前言
性能是用户在选择和使用时序数据库时非常关注的一个点。
为了准确体现TDengine的性能数据,我们策划了《TDengine和InfluxDB的性能对比》系列测试报告。
“一言不合上数据”,今天我们就先来分享一下两款数据库写入性能的对比。
为了更加具有说服力,本次的测试是基于InfluxDB此前与Graphite的性能对比中使用过的场景和数据集的。(https://www.influxdata.com/blog/influxdb-outperforms-graphite-in-time-series-data-metrics-benchmark/)
经过多方准备与反复测试后,我们得出的结论是:
1.在InfluxDB发布的自己最优的条件下,TDengine的写入速度是它的2倍。
2.当设备数放大到1000的时候,TDengine的写入速度是InfluxDB的5.2倍。
此外,除了给出测试结果,我们还有一个小目标——那就是按照文中的步骤和配置,所有阅读本文的开发人员或者架构师都可以复现出同样的过程与结果。我们认为,只有通过这样得来的测试报告才是最有价值的测试报告。
正文
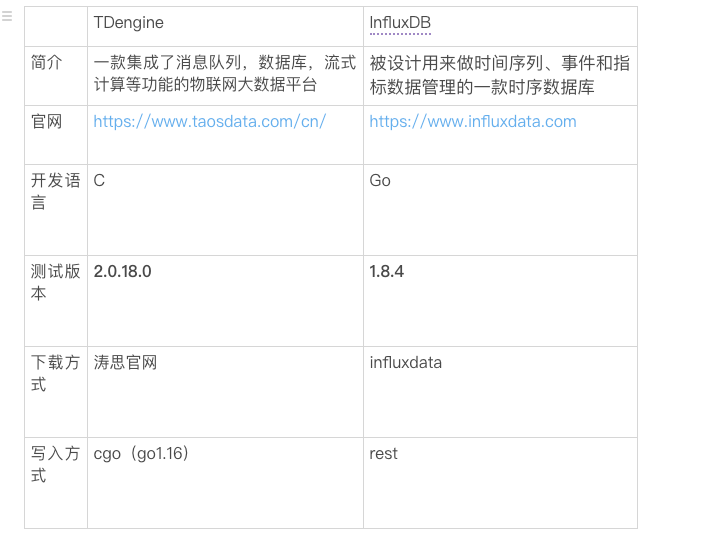
InfluxDB是一个用Go语言编写的开源时序数据库。其核心是一个自定义构建的存储引擎,它针对时间序列数据进行了优化,是目前最为流行的时间序列数据库,在DB-Engines的时序数据库榜单中稳居第一。

