获取页面元素
为什么要获取页面元素
例如:我们想要操作页面上的某部分(显示/隐藏,动画),需要先获取到该部分对应的元素,才进行后续操作
1 根据id获取元素


 如果没有找到那个元素,返回null
如果没有找到那个元素,返回null
var div = document.getElementById('main');
console.log(div);
// 获取到的数据类型 HTMLDivElement,对象都是有类型的
注意:由于id名具有唯一性,部分浏览器支持直接使用id名访问元素,但不是标准方式,不推荐使用。
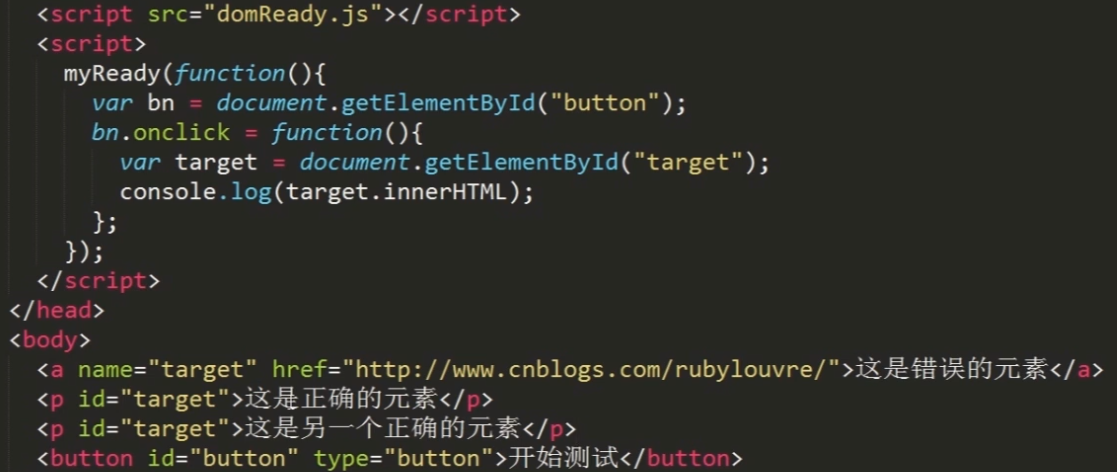
Bug:
document.getElementById()在IE浏览器(版本8之前)的一个bug
在IE8以前的版本中,document.getElementById()获取的元素不仅限于ID,当存在相同的name属性时,一样会返回该元素 。所以这里会弹出a元素。
标准浏览器中会正确找到id为target元素,IE低版本浏览器中, 返回的是第一个id或name为target的元素。
当有两个相同的id的元素时,返回的是第一个id为target的元素,IE低版本浏览器中, 返回的是第一个id或name为target的元素。
解决Bug:
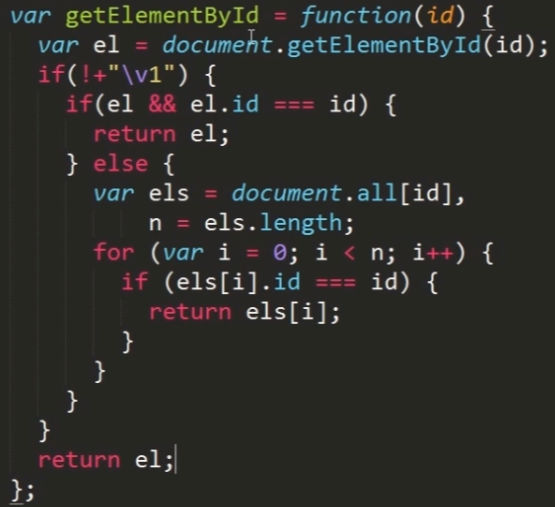


理解:
1、document.all方法的作用主要是返回对文档中所有 HTML 元素的引用。例如:直接输出这个语句:


2、document.all(0)和document.all[0]都是可以的,都可以选择到第一个元素:


因为document.all方法得到的是一个类数组集合,并不是一个真正的数组,所以既可以使用数组的方法,也可以使用()来获取。记住即可。另外这个属性基本上已经用不到了,了解一下即可。

必须是document.getElementByid("id")。不能用 其他元素.getElementByid("id")。
2 根据name获取元素*
var inputs = document.getElementsByName('hobby');
for (var i = 0; i < inputs.length; i++) {
var input = inputs[i];
console.log(input);
}
iE6和opera7.5浏览器上有Bug:首先它们会返回id=给定指定元素,其次它们仅返回input元素与image元素。
3 根据标签名获取元素


