慕课:《深度学习应用开发-TensorFlow实践》
章节:第十一讲 Deep Dream:理解深度神经网络结构及应用
TensorFlow版本为2.3
Deep Dream技术原理简述
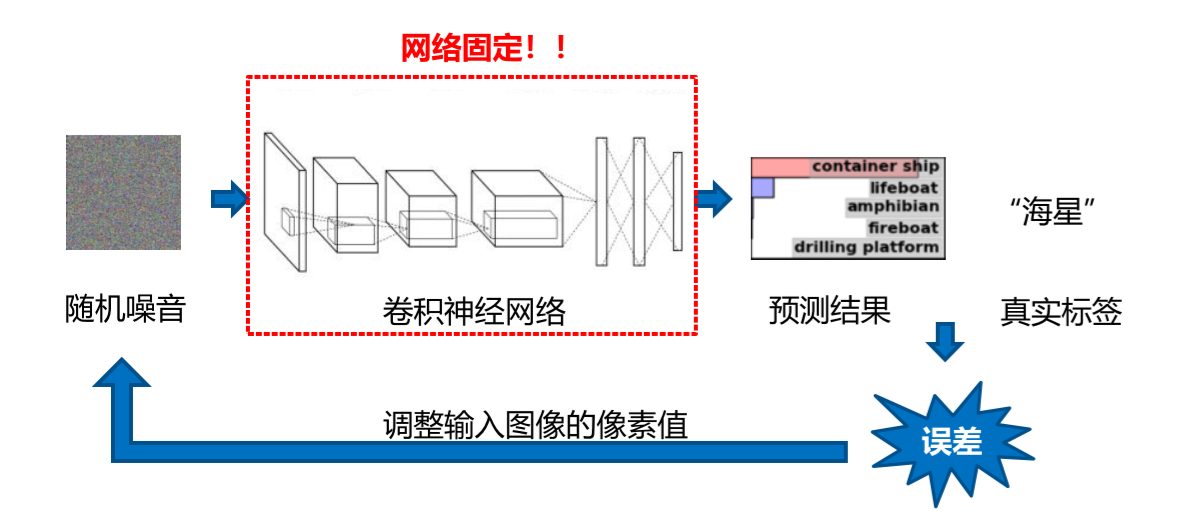
用一个已经训练好的卷积神经网络(eg.通过ImageNet训练的CNN网络)去做随机噪音图像的优化,得到计算的结果。通过不断优化调整随机噪音图片,来得到我们想要的结果
噪音图像起点单层网络单通道
导入库函数
首先还是导入库函数,并查看GPU是否可用(如果是CPU版本的可以忽略)
import tensorflow as tf
import numpy as np
import IPython.display as display
import PIL.Image
from tensorflow.keras.preprocessing import image
print(tf.__version__)
# 查看GPU是否可以使用
print(f'GPU is ', tf.config.list_physical_devices('GPU'))

这样就说明库导入成功且GPU可用
定义图像相关函数
图像标准化
def normalize_image(img):
img=255*(img+1.0)/2.0
return tf.cast(img,tf.uint8)
图像可视化
def show_image(img):
display.display(PIL.Image.fromarray(np.array(img)))
保存图像文件
def save_image(img,file_name):
PIL.Image.fromarray(np.array(img)).save(file_name)
产生噪声图像
img_noise=np.random.uniform(size=(300,300,3))+100.0
img_noise=img_noise.astype(np.float32)
show_image(normalize_image(img_noise))
生成出来的图片大概长这样

加载预训练模型