TDengine是一款集成了消息队列,数据库,流式计算等功能的物联网大数据平台。该产品不依赖任何开源或第三方软件,拥有完全自主知识产权,具有高性能、高可靠、可伸缩、零管理、简单易学等技术特点。和InfluxDB相比,TDengine是当前时序数据库领域中一匹势头正劲的黑马。
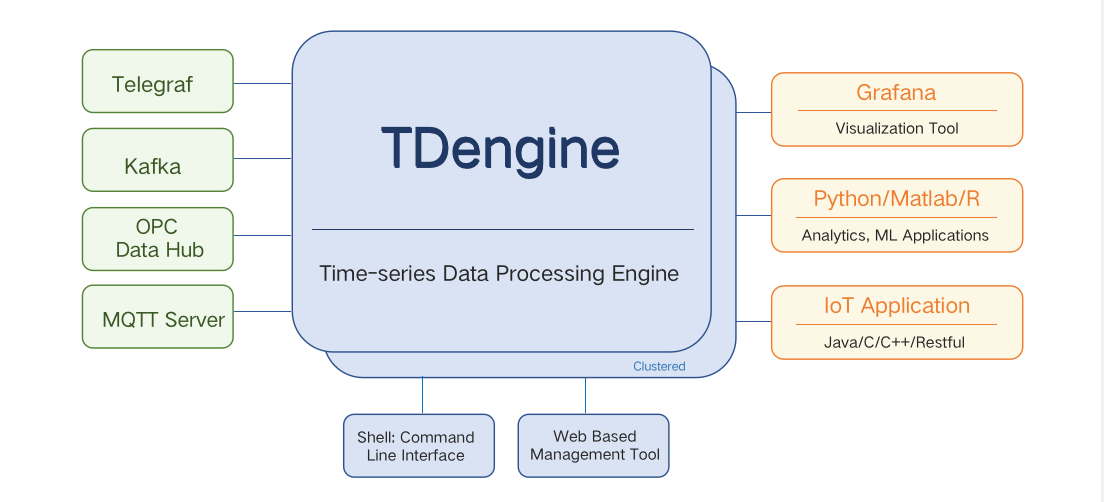
接下来,我们正式进入测试环节。
一. 基础信息如下:
本次测试使用的数据集是为DevOps监控指标案例建模的数据集。在这个场景中,一组服务器需要定期报告系统和应用程序的指标,具体实现是:每10秒在一台服务器上的9个子系统(CPU、内存、磁盘、磁盘I/O、内核、网络、Redis、PostgreSQL和Nginx)上采样100个值。为了更好的完成关键指标的对比,在与Graphite的该次对比中,InfluxDB选择了一个周期为24小时,设备为100台的设定。因此,本次的TDengine和InfluxDB对比测试也是重新使用了这个相对适中的部署。
重要参数如下图,在上文链接中均可见:

二. 环境准备
为了方便大家复现,我们所有的测试都是在运行Ubuntu 20.10的两台azure虚拟机上进行的,配置如下:
标准 E16as_v4 ©AMD EPYC 7452(32-Core Processor 2345.608 MHz,16vCPU, 128GB RAM, 5000 IOPS SSD 1024GB) 用于数据库服务端。
标准 F8s_v2 instance type ©Intel(R) Xeon(R) Platinum 8272CL (2.60GHz ,8vCPU,16 GB RAM)用于数据库客户端。
