Sqoop将mysql数据导入hbase的血与泪(整整搞了大半天)
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: https://my.oschina.net/yunshuxueyuan/blog
QQ技术交流群:299142667
一、 问题如何产生
庞老师只讲解了mysql和hdfs,mysq与hive的数据互导,因此决定研究一下将mysql数据直接导入hbase,这时出现了一系列问题。
心酸史:
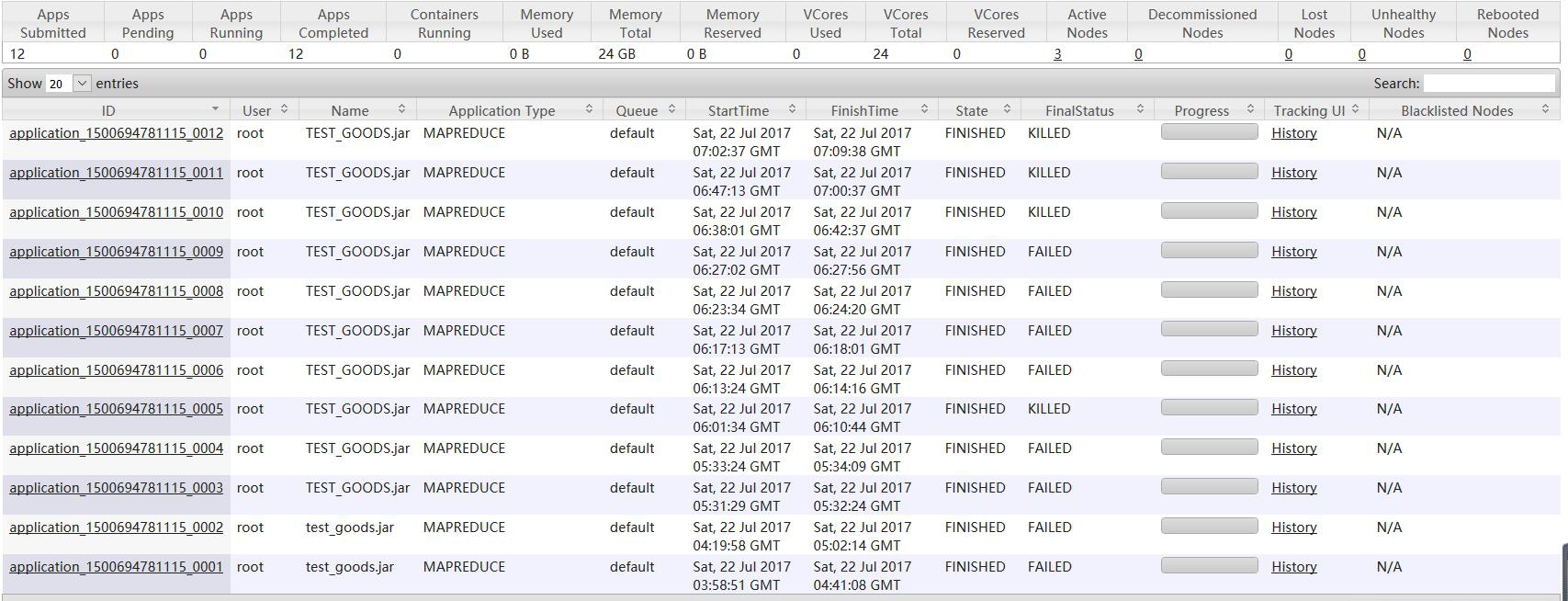
二、 开始具体解决问题
需求:(将以下这张表数据导入mysql)
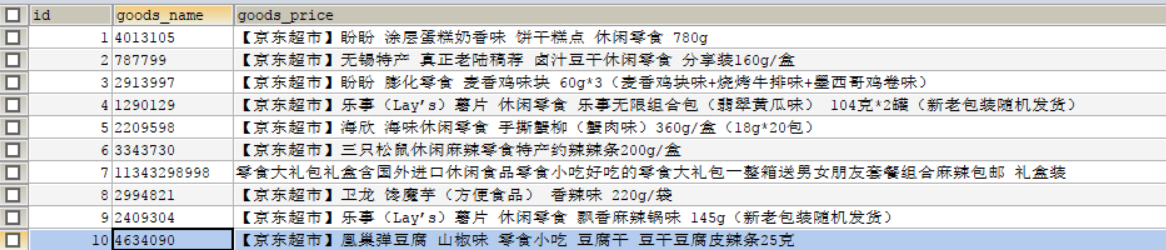
由此,编写如下sqoop导入命令
sqoop import -D sqoop.hbase.add.row.key=true --connect jdbc:mysql://192.168.1.9/spider --username root --password root --table test_goods --hbase-create-table --hbase-table t_goods --column-family cf --hbase-row-key id -m 1

