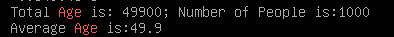一、题目描述
(1)编写Spark应用程序,该程序可以在本地文件系统中生成一个数据文件peopleage.txt,数据文件包含若干行(比如1000行,或者100万行等等)记录,每行记录只包含两列数据,第1列是序号,第2列是年龄。效果如下:
1 89 2 67 3 69 4 78
(2)编写Spark应用程序,对本地文件系统中的数据文件peopleage.txt的数据进行处理,计算出所有人口的平均年龄。
二、实现
1、生成数据文件peopleage.txt
1)创建程序的目录结构
创建一个存放代码的目录,进入目录下创建一个目录用来保存该题目所有文件(/swy/resource/spark/peopleage)
在peopleage目录下建立src/main/scala代码目录,专门用来保存scala代码文件,命令如下:

2)生成数据文件peopleage.txt的代码
创建一个代码文件GeneratePeopleAge.scala,用来生成数据文件peopleage.txt,命令如下:


代码如下:
import java.io.FileWriter
import java.io.File
import scala.util.Random
object GeneratePeopleAge{
def main(args:Array[String]){
val fileWriter = new FileWriter(new File("/swy/resource/spark/peopleage/peopleage.txt"),false)
val rand = new Random()
for (i <- 1 to 1000){
fileWriter.write(i+" "+rand.nextInt(100))
fileWriter.write(System.getProperty("line.separator"))
}
fileWriter.flush()
fileWriter.close()
}
}
3)sbt打包
退回到people目录下:

输入如下:
name := "Simple Project"
version := "1.0"
scalaVersion := "2.11.12"
libraryDependencies += "org.apache.spark" %% "spark-core" % "2.1.0"
输入命令打包:
sbt package
打包成功:

4)运行文件,生成peopleage.txt

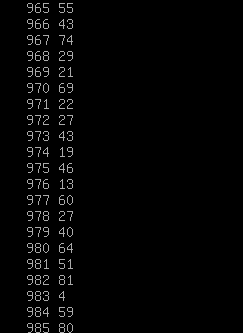
可以看到目录下已经生成peopleage.txt,查看文件:

2、计算所有人口的平均年龄
1)创建CountAvgage.scala

2)代码
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object CountAvgAge {
def main(args:Array[String]) {
if (args.length < 1) {
println("Usage: CountAvgAge inputdatafile")
System.exit(1)
}
val conf = new SparkConf().setAppName("Count average age")
val sc = new SparkContext(conf)
val lines = sc.textFile(args(0),3)
val peopleNum =lines.count()
val totalAge = lines.map(line => line.split(" ")(1)).map(t => t.trim.toInt).collect().reduce((a,b) => a+b)
println("Total Age is: " +totalAge+ "; Number of People is: " +peopleNum)
val avgAge : Double = totalAge.toDouble / peopleNum.toDouble
println("Average Age is: " +avgAge)
}
}
3)打包
退回people文件夹,输入命令打包:

4)运行程序
输入如下命令:

结果: