MIM攻击原论文地址——https://arxiv.org/pdf/1710.06081.pdf
1.MIM攻击的原理
MIM攻击全称是 Momentum Iterative Method,其实这也是一种类似于PGD的基于梯度的迭代攻击算法。它的本质就是,在进行迭代的时候,每一轮的扰动不仅与当前的梯度方向有关,还与之前算出来的梯度方向相关。其中的衰减因子就是用来调节相关度的,decay_factor在(0,1)之间,decay_factor越小,那么迭代轮数靠前算出来的梯度对当前的梯度方向影响越小。其实仔细想想,这样做也很有道理,由于之前的梯度对后面的迭代也有影响,那么这使得,迭代的方向不会跑偏,使得总体的大方向是对的。到目前为止都是笔者对MIM比较感性的认识,下面贴出论文中比较学术的观点。
其实为了加速梯度下降,通过累积损失函数的梯度方向上的矢量,从而(1)稳定更新(2)有助于通过 narrow valleys, small humps and poor local minima or maxima.(专业名词不知道怎么翻译,可以脑补函数图像,大致意思就是,可以有效避免局部最优)

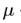 是decay_factor,另外,在原论文中,每一次迭代对x的导数是直接算的1-范数,然后求平均,但在各个算法库以及论文实现的补充中,并没有求平均,估计这个对结果影响不太大。
是decay_factor,另外,在原论文中,每一次迭代对x的导数是直接算的1-范数,然后求平均,但在各个算法库以及论文实现的补充中,并没有求平均,估计这个对结果影响不太大。
2.代码实现(直接把advertorch里的代码贴过来了)


1 class MomentumIterativeAttack(Attack, LabelMixin): 2 """ 3 The L-inf projected gradient descent attack (Dong et al. 2017). 4 The attack performs nb_iter steps of size eps_iter, while always staying 5 within eps from the initial point. The optimization is performed with 6 momentum. 7 Paper: https://arxiv.org/pdf/1710.06081.pdf 8 """ 9 10 def __init__( 11 self, predict, loss_fn=None, eps=0.3, nb_iter=40, decay_factor=1., 12 eps_iter=0.01, clip_min=0., clip_max=1., targeted=False): 13 """ 14 Create an instance of the MomentumIterativeAttack. 15 16 :param predict: forward pass function. 17 :param loss_fn: loss function. 18 :param eps: maximum distortion. 19 :param nb_iter: number of iterations 20 :param decay_factor: momentum decay factor. 21 :param eps_iter: attack step size. 22 :param clip_min: mininum value per input dimension. 23 :param clip_max: maximum value per input dimension. 24 :param targeted: if the attack is targeted. 25 """ 26 super(MomentumIterativeAttack, self).__init__( 27 predict, loss_fn, clip_min, clip_max) 28 self.eps = eps 29 self.nb_iter = nb_iter 30 self.decay_factor = decay_factor 31 self.eps_iter = eps_iter 32 self.targeted = targeted 33 if self.loss_fn is None: 34 self.loss_fn = nn.CrossEntropyLoss(reduction="sum") 35 36 def perturb(self, x, y=None): 37 """ 38 Given examples (x, y), returns their adversarial counterparts with 39 an attack length of eps. 40 41 :param x: input tensor. 42 :param y: label tensor. 43 - if None and self.targeted=False, compute y as predicted 44 labels. 45 - if self.targeted=True, then y must be the targeted labels. 46 :return: tensor containing perturbed inputs. 47 """ 48 x, y = self._verify_and_process_inputs(x, y) 49 50 delta = torch.zeros_like(x) 51 g = torch.zeros_like(x) 52 53 delta = nn.Parameter(delta) 54 55 for i in range(self.nb_iter): 56 57 if delta.grad is not None: 58 delta.grad.detach_() 59 delta.grad.zero_() 60 61 imgadv = x + delta 62 outputs = self.predict(imgadv) 63 loss = self.loss_fn(outputs, y) 64 if self.targeted: 65 loss = -loss 66 loss.backward() 67 68 g = self.decay_factor * g + normalize_by_pnorm( 69 delta.grad.data, p=1) 70 # according to the paper it should be .sum(), but in their 71 # implementations (both cleverhans and the link from the paper) 72 # it is .mean(), but actually it shouldn't matter 73 74 delta.data += self.eps_iter * torch.sign(g) 75 # delta.data += self.eps / self.nb_iter * torch.sign(g) 76 77 delta.data = clamp( 78 delta.data, min=-self.eps, max=self.eps) 79 delta.data = clamp( 80 x + delta.data, min=self.clip_min, max=self.clip_max) - x 81 82 rval = x + delta.data 83 return rval
个人觉得,advertorch中在迭代过程中,应该是对imgadv求导,而不是对delta求导,笔者查看了foolbox和cleverhans的实现,都是对每一轮的对抗样本求导,大家自己实现的时候可以改一下。