值得注意的是虽然上面服务端CPU显示为32核,但是云服务只分给16个processor。
三. 具体测试方法与步骤:
我们只要按照如下方式操作便可复现本次测试结果:
1.整体规划:
服务端机器需要安装Influxdb和TDengine服务端;客户端机器需要安装TDengine客户端(版本同为2.0.18)和go语言环境,以及从github上下载性能测试脚本并运行。
2.安装准备:
1) TDengine安装方式(包含客户端):
B. TDengine安装步骤
2) Influxdb安装方式:
3) go1.安装方式:
wget https://studygolang.com/dl/golang/go1.16.linux-amd64.tar.gz
tar -C /usr/local -xzf go1.16.linux-amd64.tar.gz
添加环境变量/etc/profile export PATH=$PATH:/usr/local/go/bin
source /etc/profile
部署完TDengine、InfluxDB与Go语言环境,确保两台服务器的数据库连接正常使用正常(建库删库写入查询功能均需测试,建库之后立即删除,如有问题立刻排查,为确保权限问题不打扰环境测试,可以全程使用root用户)
此外,在测试中应该注意以下几点:
1)fsync的设置要保持同步,InfluxDB默认是无延时的fsync,需要修改TDengine的这两个参数:walLevel=2 ,fsync=0才能达到相同的配置环境。后续的一切测试均是在这个设置条件下完成。
