前言
同花顺每天需要接收海量交易所行情数据,确保行情数据的数据准确。但由于该部分数据过于庞大,而且使用场景颇多,每天会产生很多的加工数据,而组合管理(PMS)还会使用到历史行情数据。之前虽然采用了Postgres+LevelDB作为数据的存储方案,但仍然有不少痛点,所以必须对存储方案进行改造。
通过对ClickHouse、InfluxDB、TDengine等时序数据存储方案的调研,最终我们选择了TDengine。大数据监控平台采用TDengine后,在稳定性、查询性能等方面都有较大的提升。
项目背景与问题
同花顺私募之家组合管理是一个集多资产管理、实时监控、绩效分析、风险分析、舆情分控、报表输出等功能于一体的智能投资组合管理平台。为券商、基金、私募等机构客户提供实时准确的投研服务。
数据层面主要依赖实时数据及历史日级别数据,为所支持的股票、基金、债券、美股、港股、期权、期货资产类别的监控和分析提供支持。
其中,实时数据主要用于资产监控,由于使用场景会对数百个不同的标的进行资产监控,数据刷新频率在1秒左右。因此,整个系统对实时数据的读写性能及延时有着比较高的要求。
此外,历史日级别数据主要用于投资组合的各种分析。历史分析所涉及的标的数量,相较实时资产监控更多,在时间上的跨度会长至10数年。此外在输出分析报告时,还会叠加多种分析指标和分析模型。在整个分析过程中,涉及巨量的数据集。这对历史数据库的读写性能又提出了更高的要求。
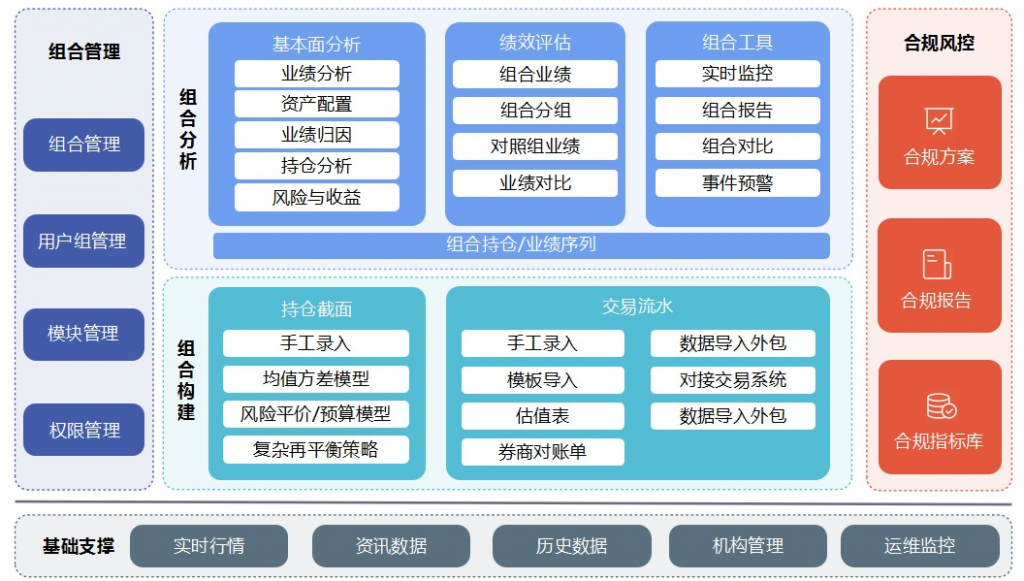
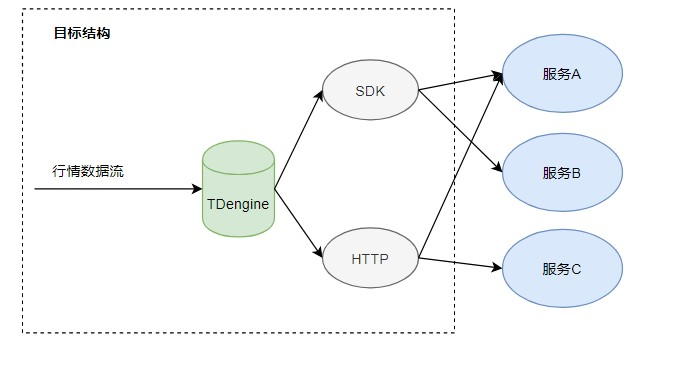
由上述架构图可以看到,该服务内需要大量的基础数据支撑,像实时行情、历史行情。
针对历史行情数据支撑,涉及多个证券品种的数据,包括股票、债券、基金、港股、美股、期货、期权。数据跨度周期从数天到数年不等。页面返回的数据是计算结果,而计算依赖的数据是业务层数据和大量历史行情数据。这个计算过程包含了历史行情数据请求。尤其是在展示结果包含多证券标的和长周期的情况下,产生一个分析报告可能达到 5s,而行情获取耗时占比达到80%以上。而且,输出报告服务面临并发情况,这种情况带来的拥堵会进一步恶化用户的使用体验。
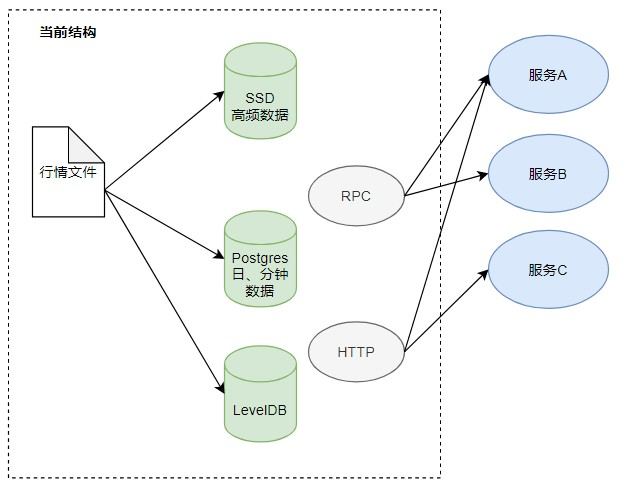
- 依赖多,稳定性较差:PMS作为多品种的投后分析服务, 需要使用到各种日线数据、当天实时行情数据、当天分钟数据等,在数据获取方面需要依赖Http以及Postgres、LevelDB等数据库。过于多的数据获取链路会导致平台可靠性降低,同时依赖于其他各个服务,导致查询问题过于复杂。
- 性能不能满足需求: PMS作为多品种投后分析,在算法分析层面需要大量的行情获取,而且对行情获取的性能也有较大的要求,当前所有行情会占据大量分析的性能。