我们所选用的是ImageNet数据集的图像识别预训练InceptionV3模型,在我们使用的时候,我们去掉它的顶层,这样我们就可以自己定义输入图片的size
base_model = tf.keras.applications.InceptionV3(include_top=False,weights='imagenet')
base_model.summary()
我们可以用代码来加载,首次运行它会自动的去下载模型,如果网络出错,也可以手动下载然后放到对应的文件夹下就好。加载完后我们可以看看他的模型结构
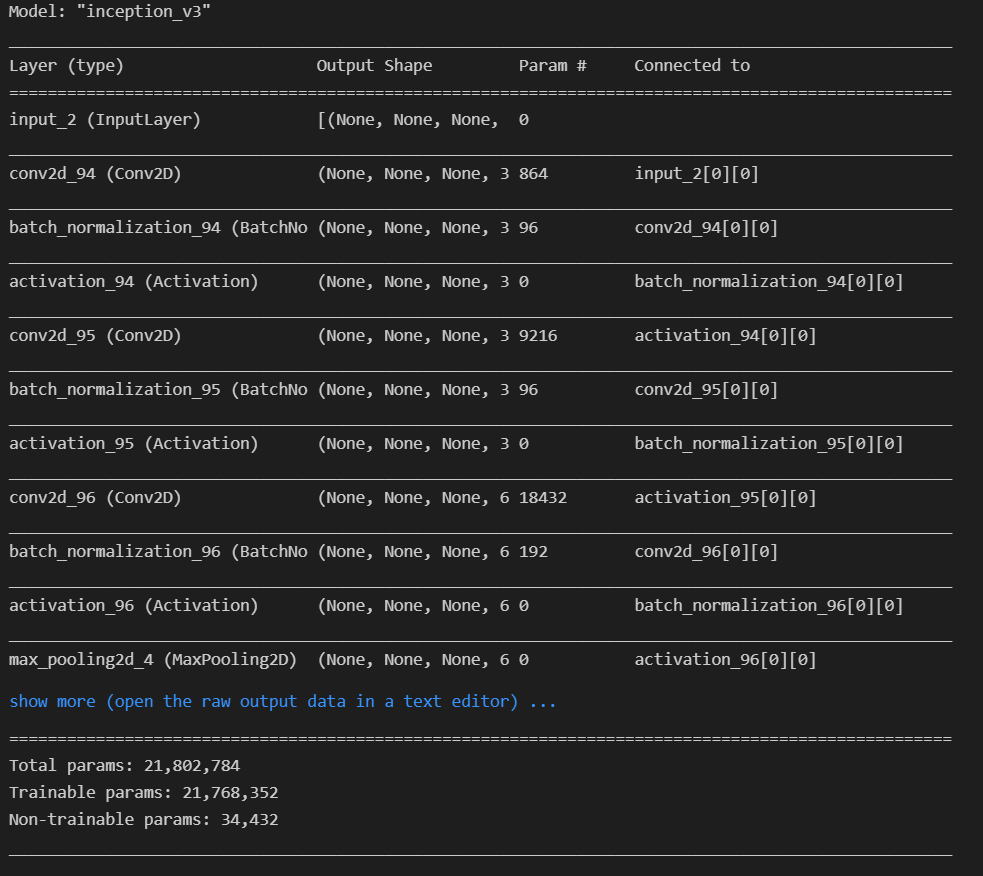
他的模型结构还是比较复杂的,这里也就只看一小部分。
选择卷积层和通道
DeepDream的主要想法是选择一个卷积层的某个通道或者卷积层(也可以是多个网络层),改变图像像素(与训练分类器最大的区别),来最大化选中层或通道的激活值。
# 确定需要最大化激活的卷积层
layer_name='conv2d_95'
layers=base_model.get_layer(layer_name).output
layers
输出结果
<tf.Tensor 'conv2d_95/Identity:0' shape=(None, None, None, 32) dtype=float32>
创建特征提取模型
dream_model=tf.keras.Model(inputs=base_model.input,outputs=layers)
dream_model.summary()
这个模型的输入就是base_model的输入,输出就是我们选择的那一层的输出
然后我们可以看到我们现在的这个模型,这个模型就比原来的模型小很多了。
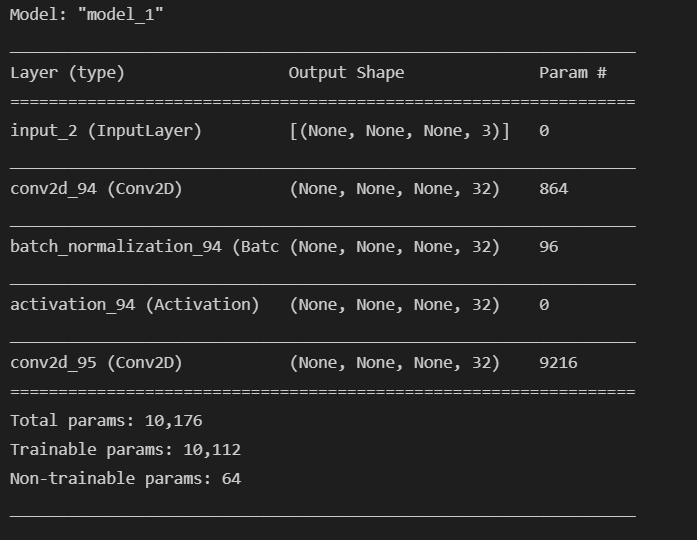
计算损失
def calc_loss(img,model):
channel=13# 选中第13通道,可以随意但要小于选中曾的通道数
# image:(300,300,3)->(1.300.300.3)
img=tf.expand_dims(img,axis=0)
# 图像前向传播得到结果
layer_activations=model(img)
# 取选中通道值
act=layer_activations[:,:,:,channel]