2)TDengine的客户端要把maxSQLLength开到最大1048576。
3.从github取下代码:
su - root
mkdir /comparisons
cd /comparisons
git clone https://github.com/taosdata/timeseriesdatabase-comparisons
4.编译准备:
1)cd /comparisons/timeseriesdatabase-comparisons,然后删除里面的go.mod和go.sum文件
2)执行 go mod init github.com/taosdata/timeseriesdatabase-comparisons
3)执行如下命令安装依赖包:
go get github.com/golang/protobuf/proto
go get github.com/google/flatbuffers/go
go get github.com/pelletier/go-toml
go get github.com/pkg/profile
go get github.com/valyala/fasthttp
最后看到新的go.sum和go.mod文件后,可以继续操作。
5.编译阶段:
mkdir /comparisons/timeseriesdatabase-comparisons/build/tsdbcompare/bin
我们写入需要3个程序,分别是bulk_data_gen、bulk_load_influx以及bulk_load_tdengine。下载得到代码后,分别进入相应目录执行编译等如下命令:
cd /comparisons/timeseriesdatabase-comparisons/cmd/bulk_data_gen ;go build ;cp bulk_data_gen ../../build/tsdbcompare/bin
cd ../bulk_load_influx;go build ;cp bulk_load_influx ../../build/tsdbcompare/bin
cd ../bulk_load_tdengine;go build ; cp bulk_load_tdengine ../../build/tsdbcompare/bin
(注意:编译bulk_load_tdengine之前要记得安装TDengine客户端)
6.修改脚本:
修改/comparisons/timeseriesdatabase-comparisons/build/tsdbcompare/write_to_server.sh, 把add='tdvs',修改为您选用的数据库服务端hostname。
然后修改如下四行命令,将原有目录替换为自己数据库的文件目录所在(通常TDengine为/var/lib/taos,Influxdb为/var/lib/influxdb):
rm -rf /mnt/lib/taos/* -> rm -rf /var/lib/taos/
