
在编写高效 SQL 时,你可能遇到的最有影响的事情就是索引。但是,一个很重要的事实就是很多 SQL 客户端要求数据库做很多“不必要的强制性工作”。
跟我再重复一遍:
不必要的强制性工作
什么是“不必要的强制性工作”?这个意思包括两个方面:
不必要的
假设你的客户端应用程序需要这些信息:
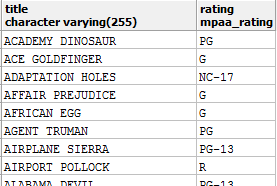
这没什么特别的。我们运行着一个电影数据库(例如 Sakila 数据库),我们想要给用户显示每部电影的名称和评分。
这是能产生上面结果的查询:
- SELECT title, rating
- FROM film
然而,我们的应用程序(或者我们的 ORM(LCTT 译注:对象关系映射(Object-Relational Mapping)))运行的查询却是:
- SELECT *
- FROM film
我们得到什么?猜一下。我们得到很多无用的信息:

甚至一些复杂的 JSON 数据全程在下列环节中加载:
- 从磁盘
- 加载到缓存
- 通过总线
- 进入客户端内存
- 然后被丢弃
是的,我们丢弃了其中大部分的信息。检索它所做的工作完全就是不必要的。对吧?没错。
强制性
这是最糟糕的部分。现今随着优化器变得越来越聪明,这些工作对于数据库来说都是强制执行的。数据库没有办法知道客户端应用程序实际上不需要其中 95% 的数据。这只是一个简单的例子。想象一下如果我们连接更多的表...
你想想那会怎样呢?数据库还快吗?让我们来看看一些之前你可能没有想到的地方:
内存消耗
当然,单次执行时间不会变化很大。可能是慢 1.5 倍,但我们可以忍受,是吧?为方便起见,有时候确实如此。但是如果你每次都为了方便而牺牲性能,这事情就大了。我们不说性能问题(单个查询的速度),而是关注在吞吐量上时(系统响应时间),事情就变得困难而难以解决。你就会受阻于规模的扩大。
让我们来看看执行计划,这是 Oracle 的:
- --------------------------------------------------
- | Id | Operation | Name | Rows | Bytes |
- --------------------------------------------------
- | 0 | SELECT STATEMENT | | 1000 | 166K|
- | 1 | TABLE ACCESS FULL| FILM | 1000 | 166K|
- --------------------------------------------------
对比一下:
- --------------------------------------------------
- | Id | Operation | Name | Rows | Bytes |
- --------------------------------------------------
- | 0 | SELECT STATEMENT | | 1000 | 20000 |
- | 1 | TABLE ACCESS FULL| FILM | 1000 | 20000 |
- --------------------------------------------------
当执行 SELECT * 而不是 SELECT film, rating 的时候,我们在数据库中使用了 8 倍之多的内存。这并不奇怪,对吧?我们早就知道了。在很多我们并不需要其中全部数据的查询中我们都是这样做的。我们为数据库产生了不必要的强制性工作,其后果累加了起来,就是我们使用了多达 8 倍的内存(当然,数值可能有些不同)。
而现在,所有其它的步骤(比如,磁盘 I/O、总线传输、客户端内存消耗)也受到相同的影响,我这里就跳过了。另外,我还想看看...
索引使用
如今大部分数据库都有涵盖索引(LCTT 译注:covering index,包括了你查询所需列、甚至更多列的索引,可以直接从索引中获取所有需要的数据,而无需访问物理表)的概念。涵盖索引并不是特殊的索引。但对于一个特定的查询,它可以“意外地”或人为地转变为一个“特殊索引”。
看看这个查询:
- SELECT *
- FROM actor
- WHERE last_name LIKE 'A%'
执行计划中没有什么特别之处。它只是个简单的查询。索引范围扫描、表访问,就结束了:
- -------------------------------------------------------------------
- | Id | Operation | Name | Rows |
- -------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 8 |
- | 1 | TABLE ACCESS BY INDEX ROWID| ACTOR | 8 |
- |* 2 | INDEX RANGE SCAN | IDX_ACTOR_LAST_NAME | 8 |
- -------------------------------------------------------------------
这是个好计划吗?如果我们只是想要这些,那么它就不是:
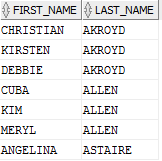
当然,我们浪费了内存之类的。再来看看这个查询:
- SELECT first_name, last_name
- FROM actor
- WHERE last_name LIKE 'A%'
它的计划是:
- ----------------------------------------------------
- | Id | Operation | Name | Rows |
- ----------------------------------------------------
- | 0 | SELECT STATEMENT | | 8 |
- |* 1 | INDEX RANGE SCAN| IDX_ACTOR_NAMES | 8 |
- ----------------------------------------------------
现在我们可以完全消除表访问,因为有一个索引涵盖了我们查询需要的所有东西……一个涵盖索引。这很重要吗?当然!这种方法可以将你的某些查询加速一个数量级(如果在某个更改后你的索引不再涵盖,可能会降低一个数量级)。
你不能总是从涵盖索引中获利。索引也有它们自己的成本,你不应该添加太多索引,例如像这种情况就是不明智的。让我们来做个测试:
- SET SERVEROUTPUT ON
- DECLARE
- v_ts TIMESTAMP;
- v_repeat CONSTANT NUMBER := 100000;
- BEGIN
- v_ts := SYSTIMESTAMP;
- FOR i IN 1..v_repeat LOOP
- FOR rec IN (
- -- Worst query: Memory overhead AND table access
- SELECT *
- FROM actor
