在开发过程中,合理地使用线程池能够带来至少以下几个好处。
降低资源消耗:通过重复利用已创建的线程降低线程创建和销毁造成的消耗。
提高响应速度:当任务到达时,任务可以不需要等到线程创建就能立即执行。
提高线程的可管理性:线程是稀缺资源,如果无限制地创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。但是,要做到合理利用线程池,必须了解其实现原理。
代码解耦:比如生产者消费者模式。
线程池实现原理
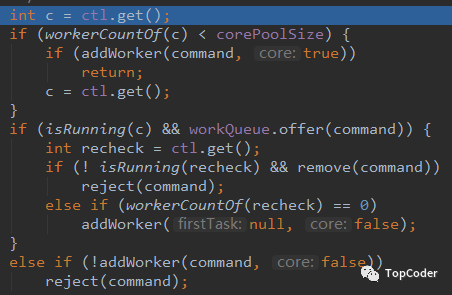
当提交一个新任务到线程池时,线程池的处理流程如下:
如果当前运行的线程少于corePoolSize,则创建新线程来执行任务(注意,执行这一步骤需要获取全局锁)。
如果运行的线程等于或多于corePoolSize,则将任务加入BlockingQueue。
如果无法将任务加入BlockingQueue(队列已满),则创建新的线程来处理任务(注意,执行这一步骤也需要获取全局锁)。
如果创建新线程将使当前运行的线程数超出maximumPoolSize,该任务将被拒绝,并调用相应的拒绝策略来处理(RejectedExecutionHandler.rejectedExecution()方法,线程池默认的饱和策略是AbortPolicy,也就是抛异常)。
ThreadPoolExecutor采取上述步骤的总体设计思路,是为了在执行execute()方法时,尽可能地避免获取全局锁(那将会是一个严重的可伸缩瓶颈)。在ThreadPoolExecutor完成预热之后(当前运行的线程数大于等于corePoolSize),几乎所有的execute()方法调用都是执行步骤2,而步骤2不需要获取全局锁。
线程池任务 拒绝策略包括 抛异常、直接丢弃、丢弃队列中最老的任务、将任务分发给调用线程处理。
线程池的创建:通过ThreadPoolExecutor来创建一个线程池。
new ThreadPoolExecutor(corePoolSize, maximumPoolSize, keepAliveTime, timeUnit, runnableTaskQueue, handler);
创建一个线程池时需要输入以下几个参数:
corePoolSize(线程池的基本大小):当提交一个任务到线程池时,线程池会创建一个线程来执行任务,即使其他空闲的基本线程能够执行新任务也会创建线程,等到线程池的线程数等于线程池基本大小时就不再创建。如果调用了线程池的prestartAllCoreThreads()方法,线程池会提前创建并启动所有基本线程。
maximumPoolSize(线程池最大数量):线程池允许创建的最大线程数。如果队列满了,并且已创建的线程数小于最大线程数,则线程池会再创建新的线程执行任务。值得注意的是,如果使用了无界的任务队列这个参数就没什么效果。
keepAliveTime(线程活动保持时间):线程池的工作线程空闲后,保持存活的时间。所以,如果任务很多,并且每个任务执行的时间比较短,可以调大时间,提高线程的利用率。
TimeUnit(线程活动保持时间的单位):可选的单位有天(DAYS)、小时(HOURS)、分钟(MINUTES)、毫秒(MILLISECONDS)、微秒(MICROSECONDS,千分之一毫秒)和纳秒(NANOSECONDS,千分之一微秒)。
runnableTaskQueue(任务队列):用于保存等待执行的任务的阻塞队列。可以选择以下几个阻塞队列。
- ArrayBlockingQueue:是一个基于数组结构的有界阻塞队列,此队列按FIFO(先进先出)原则对元素进行排序。
LinkedBlockingQueue:一个基于链表结构的阻塞队列,此队列按FIFO排序元素,吞吐量通常要高于ArrayBlockingQueue。静态工厂方法Executors.newFixedThreadPool()使用了这个队列。
SynchronousQueue:一个不存储元素的阻塞队列。每个插入操作必须等到另一个线程调用移除操作,否则插入操作一直处于阻塞状态,吞吐量通常要高于LinkedBlockingQueue,静态工厂方法Executors.newCachedThreadPool使用了这个队列。
PriorityBlockingQueue:一个具有优先级的无界阻塞队列。
线程的状态