技术选型
为解决上述问题,我们有必要对现有行情模块进行升级改造。在数据库选型方面,我们对如下数据库做了预研和分析:
- ClickHouse:运维成本太高,扩展过于复杂,使用的资源较多。
- InfluxDB: 可以高性能地查询与存储时序型数据,被广泛应用于存储系统的监控数据、IoT行业的实时数据等场景;但是集群功能没有开源。
- TDengine:性能、成本、运维难度都满足,支持横向扩展,且支持高可用。
通过综合对比,我们初步选定TDengine作为行情模块的数据库。
主要由于行情数据是绑定时间戳的形式,所以时序数据库更适用于这个业务场景。而且在同等数据集和硬件环境下,涛思官方的测试结果显示,TDengine的写入速度远高于InfluxDB。同时TDengine支持多种数据接口,包含C/C++、Java、Python、Go和RESTful等。
数据接入过程需要进行如下操作:
- 数据清洗,剔除格式不对的数据;
- 由于历史数据过于杂乱,采取脚本生成csv形式并直接导入,后续增量数据由Python实现脚本导入数据。
数据库建模以及应用场景
TDengine在接入数据前需要根据数据的特性设计schema,以达到最好的性能表现。
同花顺行情根据时间频度的不同,数据特性分别如下。
通用特性:
- 数据格式固定,自带时间戳;
- 数据极少需要更新或删除;
- 数据标签列不多,而且比较固定;
- 单条数据数据量较小,字段较少。
tick快照数据特性如下:
- 每天数据量大,超过2000W;
- 需保留近几年数据。
daily数据特性如下:
- 子表很多,约20W张表;
- 每天数据20W;
- 需保留近30年数据。
根据上述特点,我们构建了如下的数据模型。
按照TDengine建议的数据模型,将每个特性的数据单独创建数据库,根据不同特性数据设置不同的参数,在各个数据库内根据品种去创建超级表,例如股票、指数、债券、基金等,结合我们的数据特点和使用场景,创建数据模型如下:
- 以品种类型作为超级表,方便对同一类型的数据进行聚合分析计算;
- 标的本身包括标的信息,直接将标签信息作为超级表的标签列,每个品种作为子表。
库结构如下:
超级表结构:
落地实施
组合管理主要是需要可以稳定高效地获取到数据,所以在实施的过程中需要考虑查询的性能、线上数据的更新以及运维情况。
实施难点如下:
- 数据写入:由于历史行情数据会存在大量的历史数据,不是只接收当前新增的数据,这对历史数据的迁移有很大的挑战。当前TDengine数据库对于现有数据的导入,通过insert语句达到批量更新,会导致历史数据迁移耗时很大。为了解决该问题,我们在本地建立缓存,将现有csv文件修改为可执行导入的形式,直接通过csv导入,大大提升了写入速度。在这个过程中,我们还发现了一个问题:通过csv导入的时候,如果采用自动创建表的方式,会在几个版本内出现崩溃。通过询问官方,他们不建议在导入csv的时候创建表,后来我们就拆解为先创建表结构再进行csv导入,问题得到了解决。