# 选中通道输出结果求平均
loss=tf.math.reduce_mean(act)
return loss
定义图像优化过程
通过梯度上升进行图像调整,该图像会越来越多地“激活”模型中的指定层和通道的信息。
# 定义图像优化过程
def render_deepdream(model,img,steps=100,step_size=0.01,verbose=1):
for n in tf.range(steps):
with tf.GradientTape() as tape:
tape.watch(img)
loss=calc_loss(img,model)
gradients=tape.gradient(loss,img)
gradients/=tf.math.reduce_std(gradients)+1e-8
img=img+gradients*step_size
img=tf.clip_by_value(img,-1,1)
if (verbose==1):
if ((n+1)%10==0):
print(f'Step {n+1}/{steps}, loss={loss}')
return img
接下来就是正式的“做梦”环节了
“做梦”
import time
# 产生噪声图像
img_noise=np.random.uniform(size=(300,300,3))+100.0
img_noise=img_noise.astype(np.float32)
show_image(normalize_image(img_noise))
img=tf.keras.applications.inception_v3.preprocess_input(img_noise)
img=tf.convert_to_tensor(img)
start=time.time()
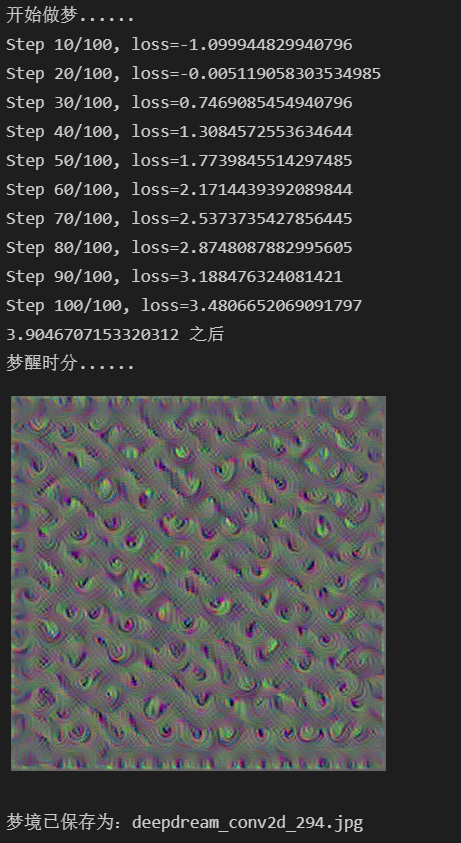
print('开始做梦......')
dream_img=render_deepdream(dream_model,img,steps=100,step_size=0.01)
end=time.time()
print(f'{end-start} 之后')
print('梦醒时分......')