rm -rf /mnt/lib/influxdb/* ->rm -rf /var/lib/influxdb/*
TDDISK=`ssh root@$add "du -sh /mnt/lib/taos/vnode | cut -d ' ' -f 1 " `-> TDDISK=`ssh root@$add "du -sh /var/lib/taos/vnode | cut -d ' ' -f 1 " `
IFDISK=`ssh root@$add "du -sh /mnt/lib/influxdb/data | cut -d ' ' -f 1" `-> IFDISK=`ssh root@$add "du -sh /var/lib/influxdb/data | cut -d ' ' -f 1" `
注销掉:curl "http://:8086$add/query?q=drop database benchmark_db" -X POST这一行前面的#。
7.运行脚本复现测试结果:
cd /comparisons/timeseriesdatabase-comparisons/build/tsdbcompare/
./loop_scale_to_server.sh
(注意:此脚本封装了数据的生成与写入过程,有兴趣的读者可以自行阅读。如果遇到干扰因素导致写入失败,可以手动传入参数再次执行得到测试结果。如write_to_server.sh -b 5000 -w 100 -g 0 -s 100。具体参数含义可以通过“/comparison/timeseriesdatabase-comparisons/build/tsdbcompare/write_to_server.sh -h得知)
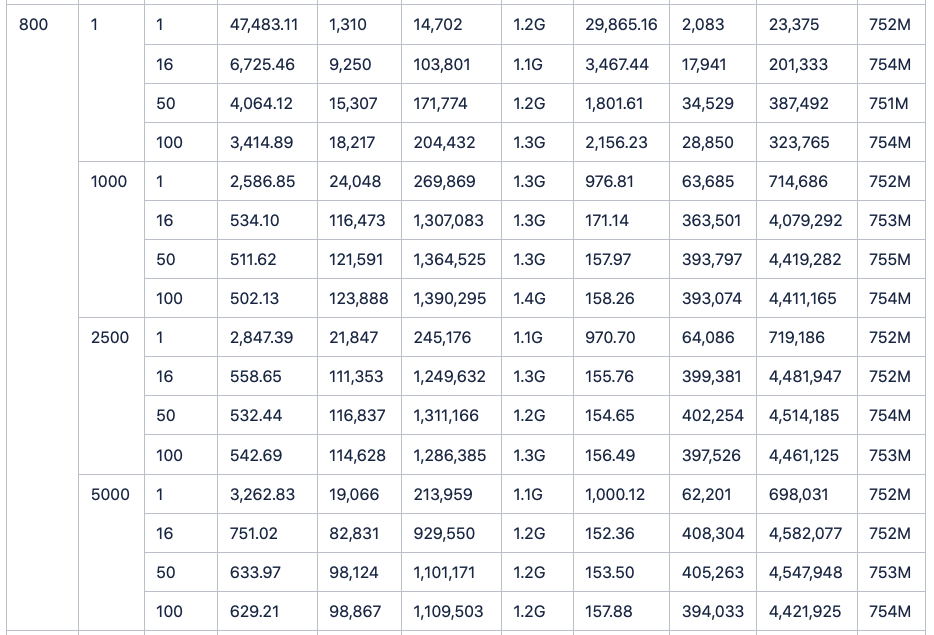
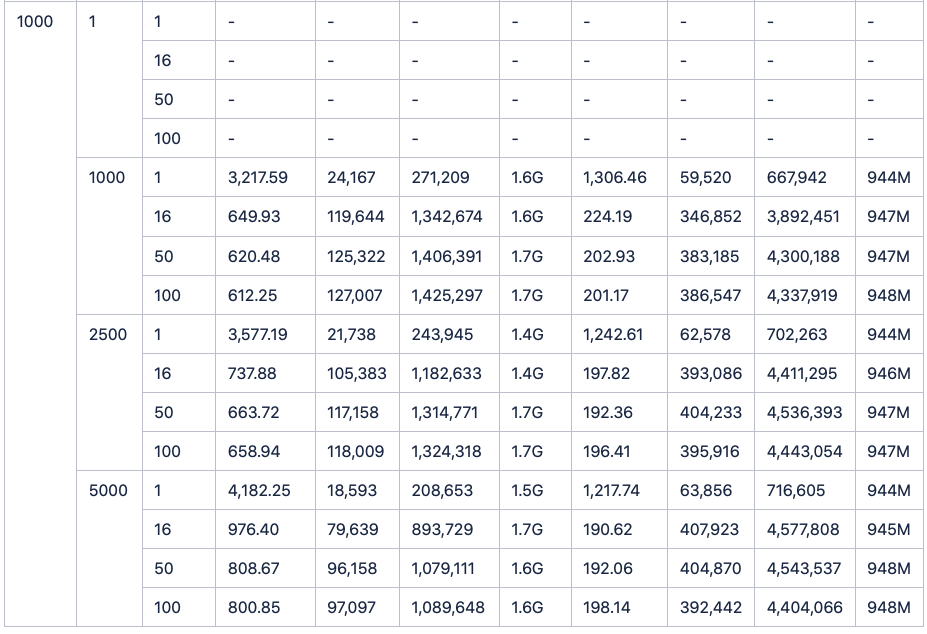
四. 实际测量数据
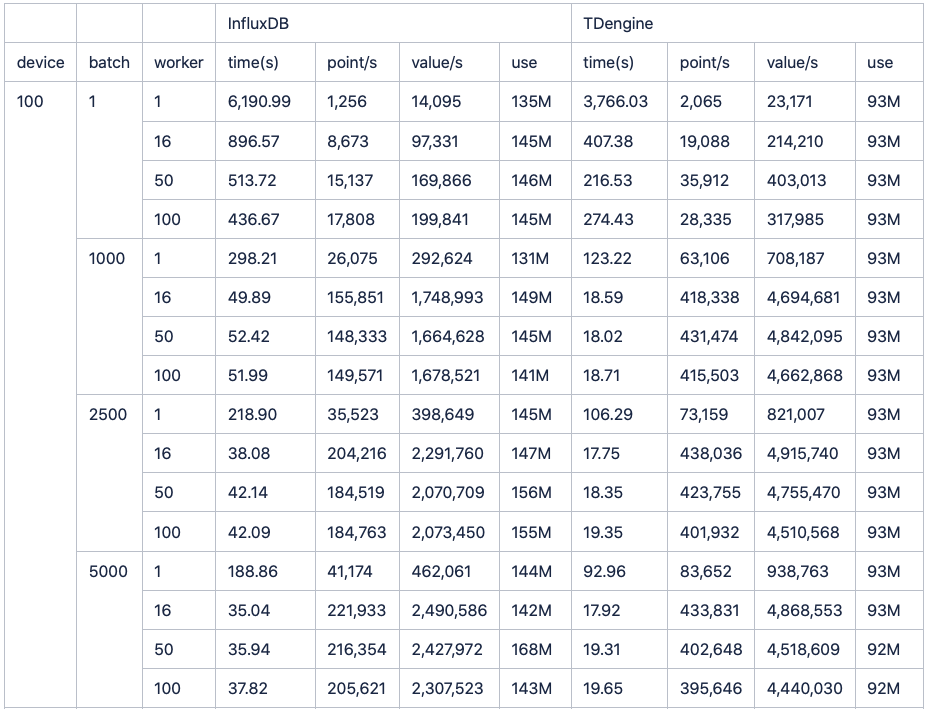
经过一番测试后,我们制作了这样一张表格。通过它我们可以清楚地看到:不论是单线程还是多线程,不论是小批次还是大批次,TDengine都一直稳稳保持着2倍左右的速度优势。
其中5000batch,16wokers的场景下(InfluxDB与Graphite的对比报告中的测试项),influxDB耗时35.04秒,而TDengine耗时仅17.92秒。
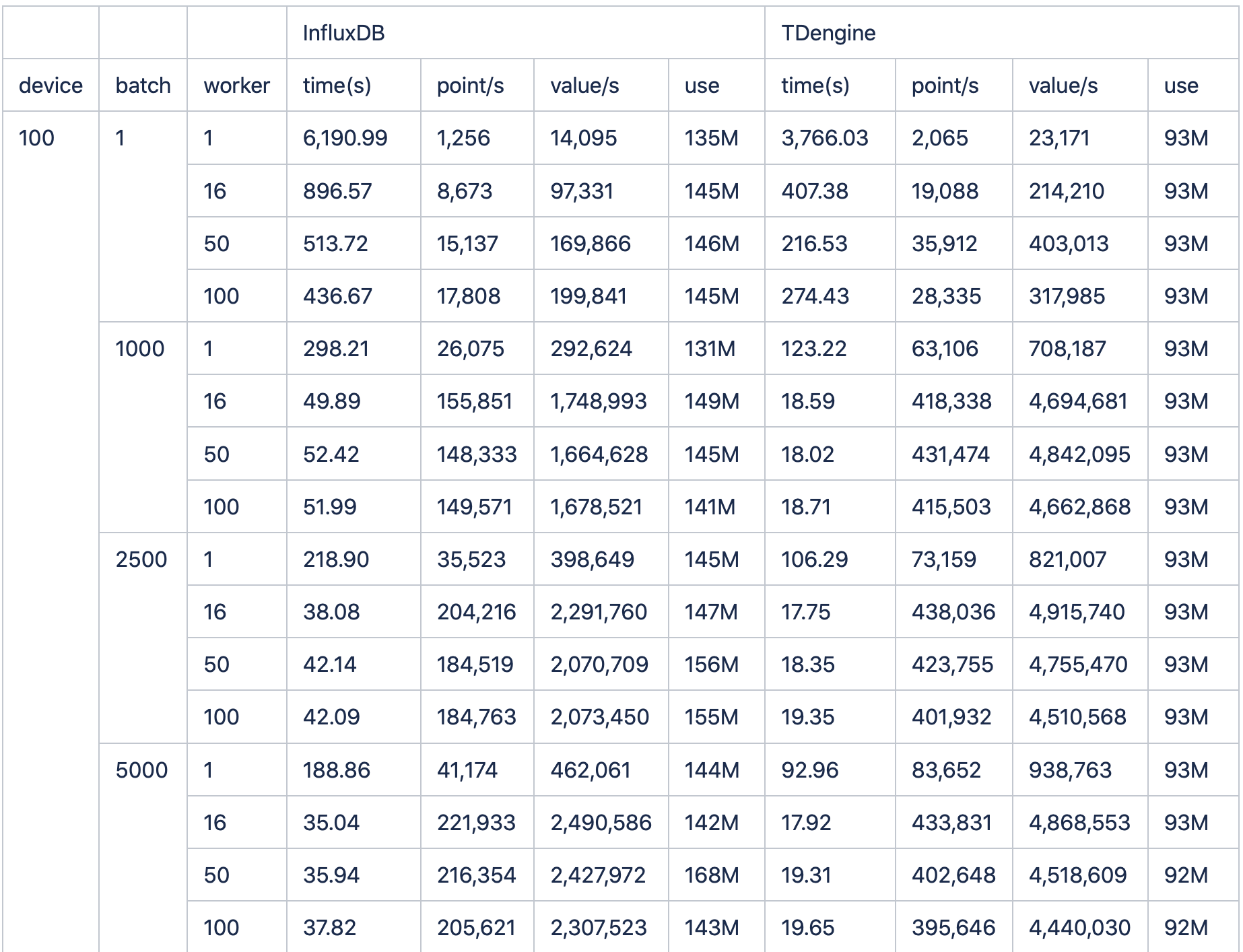
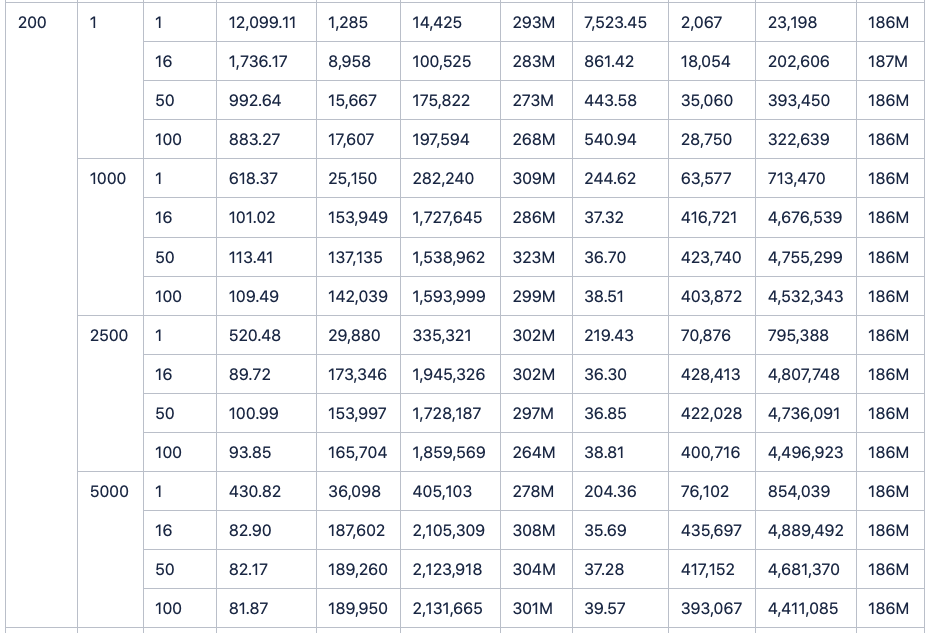
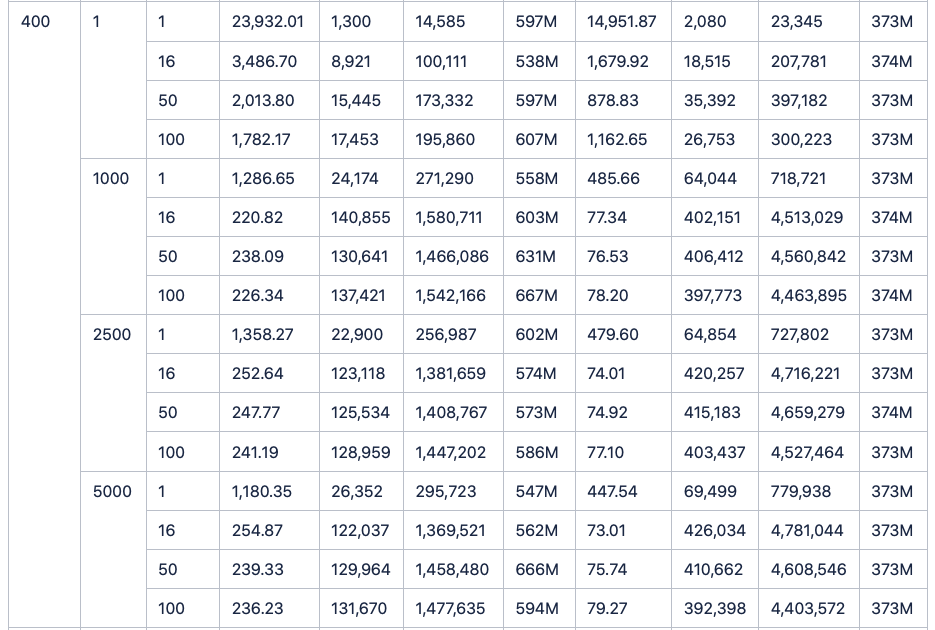
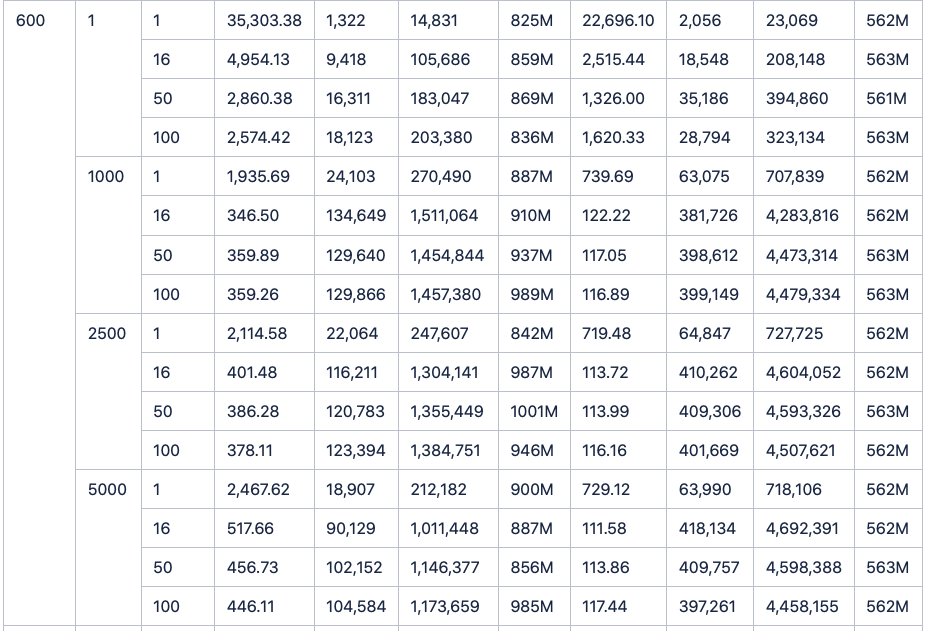
此外,InfluxDB仅仅做了100台设备和900个监测点的测试。但是于我们看来,实际应用场景中的设备数量和监测点数目一定是远远超过这个数字的。于是我们调整了脚本参数,从100个设备逐步增加到200,400,600,800,1000,通过将双方数据量的同比例放大,从而得出了更多接入设备情况下的写入对比结果。