- 查询问题:查询单点问题。TDengine原生HTTP查询是直接查询特定服务端完成的。这个在生产环境是存在风险的。首先,所有的查询都集中在一台服务端,容易导致单台机器过载;另外,无法保证查询服务的高可用。基于以上两点,我们在TDengine集群使用过程中,在应用使用创建链接的时候会配置多台Http的接口来解决单点问题。
- 容量规划:数据类型、数据规模对TDengine的性能影响比较大,每个场景最好根据自己的特性进行容量规划,影响因素包括表数量、数据长度、副本数和表活跃度等。根据这些因素调整配置参数,确保最佳性能,例如blocks、caches和ratioOfQueryCores等。根据与涛思数据工程师的沟通,我们确定了TDengine的容量规划计算模型。TDengine容量规划的难点在于内存的规划。
改造效果
完成改造后,线上的行情获取性能可以达到预期,目前运行稳定。
- 改造后性能对比情况,可以看到性能提升明显。

- 改造后稳定性对比情况:改造前调用数据情况共40W次,共出现异常0.01%的异常,改造后出现异常降低至0.001%。
TDengine问题解决
在使用TDengine的过程中,我们遇到了一些小问题。比如在通过Restful接口使用TDengine的时候,获取数据超过10240行会有限制。经过沟通,我们了解到在启动服务端时,参数restfulRowLimit 可以控制返回结果集的最大条数。
其他一些在使用过程中不清楚的地方,在涛思数据的物联网大数据微信交流群都能很快得到反馈和解答。一些小bug也可以通过版本升级解决。
总结
目前从大数据监控这个场景看,TDengine在成本、性能和使用便利性方面都有非常大的优势,尤其是在节省成本方面给我们带来了很大惊喜。
在预研和项目落地过程中,涛思数据的工程师提供了专业、及时的帮助,在此表示感谢。
希望TDengine能够不断提升性能和稳定性,开发新特性,我们也会根据自身需求进行二次开发,向社区贡献代码。祝TDengine越来越好。对于TDengine,我们也有一些期待改进的功能点:
- 支持更加丰富的SQL语句;
- 灰度平滑升级;
- 可实现自定义聚合方法;
- 更快的数据迁移。
后续我们也将在同花顺的更多场景中尝试应用TDengine,包括:
- tick、minute行情数据的迁移以及线上应用;
- 采取自定义聚合方法实现分钟行情、日线行情的聚合计算;
- 当天实时行情的数据的管理。