dream_img=normalize_image(dream_img)
show_image(dream_img)
file_name=f'out_image/deepdream_{layer_name}.jpg'
save_image(dream_img,file_name=file_name)
print(f'梦境已保存为:deepdream_{layer_name}.jpg')
它的输出差不多长这个样子
噪音图像起点单层网络多通道
我们只需要修改损失,改为多通道总和
def calc_loss(img,model):
channel=[13,50]# 选中通道列表
# image:(300,300,3)->(1.300.300.3)
img=tf.expand_dims(img,axis=0)
# 图像前向传播得到结果
layer_activations=model(img)
losses=[]
for cn in channel:
act=layer_activations[:,:,:,cn]
loss=tf.math.reduce_mean(act)
losses.append(loss)
return tf.reduce_sum(losses)
其他不变,再次运行上面做梦的代码,得到我们的结果
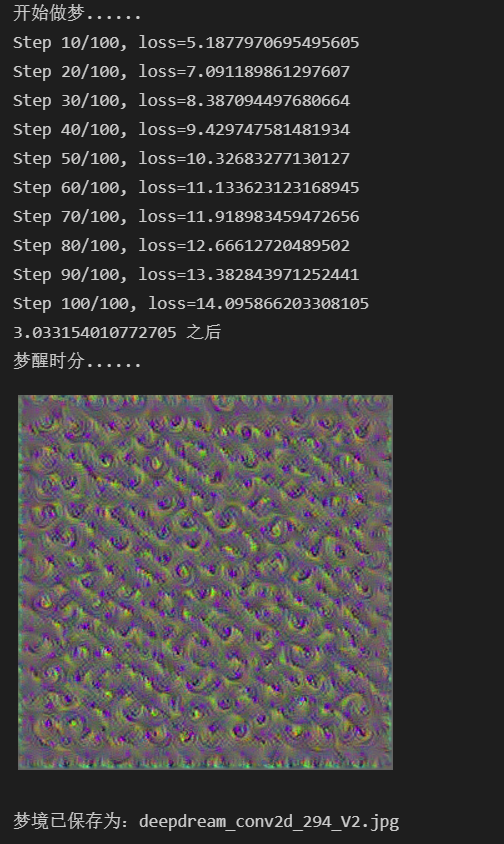
噪音图像起点多层网络全通道
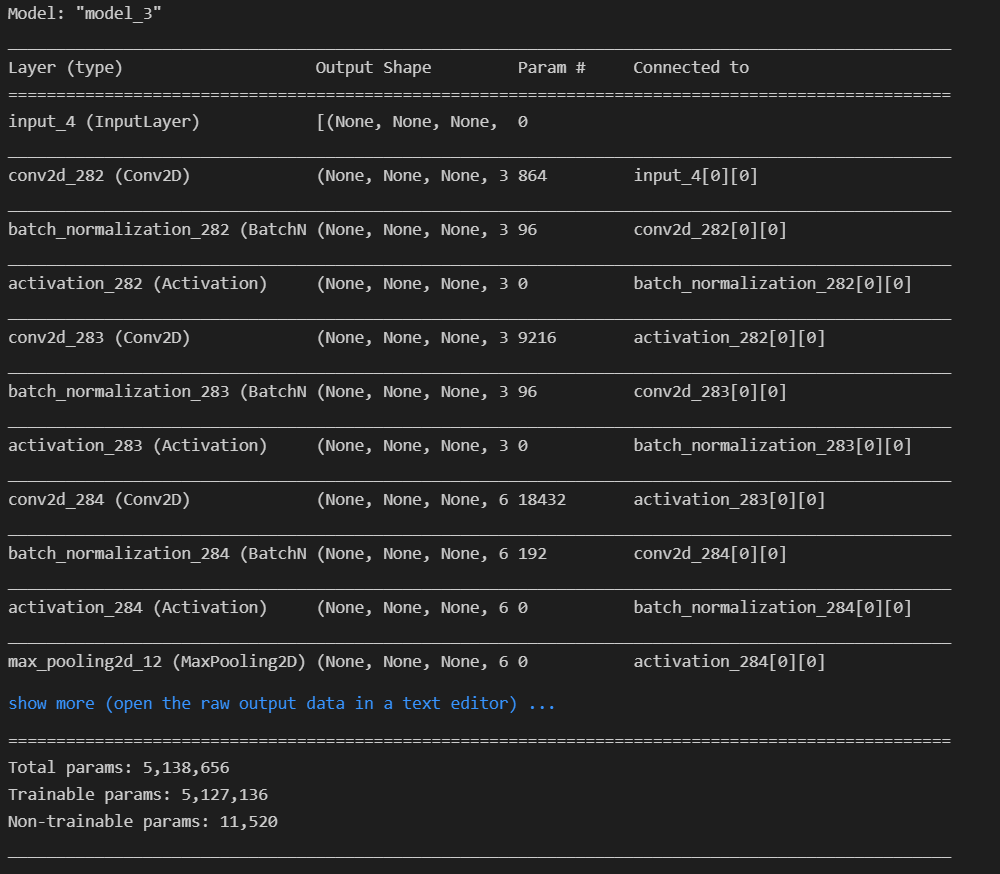
这里的话,修改选择卷积层和通道,以及我们的损失函数
# 确定需要最大化激活的卷积层
layer_name=['mixed3','mixed5']
layers=[base_model.get_layer(name).output for name in layer_name]
# 创建特征提取模型
dream_model=tf.keras.Model(inputs=base_model.input,outputs=layers)
dream_model.summary()
损失的话,改成这个样子