在HotSpot VM线程模型中,Java线程被一对一映射到本地系统线程,Java线程启动时会创建一个本地系统线程;当Java线程终止时,这个本地系统线程也会被回收。操作系统调度所有线程并把它们分配给可用的CPU。
thread运行周期中,有以下6种状态,在 java.lang.Thread.State 中有详细定义和说明:
// Thread类public enum State { /** * 刚创建尚未运行 */ NEW, /** * 可运行状态,该状态表示正在JVM中处于运行状态,不过有可能是在等待其他资源,比如CPU时间片,IO等待 */ RUNNABLE, /** * 阻塞状态表示等待monitor锁(阻塞在等待monitor锁或者在调用Object.wait方法后重新进入synchronized块时阻塞) */ BLOCKED, /** * 等待状态,发生在调用Object.wait、Thread.join (with no timeout)、LockSupport.park * 表示当前线程在等待另一个线程执行某种动作,比如Object.notify()、Object.notifyAll(),Thread.join表示等待线程执行完成 */ WAITING, /** * 超时等待,发生在调用Thread.sleep、Object.wait、Thread.join (in timeout)、LockSupport.parkNanos、LockSupport.parkUntil */ TIMED_WAITING, /** *线程已执行完成,终止状态 */ TERMINATED;}
线程池操作
向线程池提交任务,可以使用两个方法向线程池提交任务,分别为execute()和submit()方法。execute()方法用于提交不需要返回值的任务,所以无法判断任务是否被线程池执行成功。通过以下代码可知execute()方法输入的任务是一个Runnable类的实例。
threadsPool.execute(new Runnable() { @Override public void run() { // TODO Auto-generated method stub }});
submit()方法用于提交需要返回值的任务。线程池会返回一个future类型的对象,通过这个future对象可以判断任务是否执行成功,通过future的get()方法来获取返回值,future的get()方法会阻塞当前线程直到任务完成,而使用get(long timeout,TimeUnit unit)方法则会阻塞当前线程一段时间后立即返回,这时候有可能任务还没有执行完。
Future future = executor.submit(harReturnValuetask);try { Object s = future.get();} catch (InterruptedException e) { // 处理中断异常} catch (ExecutionException e) { // 处理无法执行任务异常} finally { // 关闭线程池 executor.shutdown();}
合理配置线程池
要想合理配置线程池,必须先分析任务的特点,可以从以下几个角度分析:
任务的性质:CPU密集型任务、IO密集型任务和混合型任务。
任务的优先级:高、中和低。
任务的执行时间:长、中和短。
任务的依赖性:是否依赖其他系统资源,如数据库连接。
性质不同的任务可以用不同规模的线程池分开处理。CPU密集型任务应配置尽可能少的线程,如配置Ncpu+1个线程的线程池。由于IO密集型任务线程并不是一直在执行任务,则应配置多一点线程,如2*Ncpu。混合型的任务,如果可以拆分,将其拆分成一个CPU密集型任务和一个IO密集型任务,只要这两个任务执行的时间相差不是太大,那么分解后执行的吞吐量将高于串行执行的吞吐量。如果这两个任务执行时间相差太大,则没必要进行分解。可以通过Runtime.getRuntime().availableProcessors()方法获得当前设备的CPU个数。
优先级不同的任务可以使用优先级队列PriorityBlockingQueue来处理。它可以让优先级高的任务先执行。执行时间不同的任务可以交给不同规模的线程池来处理,或者可以使用优先级队列,让执行时间短的任务先执行。依赖数据库连接池的任务,因为线程提交SQL后需要等待数据库返回结果,等待的时间越长,则CPU空闲时间就越长,那么线程数应该设置得越大,这样才能更好地利用CPU。
线程池中线程数量未达到coreSize时,这些线程处于什么状态?
