1.元组tuple类型
与列表类似可以存多个值,但是不同的是元祖本身不能被修改
作用:记录多个值,当值没有修改的需求时,使用元组
定义方式:在()内用逗号分开不同类型的值
优先掌握的操作
1、按索引取值(正向取+反向取):只能取
a = (1,2,3,4,5,6,['sss','xxx','ccc']) print(a[1]) print(a[-1]) print(a[-1][1]) print(id(a)) a[-1][1] = 'hahhaha' print(a) print(id(a)) # 修改内部容器类型元素中的元素值,这并不代表了修改元组
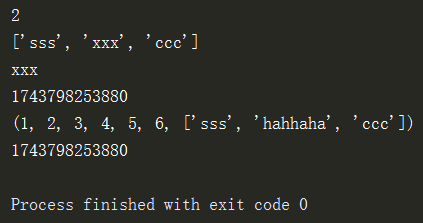
注意:内部容器类型元素中的元素值改变了并不代表元组改变了
a = (1,2,3,4,5,6,['sss','xxx','ccc']) a[2] = 3 print(a)
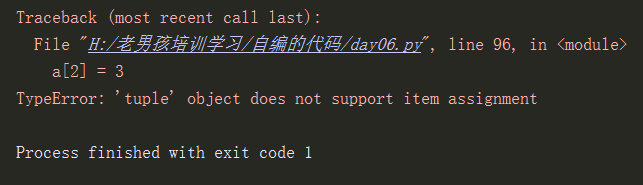
如上图所示,元组中的值不支持修改
2、切片(顾头不顾尾,步长)
a = (1,2,3,4,5,6,['sss','xxx','ccc']) print(a[0:7:2]) print(a[0:-1]) # 顾头不顾尾 print(a[7:0:-1])

注意:顾头不顾尾
3、长度len()
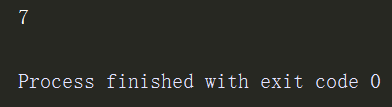
a = (1,2,3,4,5,6,['sss','xxx','ccc']) print(len(a))
4、成员运算in和not in
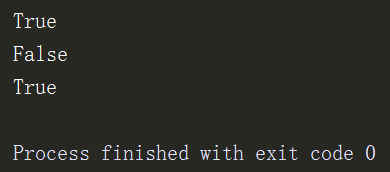
a = (1,2,'3',4,5,6,['sss','xxx','ccc']) b = ['sss','xxx','ccc'] print(1 in a) print('3' not in a) print(b in a)
5、循环
a = (1,2,'3',4,5,6,['sss','xxx','ccc']) for i in a: print(i)

需要掌握的操作
count和index
a = (1,2,'3',4,2,2,['sss','xxx','ccc']) print(a.count(2)) print(a.index('3',0,5)) # 从索引为0-4的元素中找'3'的索引 print(a.index(5)) # 查找没有的值会报错

该类型总结:
存多个值
有序
不可变
2.字典dict类型
作用:记录多个值,每个值都有对应的描述
定义方式:在{}内,由key:value组成一个键值对,键值对与键值对用户逗号分开,key必须是不可变类型,,value可以是任意类型
d = {'name' : 'sxc' , 'age' : 18} # 本质是 d = dict({'name' : 'sxc' , 'age' : 18})
用法一:
d = {'name':'sxc','age':18,'hobby':'read'}
print(d)
用法二:
d1 = dict(name = 'sxc' ,age = 18,hobby = 'read') print(d1)
用法三:
d2 =[ ['name','sxc'], ['age',18], ['hobby','read'] ] # d ={} # for k,v in d2: # d[k]=v # print(d) # 内置了方法,不用这么繁琐 d2 = dict(d2) print(d2)

优先掌握的操作
1、按key存取值:可存可取
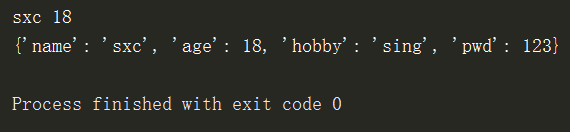
d = {'name':'sxc','age':18,'hobby':'read'}
print(d['name'],d['age']) # 取值
d['hobby'] = 'sing' # 改值
d['pwd'] = 123 # 存值
print(d)
2、长度len
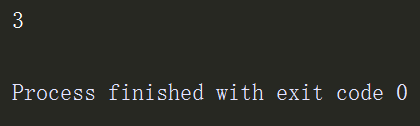
d = {'name':'sxc','age':18,'hobby':'read'}
print(len(d))
3、成员运算in和not in:字典的成员运算判断的是key
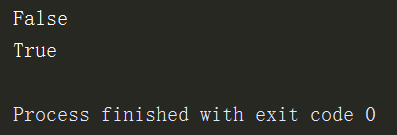
d = {'name':'sxc','age':18,'hobby':'read'}
print(18 in d)
print('name'in d) # 字典的成员运算判断的是key
4、删除
第一种del
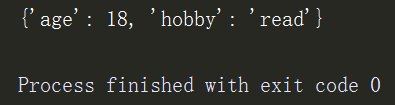
d = {'name':'sxc','age':18,'hobby':'read'}
del d['name']
print(d)
第二种pop
d = {'name':'sxc','age':18,'hobby':'read'}
print(d.pop('name')) # 有返回值
print(d)
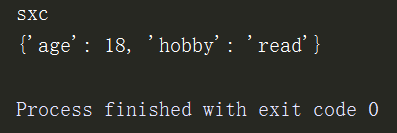
第三种popitem
d = {'name':'sxc','age':18,'hobby':'read'}
print(d.popitem()) # 尾部以元组的形式弹出键值对
print(d.popitem())
print(d)