(数据表格附在正文后。且由于所耗时间实在过长,所以1000台设备单线程写入1行的结果没有写入表格,不影响实际结果)结果是,在成倍地增加设备数后,TDengine依然保持着稳稳地领先,并且将优势继续扩大。
结论
当前的测试结果已经比较有力地说明了前言中的两点结论:
1.在InfluxDB发布的自己最优的条件下,TDengine的写入速度是它的两倍。
2.当设备数放大到1000的时候,TDengine的写入速度是InfluxDB的5.2倍。
由于5.2倍又恰好是本次测试双方的性能差距最高点,因此我们毫不犹豫地决定使用该测试条件(5000batch size,16workers)作出两张以设备台数为横轴的折线图,因为这将极具代表性。(图一代表双方写入相同数据量的所耗秒数,图二代表双方每秒写入的行数。)
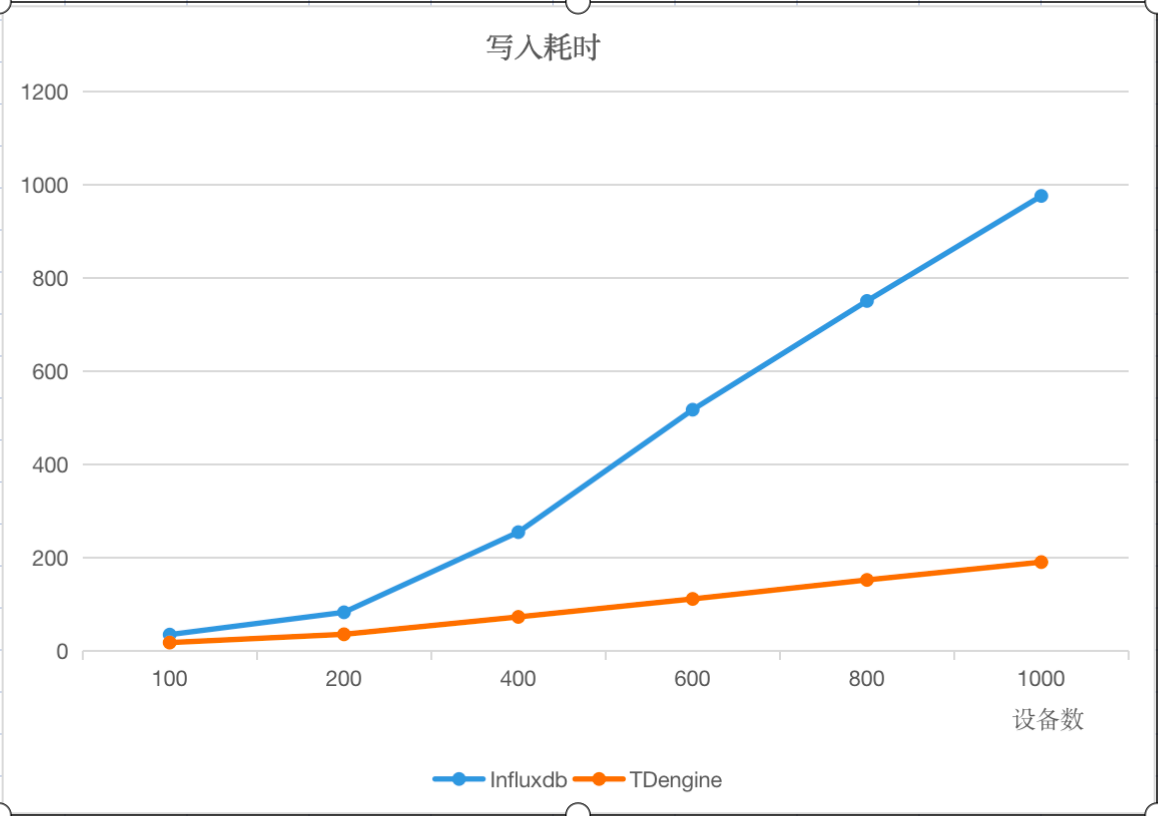
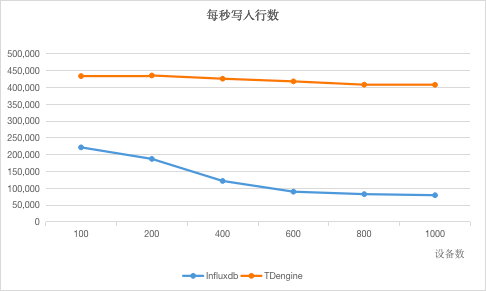
这两张图充分说明了一点:设备数越多,数据量越大,TDengine的优势就越明显,正如成语有云——韩信将兵,多多益善。
而考虑到本次性能测试对比的接口类型并不一致,TDengine采用的是cgo接口而InfluxDB为rest,性能上会有少量浮动,绝不会从根本上改变结果,而后续其他接口以及场景的测试我们也会陆续推出。
如果您对更多细节感兴趣,可以自行使用上文的测试代码自行操作复现,我们将十分欢迎您宝贵的建议。
最后附上测试数据全记录: