为啥a有4个策略而b有3个策略?

看到下面(树->矩阵)这个就了然了:

强化学习的根本目的在于最大化奖励【optimize your long term expected reward(获得更多的奖励)】
MiniMAx
假设所有人都在寻求最优,达到最大化奖励
来吧,再加点不确定性进来~~愉快的玩耍吧~~~:
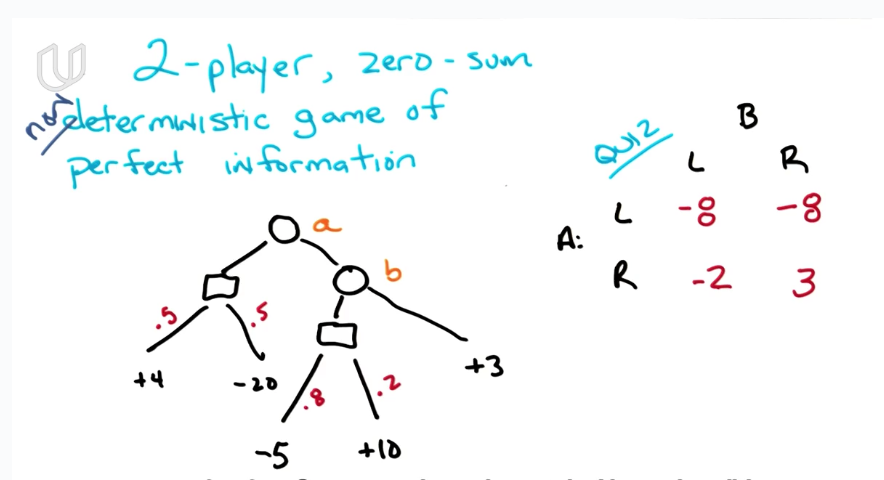
Von Neumann冯·诺依曼提出的,哇塞,大牛就是腻害!!无处不在~~
ok,之前都是纯策略问题,下面再来看看综合策略问题~上图

Nash均衡: n repeated game => n repeated N.F.
零和博弈和非零和博弈
反复博弈、囚徒困境
MDP:RL::