- WHERE last_name LIKE 'A%'
- ) LOOP
- NULL;
- END LOOP;
- END LOOP;
- dbms_output.put_line('Statement 1 : ' || (SYSTIMESTAMP - v_ts));
- v_ts := SYSTIMESTAMP;
- FOR i IN 1..v_repeat LOOP
- FOR rec IN (
- -- Better query: Still table access
- SELECT /*+INDEX(actor(last_name))*/
- first_name, last_name
- FROM actor
- WHERE last_name LIKE 'A%'
- ) LOOP
- NULL;
- END LOOP;
- END LOOP;
- dbms_output.put_line('Statement 2 : ' || (SYSTIMESTAMP - v_ts));
- v_ts := SYSTIMESTAMP;
- FOR i IN 1..v_repeat LOOP
- FOR rec IN (
- -- Best query: Covering index
- SELECT /*+INDEX(actor(last_name, first_name))*/
- first_name, last_name
- FROM actor
- WHERE last_name LIKE 'A%'
- ) LOOP
- NULL;
- END LOOP;
- END LOOP;
- dbms_output.put_line('Statement 3 : ' || (SYSTIMESTAMP - v_ts));
- END;
- /
结果是:
- Statement 1 : +000000000 00:00:02.479000000
- Statement 2 : +000000000 00:00:02.261000000
- Statement 3 : +000000000 00:00:01.857000000
注意,表 actor 只有 4 列,因此语句 1 和 2 的差别并不是太令人印象深刻,但仍然很重要。还要注意我使用了 Oracle 的提示来强制优化器为查询选择一个或其它索引。在这种情况下语句 3 明显胜利。这是一个好很多的查询,也是一个十分简单的查询。
当我们写 SELECT * 语句时,我们为数据库带来了不必要的强制性工作,这是无法优化的。它不会使用涵盖索引,因为比起它所使用的 LAST_NAME 索引,涵盖索引开销更多一点,不管怎样,它都要访问表以获取无用的 LAST_UPDATE 列。
使用 SELECT * 会变得更糟。考虑一下……
SQL 转换
优化器工作的很好,因为它们转换了你的 SQL 查询(看我最近在 Voxxed Days Zurich 关于这方面的演讲)。例如,其中有一个称为“表连接消除”的转换,它真的很强大。看看这个辅助视图,我们写了这个视图是因为我们非常讨厌总是连接所有这些表:
- CREATE VIEW v_customer AS
- SELECT
- c.first_name, c.last_name,
- a.address, ci.city, co.country
- FROM customer c
- JOIN address a USING (address_id)
- JOIN city ci USING (city_id)
- JOIN country co USING (country_id)
这个视图仅仅是把 CUSTOMER 和他们不同的 ADDRESS 部分所有“对一”关系连接起来。谢天谢地,它很工整。
现在,使用这个视图一段时间之后,想象我们非常习惯这个视图,我们都忘了所有它底层的表。然后,我们运行了这个查询:
- SELECT *
- FROM v_customer
我们得到了一个相当令人印象深刻的计划:
- ----------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost |
- ----------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 599 | 47920 | 14 |
- |* 1 | HASH JOIN | | 599 | 47920 | 14 |
- | 2 | TABLE ACCESS FULL | COUNTRY | 109 | 1526 | 2 |
- |* 3 | HASH JOIN | | 599 | 39534 | 11 |
- | 4 | TABLE ACCESS FULL | CITY | 600 | 10800 | 3 |
- |* 5 | HASH JOIN | | 599 | 28752 | 8 |
- | 6 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
- | 7 | TABLE ACCESS FULL| ADDRESS | 603 | 17487 | 3 |
- ----------------------------------------------------------------
当然是这样。我们运行了所有这些表连接以及全表扫描,因为这就是我们让数据库去做的:获取所有的数据。
现在,再一次想一下,对于一个特定场景,我们真正想要的是:
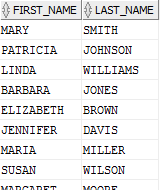
是啊,对吧?现在你应该知道我的意图了。但想像一下,我们确实从前面的错误中学到了东西,现在我们实际上运行下面一个比较好的查询:
- SELECT first_name, last_name
- FROM v_customer
再来看看结果!
- ------------------------------------------------------------------
- | Id | Operation | Name | Rows | Bytes | Cost |
- ------------------------------------------------------------------
- | 0 | SELECT STATEMENT | | 599 | 16173 | 4 |
- | 1 | NESTED LOOPS | | 599 | 16173 | 4 |
- | 2 | TABLE ACCESS FULL| CUSTOMER | 599 | 11381 | 4 |
- |* 3 | INDEX UNIQUE SCAN| SYS_C007120 | 1 | 8 | 0 |
- ------------------------------------------------------------------
这是执行计划一个极大的进步。我们的表连接被消除了,因为优化器可以证明它们是不必要的,因此一旦它可以证明这点(而且你不会因使用 select * 而使其成为强制性工作),它就可以移除这些工作并不执行它。为什么会发生这种情况?