一切看着都很正常,接下来开始执行命令,报如下错误:
1、
报错原因就是指定的mysql表名不是大写,所以mysql表名必须大写
2、
报错原因是没有指定mysql的列名,所以必须指定列名,并且hbase-row-key id 中的id,必须在–columns中显示。 --columns ID,GOODS_NAME, GOODS_PRICE
3、
报错原因是在指定mysql的列名时,用逗号隔开的时候我多加了空格,所以在Columns后显示的列名只能用逗号隔开,不要带空格。
将以上三个问题排除后:我的最新导入命令变为如下:
注意:这里有个小问题:记得将id>=5引起来
再次执行导入命令:出现如下情况(卡了好长时间)


发下map执行完成了,但是也就只卡在这里不动了,mapreduce任务一直在后台起着,一段时间后死掉,在这期间不停的执行导入命令和杀掉mapreduce的job
hadoop job -list 查看mapreduce 的job列表
hadoop job -kill job_id 杀死某个Job
经过长时间的测试,突然意识到当前用的是Hbase伪分布式,一下子恍然大悟:
原因:因为当前环境为hbase的伪分布式,所以hbase的数据是存在本地磁盘上的,
并且由自带的zookeeper进行管理。而将mysql数据导入hbase的原理其实就是将数据导入hdfs,所以要想导入成功,存放hbase的数据地址应该在hdfs上才可以。所以如何解决这个问题,我想大家知道了,那就是开启hbase完全分布式。
经过一顿折腾将虚拟机回复到hbase完全分布式的快照,安装好sqoop,进行最终的测试!
最终执行的导入命令如下:(完整的导入命令)
sqoop import -D sqoop.hbase.add.row.key=true --connect jdbc:mysql://192.168.1.9:3306/spider --username root --password root --table TEST_GOODS --columns ID,GOODS_NAME,GOODS_PRICE --hbase-create-table --hbase-table t_goods --column-family cf --hbase-row-key ID --where "ID >= 5" -m 1
终于见到久违的页面:

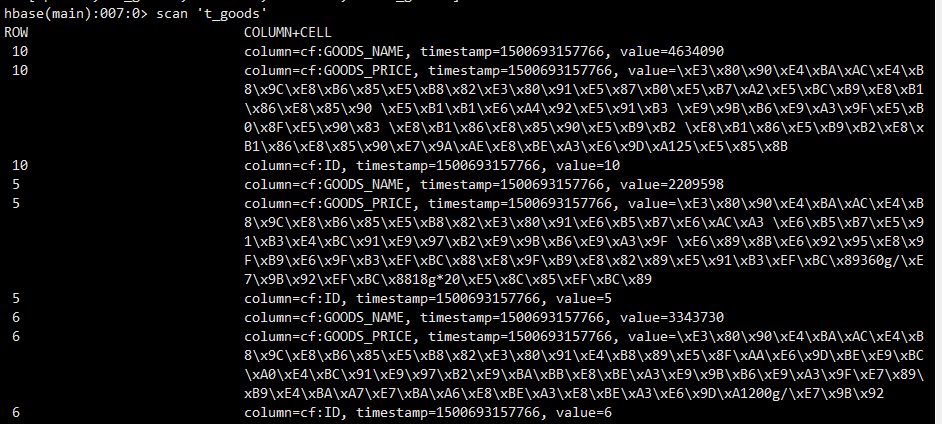
查看hbase,数据已经成功导入
最后我将命令写入一个xxx文件,通过sqoop –options-file xxx 执行导入命令
错误写法如下:
错误原因:参数的名称和参数的值没有进行回车换行
正确写法:
注:参数含义解释
-D sqoop.hbase.add.row.key=true 是否将rowkey相关字段写入列族中,默认为false,默认情况下你将在列族中看不到任何row key中的字段。注意,该参数必须放在import之后。
--connect 数据库连接字符串
--username –password mysql数据库的用户名密码
--table Test_Goods表名,注意大写
--hbase-create-table 如果hbase中该表不存在则创建
--hbase-table 对应的hbase表名
--hbase-row-key hbase表中的rowkey,注意格式
--column-family hbase表的列族
--where 导入是mysql表的where条件,写法和sql中一样
--split-by CREATE_TIME 默认情况下sqoop使用4个并发执行任务,需要制订split的列,如果不想使用并发,可以用参数 --m 1
到此,bug解决完成!!!
三、知识拓展,定时增量导入
1、Sqoop增量导入
--incremental lastmodified 增量导入支持两种模式 append 递增的列;lastmodified时间戳。
--check-column 增量导入时参考的列
--last-value 最小值,这个例子中表示导入2017-06-27到今天的值
2、Sqoop job:
设置定时执行以上sqoop job
使用linux定时器:crontab -e
例如每天执行
0 0 * * * /opt/local/sqoop-1.4.6/bin/sqoop job ….
--exec testjob01
版权声明:本文为yunshuxueyuan原创文章。
如需转载请标明出处: https://my.oschina.net/yunshuxueyuan/blog
QQ技术交流群:299142667