1 集成学习的思想
集成学习的思想是将若干个学习器(分类器&回归器)组合之后产生一个新学习器。弱分类器(weak learner)指那些分类准确率只稍微好于随机猜测的分类器(errorrate < 0.5)。
集成算法的成功在于保证弱分类器的多样性(Diversity)。而且集成不稳定的算法也能够得到一个比较明显的性能提升。
常见的集成学习思想有:Bagging、Boosting、Stacking
1.1 Bagging简介
Bagging方法又叫做自举汇聚法(Bootstrap Aggregating),思想:在原始数据集上通过有放回的抽样的方式,重新选择出S个新数据集来分别训练S个分类器的集成技术。也就是说这些模型的训练数据中允许存在重复数据。
Bagging方法训练出来的模型在预测新样本分类的时候,会使用多数投票或者求均值的方式来统计最终的分类结果。
Bagging方法的弱学习器可以是基本的算法模型,eg: Linear、Ridge、Lasso、Logistic、Softmax、ID3、C4.5、CART、SVM、KNN等。
备注:Bagging方式是有放回的抽样,并且每个子集的样本数量必须和原始样本数量一致,但是子集中允许存在重复数据。
Bagging策略的基础改进→RF→RF变种算法Extra Tree/Totally Random Trees Embedding(TRTE)/Isolation Forest
1.2 Boosting简介
提升学习(Boosting)是一种机器学习技术,可以用于回归和分类的问题,它每一步产生弱预测模型(如决策树),并加权累加到总模型中;如果每一步的弱预测模型的生成都是依据损失函数的梯度方式的,那么就称为梯度提升(Gradient boosting);
提升技术的意义:如果一个问题存在弱预测模型,那么可以通过提升技术的办法得到一个强预测模型;
常见的模型有:Adaboost、Gradient Boosting(GBT/GBDT/GBRT)
1.3 Stacking简介
Stacking是指训练一个模型用于组合(combine)其它模型(基模型/基学习器)的技术。即首先训练出多个不同的模型,然后再以之前训练的各个模型的输出作为输入来新训练一个新的模型,从而得到一个最终的模型。一般情况下使用单层的Logistic回归作为组合模型。
2 随机森林(Random Forest)
2.1 算法流程
- 从样本集中用Bootstrap采样选出n个样本;
- 从所有属性中随机选择K个属性,选择出最佳分割属性作为节点创建决策树;
- 重复以上两步m次,即建立m棵决策树;
- 这m个决策树形成随机森林,通过投票表决结果决定数据属于那一类。
2.2 Extra Tree
原理基本和RF一样,区别如下:
- RF会随机采样来作为子决策树的训练集,而Extra Tree每个子决策树采用原始数据集训练;
- RF在选择划分特征点的时候会和传统决策树一样,会基于信息增益、信息增益率、基尼系数、均方差等原则来选择最优特征值;而Extra Tree会随机的选择一个特征值来划分决策树。
Extra Tree因为是随机选择特征值的划分点,这样会导致决策树的规模一般大于RF所生成的决策树。也就是说Extra Tree模型的方差相对于RF进一步减少。在某些情况下,Extra Tree的泛化能力比RF的强。
2.3 TRTE
TRTE(Totally Random Trees Embedding)是一种非监督的数据转化方式。将低维的数据集映射到高维,从而让映射到高维的数据更好的应用于分类回归模型。
TRTE算法的转换过程类似RF算法的方法,建立T个决策树来拟合数据。当决策树构建完成后,数据集里的每个数据在T个决策树中叶子节点的位置就定下来了,将位置信息转换为向量就完成了特征转换操作。
2.4 Isolation Forest(IForest)
IForest是一种异常点检测算法,使用类似RF的方式来检测异常点;IForest算法和RF算法的区别在于:
- 在随机采样的过程中,一般只需要少量数据即可;
- 在进行决策树构建过程中,IForest算法会随机选择一个划分特征,并对划分特征随机选择一个划分阈值;
- IForest算法构建的决策树一般深度max_depth是比较小的。
区别原因:目的是异常点检测,所以只要能够区分异常的即可,不需要大量数据;另外在异常点检测的过程中,一般不需要太大规模的决策树。
对于异常点的判断,则是将测试样本x拟合到T棵决策树上。计算在每棵树上该样本的叶子节点的深度ht(x)。从而计算出平均深度h(x);然后就可以使用下列公式计算样本点x的异常概率值,p(s,m)的取值范围为[0,1],越接近于1,则是异常点的概率越大。