这些线程处于RUNNING或者WAITING,RUNNING表示线程处于运行当中,WAITING表示线程阻塞等待在阻塞队列上。当一个task submit给线程池时,如果当前线程池线程数量还未达到coreSize时,会创建线程执行task,否则将任务提交给阻塞队列,然后触发线程执行。(从submit内部调用的代码也可以看出来)
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor继承自ThreadPoolExecutor。它主要用来在给定的延迟之后运行任务,或者定期执行任务。ScheduledThreadPoolExecutor的功能与Timer类似,但ScheduledThreadPoolExecutor功能更强大、更灵活。Timer对应的是单个后台线程,而ScheduledThreadPoolExecutor可以在构造函数中指定多个对应的后台线程数。
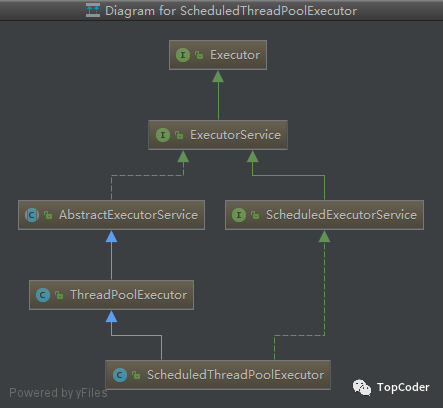
ScheduledThreadPoolExecutor继承自ThreadPoolExecutor,ScheduledThreadPoolExecutor和ThreadPoolExecutor的区别是,ThreadPoolExecutor获取任务时是从BlockingQueue中获取的,而ScheduledThreadPoolExecutor是从DelayedWorkQueue中获取的(注意,DelayedWorkQueue是BlockingQueue的实现类)。
ScheduledThreadPoolExecutor把待调度的任务(ScheduledFutureTask)放到一个DelayQueue中,其中ScheduledFutureTask主要包含3个成员变量:

郑州哪里割包皮好http://www.zztongji120.com/
sequenceNumber:任务被添加到ScheduledThreadPoolExecutor中的序号;
time:任务将要被执行的具体时间;
period:任务执行的间隔周期。
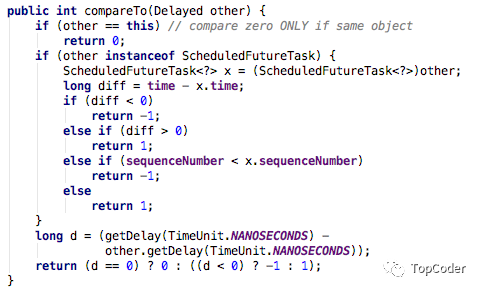
ScheduledThreadPoolExecutor会把待执行的任务放到工作队列DelayQueue中,DelayQueue封装了一个PriorityQueue,PriorityQueue会对队列中的ScheduledFutureTask进行排序,具体的排序比较算法实现如下:
郑州做包皮手术多少钱http://www.zztjxb.com/
ScheduledFutureTask在DelayQueue中被保存在一个PriorityQueue(基于数组实现的优先队列,类似于堆排序中的优先队列)中,在往数组中添加/移除元素时,会调用siftDown/siftUp来进行元素的重排序,保证元素的优先级顺序。
static class DelayedWorkQueue extends AbstractQueue implements BlockingQueue { private static final int INITIAL_CAPACITY = 16; private RunnableScheduledFuture[] queue = new RunnableScheduledFuture[INITIAL_CAPACITY]; private final ReentrantLock lock = new ReentrantLock(); private int size = 0; private Thread leader = null; private final Condition available = lock.newCondition();}
从DelayQueue获取任务的主要逻辑就在take()方法中,首选获取lock,然后获取queue[0],如果为null则await等待任务的来临,如果非null查看任务是否到期,是的话就执行该任务,否则再次await等待。这里有一个leader变量,用来表示当前进行awaitNanos等待的线程,如果leader非null,表示已经有其他线程在进行awaitNanos等待,自己await等待,否则自己进行awaitNanos等待。
// DelayedWorkQueuepublic RunnableScheduledFuture take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { for (;;) { RunnableScheduledFuture first = queue[0]; if (first == null) available.await(); else { long delay = first.getDelay(NANOSECONDS); if (delay <= 0) return finishPoll(first); first = null; // don't retain ref while waiting if (leader != null) available.await(); else { Thread thisThread = Thread.currentThread(); leader = thisThread; try { available.awaitNanos(delay); } finally { if (leader == thisThread) leader = null; } } } } } finally { if (leader == null && queue[0] != null) available.signal(); lock.unlock(); }}
获取到任务之后,就会执行task的run()方法了,即ScheduledFutureTask.run():
public void run() { boolean periodic = isPeriodic(); if (!canRunInCurrentRunState(periodic)) cancel(false); else if (!periodic) ScheduledFutureTask.super.run(); else if (ScheduledFutureTask.super.runAndReset()) { setNextRunTime(); reExecutePeriodic(outerTask); }}