注意:弹出的是元组形式的键值对
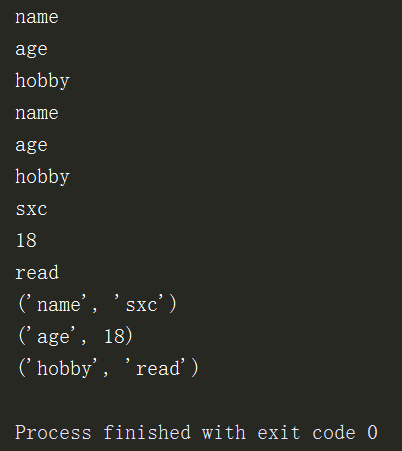
5、键keys(),值values(),键值对items() 注意python2与python3之间的区别
d = {'name':'sxc','age':18,'hobby':'read'}
print(d.keys()) # d.keys只是一个迭代器,只会占一部分内存
for i in d.keys():
print(i)
print(list(d.keys())) # 用列表输出过后,才会把key输出
print(d.values()) # d.values只是一个迭代器,只会占一部分内存
print(list(d.values())) # 用列表输出过后,才会把value输出
print(d.items()) # d.items只是一个迭代器,只会占一部分内存
print(list(d.items())) # 用列表输出过后,才会把value输出
print(dict(list(d.items()))) # 输出后列表的键值对可以再把它字典化

6、循环
for k in d: # 正常取值 print(k) for k in d.keys(): # 在d.keys迭代器中取值 print(k) for v in d.values(): # 在d.values迭代器中取值 print(v) for items in d.items(): # 在d.items迭代器中取值 print(items)
8、dic.get()取值,没有值返回none,不会报错
d = {'name':'sxc','age':18,'hobby':'read'}
d['pwd'] = 123 # 添加值
print(d.get('name')) # 取值
print(d.get('pwd','没有key为pwd的值')) # 如果有值,不会返回后面的话
print(d.get('xxx')) # 没有值返回none,不会报错
print(d.get('xxx','没有key为xxx的值')) # 如果没有值,会返回后面的话

需要掌握的操作
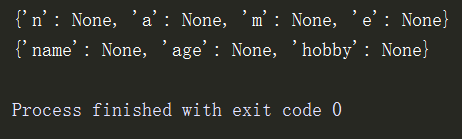
1、dic.fromkeys()的用法:
l = ['name','age','hobby'] # 原理 # d = {} # for k in l: # d[k]= None # print(d) d = dict.fromkeys('name') # 字符串的每个字符按照索引一一输出键值对编成字典 print(d) d = dict.fromkeys(l) # 列表的每个元素按照索引一一输出键值对编成字典 print(d)
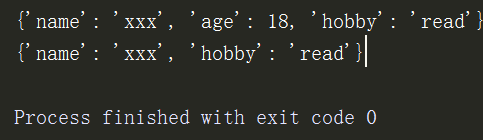
2、uodate的用法:
d1 = {'name':'sxc','age':18}
d2 = {'name':'xxx','hobby':'read'}
d1.update(d2)
print(d1) # 更新过后name会被覆盖
print(d2) # 原字符不变
3、setdefault:有则不动/返回原值,无则添加/返回新值
d = {'name':'sxc','age':18}
res = d.setdefault('name','xxx')
print(res) # 有则不动/返回原值
print(d) # 并未添加
res1 = d.setdefault('hobby','sing')
print(res1) # 无则添加并返回新值
print(d)

该类型总结:
存多个值
无序
可变
dic={'x':1}
print(id(dic))
dic['x']=2
print(id(dic))

3.集合set类型
1 用途: 关系运算,去重
2 定义方式: 在{}内用逗号分开个的多个值
s1 = {1,2.4,3,'sxc',4,(1,2,3)} # 本质是s1 = set({1,2.4,3,'sxc',4,(1,2,3)})
print(s1,type(s1))