def calc_loss(img,model):
# image:(300,300,3)->(1.300.300.3)
img=tf.expand_dims(img,axis=0)
# 图像前向传播得到结果
layer_activations=model(img)
losses=[]
for act in layer_activations:
loss=tf.math.reduce_mean(act)
losses.append(loss)
return tf.reduce_sum(losses)
然后继续做梦
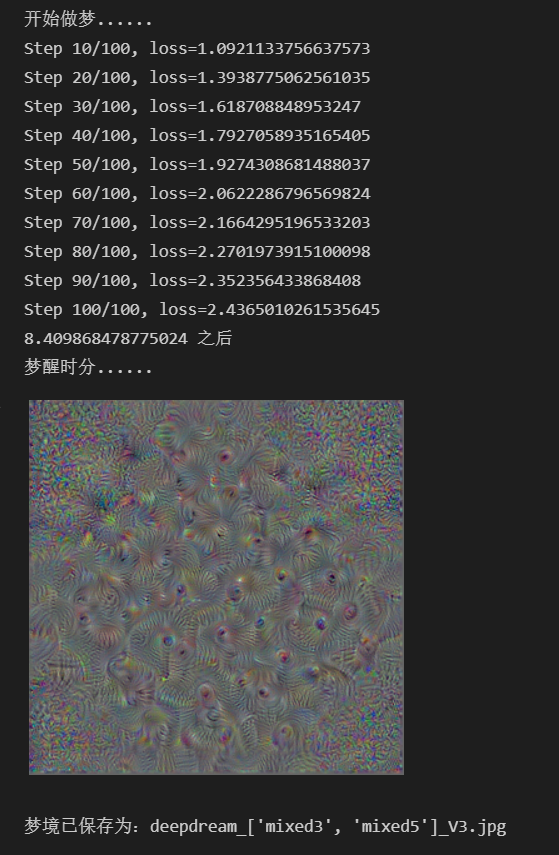
背景图像起点多层网络全通道
定义读取图像文件函数,可以设置图像最大尺寸
# 定义读取图像文件函数,可以设置图像最大尺寸
def read_image(file_name,max_dim=None):
img=PIL.Image.open(file_name)
if max_dim:
img.thumbnail((max_dim,max_dim))
return np.array(img)
读取待处理图像文件
image_file='mountain.jpg'
original_img=read_image(image_file,max_dim=500)
show_image(original_img)
得到结果就是一张图像

“做梦”
然后我们执行多层网络全通道的做梦
import time
img=tf.keras.applications.inception_v3.preprocess_input(original_img)
img=tf.convert_to_tensor(img)
start=time.time()
print('开始做梦......')
dream_img=render_deepdream(dream_model,img,steps=200,step_size=0.01)
end=time.time()
print(f'{end-start} 之后')
print('梦醒时分......')
