实现的,把country变成默认参数非常简单 def stu_register(name, age, course, country="CN"): 这样,这个参数在调用时不指定,那默认就是CN,指定了的话,就用你指定的值。另外,你可能注意到了,在把country变成默认参数后,我同时把它的位置移到了最后面,为什么呢? 关键参数 正常情况下,给函数传参数要按顺序,不想按顺序就可以用关键参数,只需指定参数名即可,但记住一个要求就是,关键参数必须放在位置参数之后。 stu_register(age=22, name='alex', course="python", )
非固定参数 若你的函数在定义时不确定用户想传入多少个参数,就可以使用非固定参数 def stu_register(name,age,*args): # *args 会把多传入的参数变成一个元组形式 print(name,age,args) stu_register('ctc',22) #输出 ctc 22 (),后面这个()就是args,只是因为没传值,所以为空 stu_register('ctc',22,'python','qypt') #输出 ctc 22 ('python', 'qypt') 还可以有一个**kwargs def stu_register(name,age,*args,**kwargs): # *kwargs 会把多传入的参数变成一个dict形式 print(name,age,args,kwargs) stu_register('ctc',22) #输出ctc 22 () {},{}#后面这个{}就是kwargs,只是因为没传值,所以为空 stu_register('ctc',22,'python','qypt') #输出 ctc 22 ('python', 'qypt') {} stu_register('ctc',22,'python',school = 'qypt',sex = 'man') #ctc 22 ('python',) {'school': 'qypt', 'sex': 'man'}
''' 全局与局部变量 在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。 全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。 当全局变量与局部变量同名时: 在定义局部变量的子程序内,局部变量起作用;在其它地方全局变量起作用。 ''' name = "ChenTaicheng" #全局变量 def change_name(name): print("before change:", name) name = "一个改变世界的人" #局部变量 print("after change", name) change_name(name) print("在外面看看name改了么?", name)
返回值
要想获取函数的执行结果,就可以用return语句把结果返回
注意:
- 函数在执行过程中只要遇到return语句,就会停止执行并返回结果,so 也可以理解为 return 语句代表着函数的结束
- 如果未在函数中指定return,那这个函数的返回值为None
递归 在函数内部,可以调用其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。 def calc(n): print(n) if int(n / 2) == 0: return n return calc(int(n / 2)) f = calc(10) print(f) 输出: 10 5 2 1 1
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
匿名函数 :匿名函数就是不需要显式的指定函数
#这段代码 def calc(n): return n**n print(calc(10)) #换成匿名函数 calc = lambda n:n**n print(calc(10)) 你也许会说,用上这个东西没感觉有毛方便呀, 。。。。呵呵,如果是这么用,确实没毛线改进,不过匿名函数主要是和其它函数搭配使用的呢,如下 res = map(lambda x:x**2,[1,5,7,4,8]) for i in res: print(i) 输出 1 25 49 16 64
高阶函数:变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
内置参数:

面向对象
对象是对客观事物的抽象,类是对对象的抽象。 类是一种抽象的数据类型,它们的关系是,对象是类的实例,类是对象的模板。 函数与类: def func(): print('hello,world!') return '返回值' #默认为 None #调用函数 r = func() print(r) class Foo: #class 类名 def F1(self,name): #定义函数,在类中叫做方法 print('Hello,world!') print(name) return '返回值' #调用类 #创建对象 obj = Foo() #对象 = 类名() #通过对象执行方法 r = obj.F1('chentaicheng') #对象.方法() print(r)