集合的三大特性:
2.1 每一个值都必须是不可变类型
2.2 元素不能重复
2.3 集合内元素无序
s2 = set([1,2.9,3,2,2,2,2,2,2,2,4,5,(1,2,3),'sxc']) print(s2,type(s2))

注意:都是不可变类型,重复的只剩一个,元素无序
常用操作和内置方法
1、声明两个集合
pythons={'李二丫','张金蛋','李银弹','赵铜蛋','张锡蛋','alex','oldboy'}
linuxs={'lxx','egon','张金蛋','张锡蛋','alex','陈独秀'}
取既报名python课程又报名linux课程的学员:交集print(pythons & linuxs) print(pythons.intersection(linuxs)) # 简化成&

取所有报名老男孩课程的学员:并集
print(pythons | linuxs) print(pythons.union(linuxs)) # 简化为|

取只报名python课程的学员,取只报名linux课程的学员: 差集
print(pythons - linuxs) print(pythons.difference(linuxs)) # 简化为- print(linuxs - pythons) print(linuxs.difference(pythons)) # 简化为-

取没有同时报名两门课程的学员:对称差集
print(pythons ^ linuxs) print(pythons.symmetric_difference(linuxs)) # 简化为^

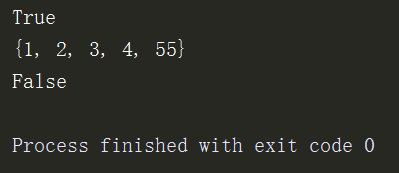
2、是否相等
s1 = {1,2,3,4}
s2 = {1,2,3,4}
print(s1 == s2) # 是否相等
s2.add(55)
print(s2)
print(s1 == s2) # 是否相等
3、父集和子集
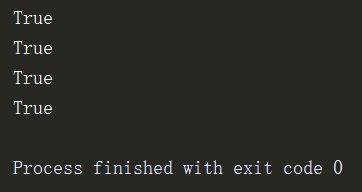
# 父集:一个集合是否包含另一个集合 s1 = {2,3,4} s2 = {1,2,3,4,5} print(s2 >= s1) print(s2.issuperset(s1)) # 子集: s1 = {2,3,4} s2 = {1,2,3,4,5} print(s1 <= s2) print(s1.issubset(s2))
需要掌握的操作
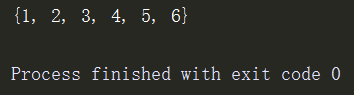
1、update更新
s1={1,2,3}
s1.update({4,5,6})
print(s1)
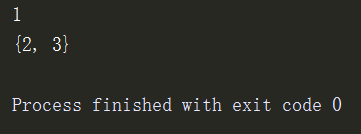
2、删除
pop弹出
s1={1,2,3}
res = s1.pop()
print(res)
print(s1)
remove删除
s1={1,2,3}
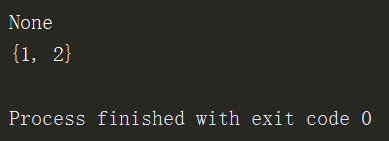
print(s1.remove(3)) # 不返回值
print(s1)
discard删除
s1={1,2,3}
print(s1.remove(3)) # 不返回值
print(s1)
print(s1.discard(2))
print(s1)
print(s1.discard(5)) # 删除不存在的返回none
# print(s1.remove(4)) # 删除不存在的报错
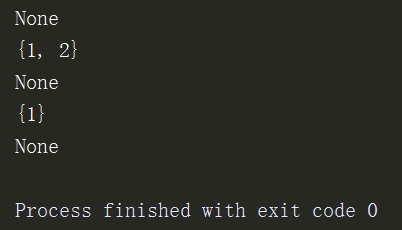
3、add添加
s1={1,2,3}
s1.add(5)
s1.add(66)
s1.add('xxx')
print(s1)

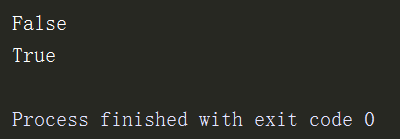
3、isdisjoint是否存在交集,没有交集返回True
s1 = {1,2,3}
s2 = {3,4,5,6}
print(s1.isdisjoint(s2)) # 如果两个集合有交集则返回False
s3 = {5,6,7,8}
print(s1.isdisjoint(s3)) # 如果两个集合没有交集则返回True
该类型总结:
存多个值
无序
set可变
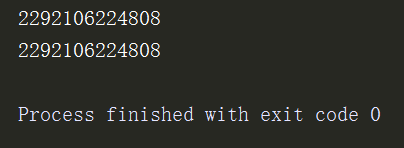
s={1,2,3}
print(id(s))
s.add(4)
print(id(s))
集合去重
局限性
1、无法保证原数据类型的顺序
2、当某一个数据中包含的多个值全部为不可变的类型时才能用集合去重
6