dream_img=normalize_image(dream_img)
show_image(dream_img)
file_name=f'out_image/deepdream_{layer_name}_V.jpg'
save_image(dream_img,file_name=file_name)
print(f'梦境已保存为:deepdream_{layer_name}_V3.jpg')
结果就是下面这个样子(前半段太长了就没截到)
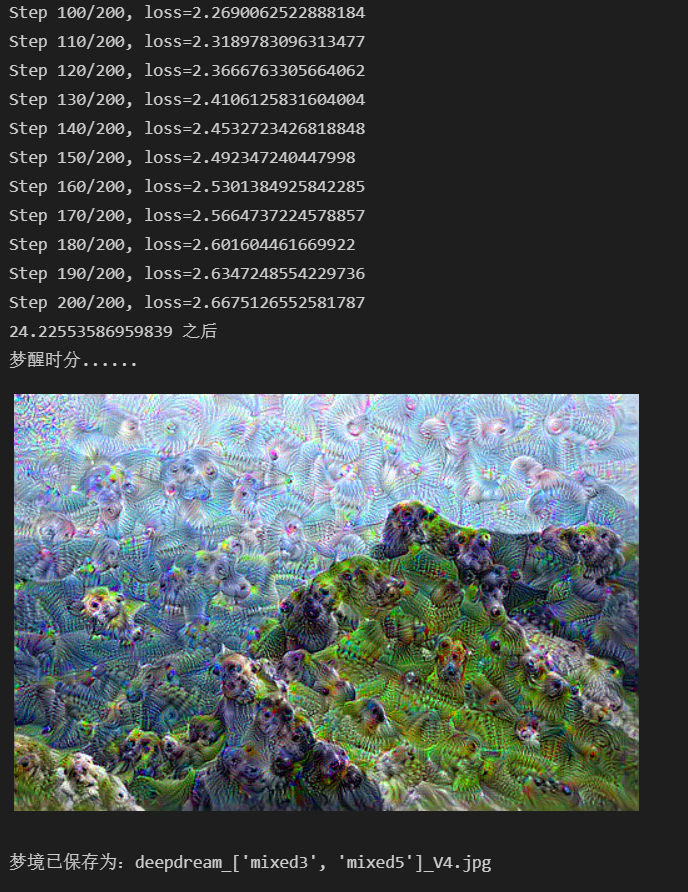
优化1
存在的问题
上面生成的图像有以下几个问题:
- 输出有噪声
-
- 图像分辨率低
-
- 输出的特征模式都一样
解决方案:
可以在不同比例的图上使用梯度上升来解决这些问题,并在小比例上图生成的结果合并到到更大比例的图上。
实现
我们可以设置不同比例迭代进行
import time
start=time.time()
OCTAVE_SCALE=1.30
img=tf.keras.applications.inception_v3.preprocess_input(original_img)
img=tf.convert_to_tensor(img)
initial_shape=tf.shape(img)[:-1]
for octave in range(-2,3):
new_size=tf.cast(tf.convert_to_tensor(initial_shape),tf.float32)+(OCTAVE_SCALE**octave)
img=tf.image.resize(img,tf.cast(new_size,tf.int32))
img=render_deepdream(dream_model,img,steps=30,step_size=0.01)
img=tf.image.resize(img,initial_shape)
img=normalize_image(img)
show_image(dream_img)
end=time.time()
print(f'耗时:{end-start}')
file_name=f'out_image/deepdream_{layer_name}_V4_1.jpg'
save_image(dream_img,file_name=file_name)
print(f'梦境已保存为:deepdream_{layer_name}_V4_1.jpg')

优化2
存在的问题
如果单幅图像尺寸过大,执行梯度计算所需的时间和内存也会随之增加,有的 机器可能无法支持
解决方案:
可以将图像拆分为多个小图块计算梯度,最后将其拼合起来,得到最终图像
实现
定义图像切分移动函数
# 定义图像切分移动函数
def random_roll(img,maxroll=512):
shift=tf.random.uniform(shape=[2],minval=-maxroll,maxval=maxroll,dtype=tf.int32)
print(shift)
shift_down,shift_right=shift[0],shift[1]
print(shift_down,shift_right)
img_rolled=tf.roll(tf.roll(img,shift_right,axis=1),shift_down,axis=0)
return shift_down,shift_right,img_rolled
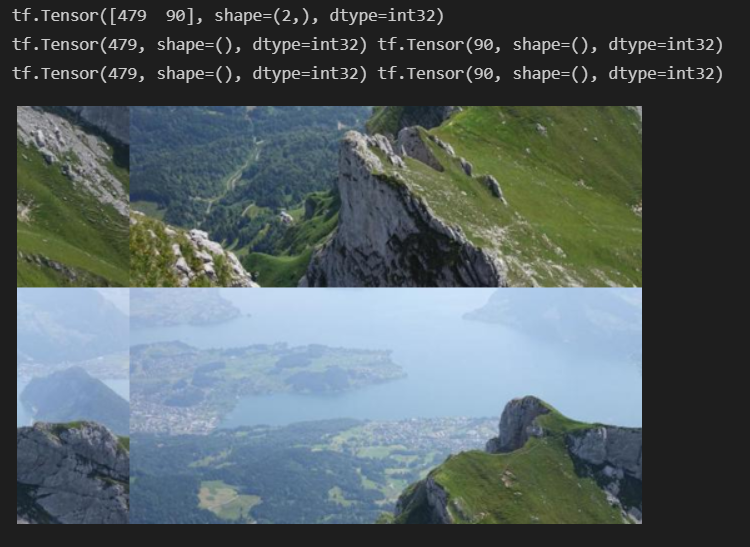
可以看一下效果
shift_down,shift_right,img_rolled=random_roll(np.array(original_img),512)
print(shift_down,shift_right)
show_image(img_rolled)
定义分块计算梯度函数
# 定义分块计算梯度函数
def get_tiled_gradients(model, img, tile_size=150):