获取id为list1的元素内的所有li元素。
var divs = document.getElementsByTagName('div');
for (var i = 0; i < divs.length; i++) {
var div = divs[i];
console.log(div);
}
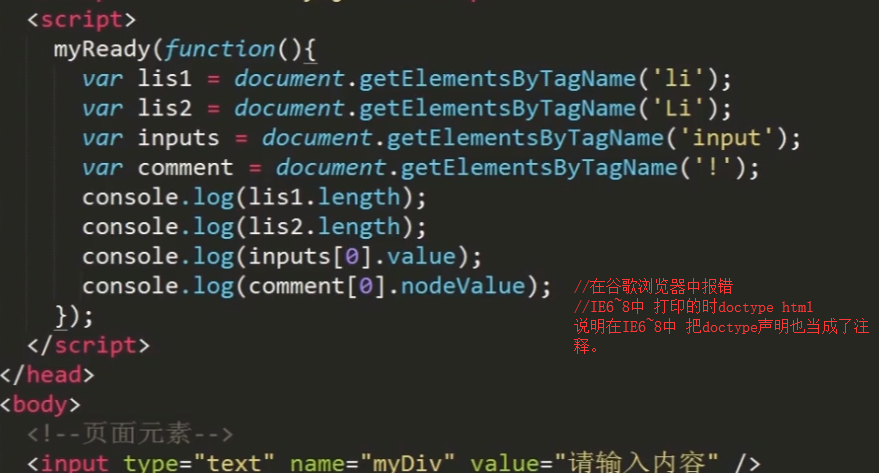
 获取注释节点
获取注释节点
 获取页面中所有元素节点从html开始
获取页面中所有元素节点从html开始
4 根据类名获取元素*
var mains = document.getElementsByClassName('main');
for (var i = 0; i < mains.length; i++) {
var main = mains[i];
console.log(main);
}
支持:Firefox3、IE9、chrome和safari4 以上。
不支持:IE8及以下。
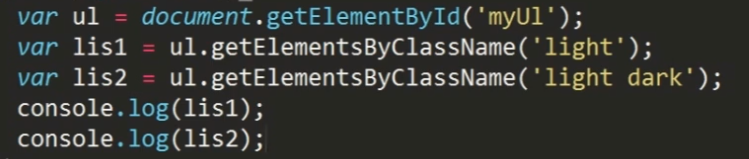
传入多个类名时用空格隔开,不区分先后顺序。
解决getElementsByClassName兼容性问题

