1.regexp:正则表达式

如上输出: like匹配整列,而regexp在列值内进行匹配,如果被匹配的文本在列值中出现,regexp就会找到它 2.binary:进行区分大小写的匹配

3.进行or匹配

4.匹配指定的字符 通过使用一组[]即可完成特定的字符匹配
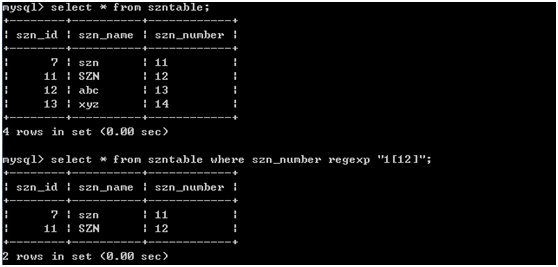
相对应的使用[^]可以进行匹配指定字符外的其他任何字符

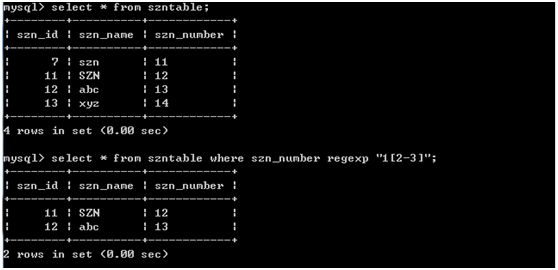
5.匹配范围
6.匹配特殊字符 使用.可以匹配任意字符

为了匹配那些特殊字符,比如 . [] | - 等需要使用\来进行转义
7.匹配多个实例
* 0个或多个匹配
+ 1个或多个匹配,等价于{1, }
? 0个或1个匹配,等价于{0,1}
{n} 指定数目的匹配 括号内别加空格
{n,} 不少于指定数目的匹配 括号内别加空格
{n,m}匹配数目的范围 m不超过255 括号内别加空格



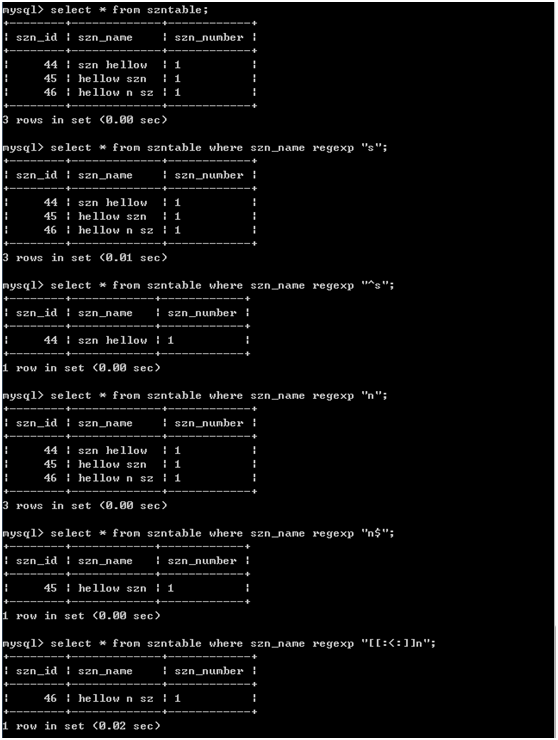
8.定位符 ^ 文本的开始 注意点:^有两个用途,在集合中[^]表示否定集合 $ 文本的结尾 [[:<:]] 词的开始 [[:>:]] 词的结尾

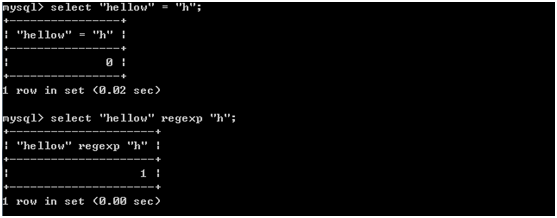
9.不使用数据库表的select语句
10.匹配字符类: [:alnum:] 任意字母和数字 [:alpha:] 任意字母 [:blank:] 空格和制表 [:cntrl:] ASCII控制字符 ASCII 0-31 127 [:digit:] 数字 [:graph:] 可打印字符不包括空格 [:lower:] 小写字母 [:print:] 可打印字母 [:punct:] 标点 [:space:] \f \n \r \t \v(垂直制表符) 空格 [:upper:] 大写字母 [:xdigit:] 十六进制数字