shift_down, shift_right, img_rolled=random_roll(img, tile_size)
#初始化梯度为0
gradients = tf.zeros_like(img_rolled)
#产生分块坐标列表
xs= tf.range(0, img_rolled.shape [0], tile_size)
ys= tf.range(0, img_rolled.shape [1], tile_size)
for x in xs:
for y in ys:
# 计算该图块的梯度
with tf.GradientTape() as tape:
tape.watch(img_rolled)
#从图像中提取该图块,最后一块大小会按实际提取
img_tile= img_rolled [x: x+tile_size, y: y+tile_size]
loss=calc_loss(img_tile, model)
# 更新图像的梯度
gradients=gradients+tape.gradient(loss, img_rolled)
#将图块放回原来的位置
gradients=tf.roll(tf.roll (gradients, -shift_right, axis=1), -shift_down, axis=0)
#归一化梯度
gradients/= tf.math.reduce_std(gradients)+ 1e-8
return gradients
定义优化后的“做梦”函数
# 定义图像优化过程
def render_deepdream_with_octaves(model,img,steps_per_octave=100,step_size=0.01,octaves=range(-2,3),octave_scale=1.3):
initial_shape=img.shape[:-1]
for octave in octaves:
new_size=tf.cast(tf.convert_to_tensor(initial_shape),tf.float32)*(octave_scale**octave)
img=tf.image.resize(img,tf.cast(new_size,tf.int32))
for step in range(steps_per_octave):
gradients=get_tiled_gradients(model,img)
img=img+gradients*step_size
img=tf.clip_by_value(img,-1,1)
if ((step+1)%10==0):
print(f'octave {octave},Step {step+1}')
img=tf.image.resize(img,initial_shape)
result=normalize_image(img)
return result
做梦
import time
start=time.time()
print('开始做梦......')
img=tf.keras.applications.inception_v3.preprocess_input(original_img)
img=tf.convert_to_tensor(img)
img=render_deepdream_with_octaves(dream_model,img,steps_per_octave=50,step_size=0.01,octaves=range(-2,3),octave_scale=1.3)
show_image(img)
end=time.time()
print(f'{end-start} 之后')
print('梦醒时分......')
file_name=f'out_image/deepdream_{layer_name}_V4_2.jpg'
save_image(img,file_name=file_name)
print(f'梦境已保存为:deepdream_{layer_name}_V4_2.jpg')
学习笔记,仅供参考,如有错误,敬请指正!