2.5 RF随机森林的优缺点
RF的主要优点:
- 训练可以并行化,对于大规模样本的训练具有速度的优势;
- 由于进行随机选择决策树划分特征列表,这样在样本维度比较高的时候,仍然具有比较高的训练性能;
- 给以给出各个特征的重要性列表;
- 由于存在随机抽样,训练出来的模型方差小,泛化能力强;
- RF实现简单;
- 对于部分特征的缺失不敏感。
RF的主要缺点:
- 在某些噪音比较大的特征上,RF模型容易陷入过拟合;
- 取值比较多的划分特征对RF的决策会产生更大的影响,从而有可能影响模型的效果。
3 AdaBoost
3.1 算法原理
Adaptive Boosting是一种迭代算法。每轮迭代中会在训练集上产生一个新的学习器,然后使用该学习器对所有样本进行预测,以评估每个样本的重要性(Informative)。换句话来讲就是,算法会为每个样本赋予一个权重,每次用训练好的学习器标注/预测各个样本,如果某个样本点被预测的越正确,则将其权重降低;否则提高样本的权重。权重越高的样本在下一个迭代训练中所占的比重就越大,也就是说越难区分的样本在训练过程中会变得越重要。
整个迭代过程直到错误率足够小或者达到一定的迭代次数为止。
Adaboost算法将基分类器的线性组合作为强分类器,同时给分类误差率较小的基本分类器以大的权值,给分类误差率较大的基分类器以小的权重值;构建的线性组合为:
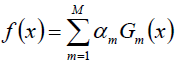
最终分类器是在线性组合的基础上进行Sign函数转换:

3.2 算法的构建过程
- 假设训练数据集T={(X1,Y1),(X2,Y2)....(Xn,Yn)}。
- 初始化训练数据权重分布:
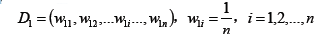
- 使用具有权值分布Dm的训练数据集学习,得到基本分类器:
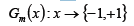
- 计算Gm(x)在训练集上的分类误差:
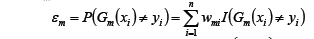
- 计算Gm(x)模型的权重系数αm:
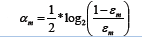
- 权重训练数据集的权值分布:
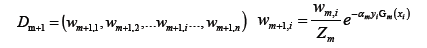
- 这里Z m是规范化因子(归一化):
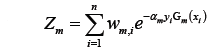
- 构建基本分类器的线性组合:
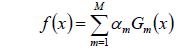
- 得到最终分类器:
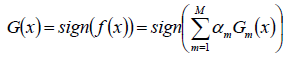
最终目标:
使下面公式达到最小值的αm和Gm就是AdaBoost算法的最终求解值。
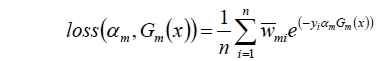
3.3 总结
优点:
- 可以处理连续值和离散值;
- 模型的鲁棒性比较强;
- 解释强,结构简单。
缺点:
对异常样本敏感,异常样本可能会在迭代过程中获得较高的权重值,最终影响模型效果。
4 GBDT
梯度提升迭代决策树(GBDT)也是Boosting算法的一种,和AdaBoost区别如下:
AdaBoost算法是利用前一轮的弱学习器的误差来更新样本权重值,然后一轮一轮的迭代;GBDT也是迭代,但是GBDT要求弱学习器必须是CART模型,而且GBDT在模型训练的时候,是要求模型预测的样本损失尽可能的小。
GBDT由三部分构成:DT(Regression Decistion Tree)、GB(Gradient Boosting)和Shrinkage(衰减)。
由多棵决策树组成,所有树的结果累加起来就是最终结果。
迭代决策树和随机森林的区别:
随机森林使用抽取不同的样本构建不同的子树,也就是说第m棵树的构建和前m-1棵树的结果是没有关系的
迭代决策树在构建子树的时候,使用之前子树构建结果后形成的残差作为输入数据构建下一个子树;然后最终预测的时候按照子树构建的顺序进行预测,并将预测结果相加。
4.1 算法原理
- 给定输入向量X和输出变量Y组成的若干训练样本(X1,Y1),(X2,Y2)......(Xn,Yn),目标是找到近似函数F(X),使得损失函数L(Y,F(X))的损失值最小。
- L损失函数一般采用最小二乘损失函数或者绝对值损失函数。
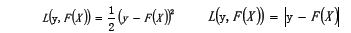
- 最优解为:
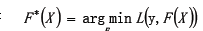
- 假定F(X)是一族最优基函数fi(X)的加权和:

- 以贪心算法的思想扩展得到Fm(X),求解最优f:
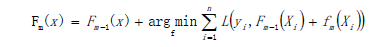
以贪心法在每次选择最优基函数f时仍然困难,使用梯度下降的方法近似计算,给定常数函数F0(X)。
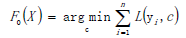
根据梯度下降计算学习率:
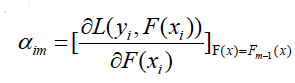
- 使用数据(xi,αim) (i=1……n )计算拟合残差找到一个CART回归树,得到第m棵树:
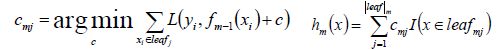
- 更新模型
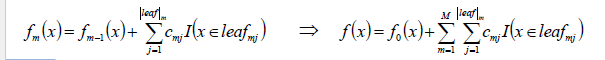
4.2 GBDT回归算法和分类算法
两者唯一的区别就是选择不同的损失函数。
回归算法选择的损失函数一般是均方差(最小二乘)或者绝对值误差;而在分类算法中一般的损失函数选择对数函数来表示。
4.3 总结
GBDT的优点:
- 可以处理连续值和离散值;
- 在相对少的调参情况下,模型的预测效果也会不错;
- 模型的鲁棒性比较强。
GBDT的缺点:
由于弱学习器之间存在关联关系,难以并行训练模型。