每个 CUSTOMER.ADDRESS_ID 外键保证了有且只有一个 ADDRESS.ADDRESS_ID 主键值,因此可以保证 JOIN 操作是对一连接,它不会产生或者删除行。如果我们甚至不选择行或查询行,当然我们就不需要真正地去加载行。可以证实地移除 JOIN 并不会改变查询的结果。
数据库总是会做这些事情。你可以在大部分数据库上尝试它:
- -- Oracle
- SELECT CASE WHEN EXISTS (
- SELECT 1 / 0 FROM dual
- ) THEN 1 ELSE 0 END
- FROM dual
- -- 更合理的 SQL 语句,例如 PostgreSQL
- SELECT EXISTS (SELECT 1 / 0)
在这种情况下,当你运行这个查询时你可能预料到会抛出算术异常:
- SELECT 1 / 0 FROM dual
产生了:
- ORA-01476: divisor is equal to zero
但它并没有发生。优化器(甚至解析器)可以证明 EXISTS (SELECT ..) 谓词内的任何 SELECT 列表达式不会改变查询的结果,因此也就没有必要计算它的值。呵!
同时……
大部分 ORM 最不幸问题就是事实上他们很随意就写出了 SELECT * 查询。事实上,例如 HQL / JPQL,就设置默认使用它。你甚至可以完全抛弃 SELECT 从句,因为毕竟你想要获取所有实体,正如声明的那样,对吧?
例如:
FROM v_customer
例如 Vlad Mihalcea(一个 Hibernate 专家和 Hibernate 开发倡导者)建议你每次确定不想要在获取后进行任何更改时再使用查询。ORM 使解决对象图持久化问题变得简单。注意:持久化。真正修改对象图并持久化修改的想法是固有的。
但如果你不想那样做,为什么要抓取实体呢?为什么不写一个查询?让我们清楚一点:从性能角度,针对你正在解决的用例写一个查询总是会胜过其它选项。你可以不会在意,因为你的数据集很小,没关系。可以。但最终,你需要扩展并重新设计你的应用程序以便在强制实体图遍历之上支持查询语言,就会变得很困难。你也需要做其它事情。
计算出现次数
资源浪费最严重的情况是在只是想要检验存在性时运行 COUNT(*) 查询。例如:
这个用户有没有订单?
我们会运行:
- SELECT count(*)
- FROM orders
- WHERE user_id = :user_id
很简单。如果 COUNT = 0:没有订单。否则:是的,有订单。
性能可能不会很差,因为我们可能有一个 ORDERS.USER_ID 列上的索引。但是和下面的这个相比你认为上面的性能是怎样呢:
- -- Oracle
- SELECT CASE WHEN EXISTS (
- SELECT *
- FROM orders
- WHERE user_id = :user_id
- ) THEN 1 ELSE 0 END
- FROM dual
- -- 更合理的 SQL 语句,例如 PostgreSQL
- SELECT EXISTS (
- SELECT *
- FROM orders
- WHERE user_id = :user_id
- )
它不需要火箭科学家来确定,一旦它找到一个,实际存在谓词就可以马上停止寻找额外的行。因此,如果答案是“没有订单”,速度将会是差不多。但如果结果是“是的,有订单”,那么结果在我们不计算具体次数的情况下就会大幅加快。
因为我们不在乎具体的次数。我们告诉数据库去计算它(不必要的),而数据库也不知道我们会丢弃所有大于 1 的结果(强制性)。
当然,如果你在 JPA 支持的集合上调用 list.size() 做同样的事情,情况会变得更糟!
近期我有关于该情况的博客以及在不同数据库上的测试。去看看吧。
总结
这篇文章的立场很“明显”。别让数据库做不必要的强制性工作。
它不必要,因为对于你给定的需求,你知道一些特定的工作不需要完成。但是,你告诉数据库去做。
它强制性,因为数据库无法证明它是不必要的。这些信息只包含在客户端中,对于服务器来说无法访问。因此,数据库需要去做。
这篇文章大部分在介绍 SELECT *,因为这是一个很简单的目标。但是这并不仅限于数据库。这关系到客户端要求服务器完成不必要的强制性工作的任何分布式算法。你的 AngularJS 应用程序平均有多少个 N+1 问题,UI 在服务结果 A 上循环,多次调用服务 B,而不是把所有对 B 的调用打包为一个调用?这是一个复发的模式。
解决方法总是相同。你给执行你命令的实体越多信息,(理论上)它能更快执行这样的命令。每次都写一个好的查询。你的整个系统都会为此感谢你的。
如果你喜欢这篇文章...
再看看近期我在 Voxxed Days Zurich 的演讲,其中我展示了一些在数据处理算法上为什么 SQL 总是会胜过 Java 的双曲线例子。