0.在三台机器上配置kafka的环境
可以参考另一篇文章:https://www.cnblogs.com/codedoge/p/10100953.html
1.首先配置zookeeper集群,打开zookeeper的配置文件
vi config/zookeeper.properties
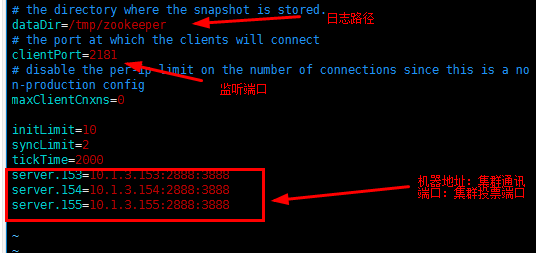
三台机器都做一模一样的操作即可
2.分别创建myid
"server.id=host:port:port" 表示不同服务器的配置。id表示不同服务器,在服务器配置文件的dataDir所设置的目录里需要手动创建一个叫做myid的文件,这个文件只有一行内容,标识自己的身份也就是自己的ID值,该值范围可以是1-255之间。
echo 153 > /tmp/zookeeper/myid //153机器 echo 154 > /tmp/zookeeper/myid //154机器 echo 155 > /tmp/zookeeper/myid //155机器
3.分别启动zookeeper
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
4.接下来配置kafka集群分别修改三台机器上kafka的配置文件
vi config/server.properties
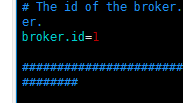
注意三台机器不可相同,配置范围是0~255

配置zookeeper
5.分别启动kafka
./bin/kafka-server-start.sh ./config/server.properties
6.开启负载均衡
./bin/kafpreferred-replica-election.sh --zookeeper 10.1.3.153:2181,10.1.3.155:2181,10.1.3.154:2181
7.创建需要的topic,将备份数设置为三
bin/kafka-topics.sh --create --zookeeper zookeeperip:2181 --replication-factor 3 --partitions 1 --topic test