1 var getElementsByClassName = function(opts) { 2 var searchClass = opts.searchClass; // 存储要查找的类名 3 var node = opts.node || document; // 存储要出查找的范围 4 var tag = opts.tag || '*'; // 存储一定范围内要查找的标签 5 var result = []; 6 // 判断浏览器支不支持getElementsByClassName方法 7 if (document.getElementsByClassName) { // 如果浏览器支持 8 // 通过getElementsByClassName获取所有的元素 9 var nodes = node.getElementsByClassName(searchClass); 10 // 判断是否传入了指定范围, 如果传入的li, 那么就只返回对应类名为searchClass的li标签 11 if (tag !== "*") { 12 // 这里的node = nodes[i++]表示直到nodes集合中的最后一个元素。停止循环。这个就是循环条件哦。 13 /** 14 * 可以这样理解for循环中间的代码是用来判断是否满足循环条件的 15 * 当i = nodes.length;时候, nodes[nodes.length]值为undefined。 所以node的也被赋值为undefined, 16 * 此时通过隐士类型转换, undefined会被转成false,不满足循环条件了,也就退出循环了 17 */ 18 for (var i = 0; node = nodes[i++];) { 19 // 判断获取元素的标签名和指定的标签名是否相等 20 if (node.tagName === tag.toUpperCase()) { 21 // 相等的话,就将获取的元素存在到一开始定义的数组中 22 result.push(node); 23 } 24 } 25 } else { // 直接将获取的所有元素赋值给result 26 result = nodes; 27 } 28 // 最后返回获取的元素 29 return result; 30 } else { // 使用IE8以下的浏览器能够支持该属性 31 // 所有浏览器都会支持getElementsByTagName这个方法, 所以用给这个方法来兼用不支持getElementsByClassName的方法 32 var els = node.getElementsByTagName(tag); 33 // 获取所有元素 34 var elsLen = els.length; 35 var i, j; 36 // 这里是定义一个正则表达式, 用来匹配传入的类名 37 /** 38 * 正则表达式的定义及相关用法,后面会有对应的章节详细讲解, 同学目前只需要简单了解即可哦 39 */ 40 var pattern = new RegExp("(^|\s)" + searchClass + "(\s|$)"); 41 /** 42 * 通过for循环, 将标签中拥有类名元素找到, 赋值给result 43 */ 44 for (i = 0, j = 0; i < elsLen; i++) { 45 // 检测正则表达式, 46 if (pattern.test(els[i].className)) { 47 result[j] = els[i]; 48 j++; 49 } 50 } 51 return result; 52 } 53 }
1 <!DOCTYPE html> 2 <html> 3 <head> 4 <meta charset="utf-8"> 5 <meta name="viewport" content="width=device-width, initial-scale=1"> 6 <title>getElementsByClassName() 兼容浏览器方案</title> 7 <script src="domReady.js"></script> 8 <script src="getElementsByClassName.js"></script> 9 <script> 10 myReady(function(){ 11 var myUl2 = document.getElementById("myUl2"); 12 var r = getElementsByClassName({ 13 searchClass: "light dark", 14 node: myUl2 15 }); 16 console.log(r[0].innerHTML); 17 }); 18 </script> 19 </head> 20 <body> 21 <ul id="myUl"> 22 <li class="light">1</li> 23 <li class="light dark">2</li> 24 <li class="light">3</li> 25 </ul> 26 <ul id="myUl2"> 27 <li class="light">1</li> 28 <li class="light dark">second</li> 29 <li class="light">3</li> 30 </ul> 31 </body> 32 </html>
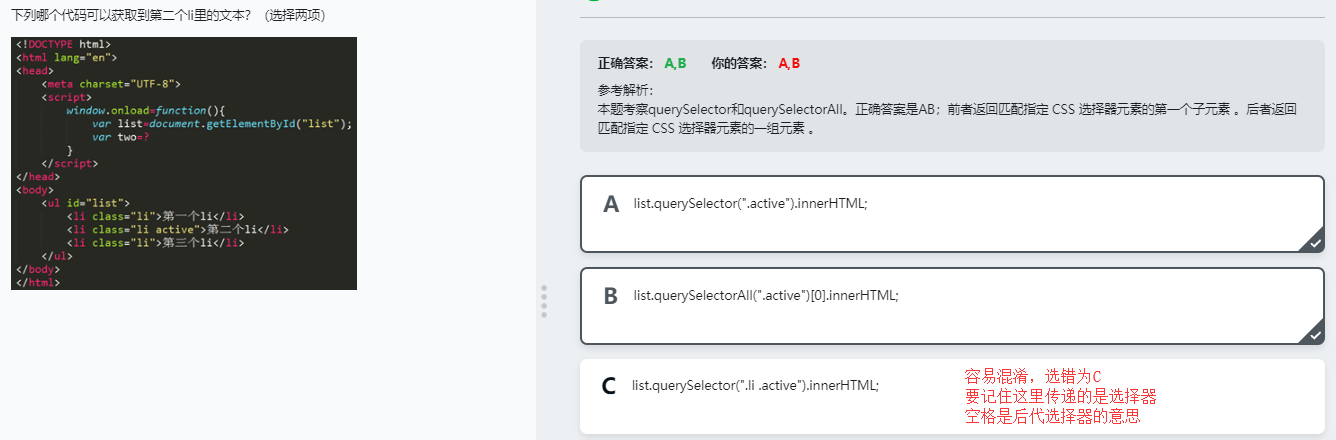
5 根据选择器获取元素*
var text = document.querySelector('#text');
console.log(text);
var boxes = document.querySelectorAll('.box');
for (var i = 0; i < boxes.length; i++) {
var box = boxes[i];
console.log(box);
}

IE7不支持。
querSelector()找不到对应的元素返回null。
querSelectorAll()找不到对应的元素返回空数组。

类名中的冒号,需要进行转义,否则会报错。


返回的是StaticNodeList对象,类似NodeList但不是纯正的NodeList,不具有类数组对象的动态性,下述代码不会陷入死循环。

掌握
getElementById()
getElementsByTagName()
了解
getElementsByName()
getElementsByClassName()
querySelector()
querySelectorAll()
给元素设置样式


