通过画图来看下对象在内存中是如何分配的,这样更有助于初学者理解对象。
学生类
class Student{
//学号
int id;
//姓名
String name;
//性别
boolean sex;
//年龄
int age;
public void study() { //定义学习的方法
System.out.println("学生学习");
}
public void love(String name) { //定义谈恋爱的方法
System.out.println("我在跟" + name + "谈恋爱");
}
public void takeExercises(String sport){
System.out.println(sport);
}
}
学生测试类:
public class StudentTest01{
public static void main(String[] args){
Student s = new Student();
s.name = "张三";
s.age = 20;
s.sex = true;
s.id = 1001;
s.study();
s.love("赵六");
s.takeExercises("打篮球");
}
}
在JVM内存里面主要分布有以下三个区域:
栈:存放基础数据和自定义对象的引用
堆:主要存储创建的对象,即new出来的对象。
方法区:加载存放class文件(字节码文件)
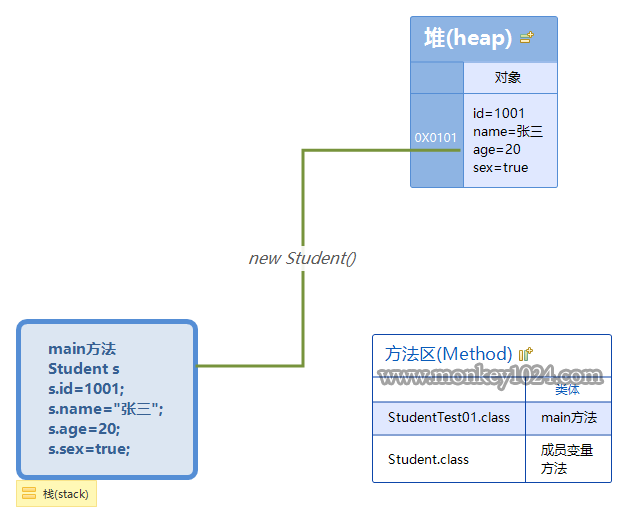
通过上图来看,程序是这样执行的:
1将StudentTest01.class文件加载到方法区
2将Student.class文件加载到方法区
3main方法压栈
4在堆里面创建一个Student的对象
5栈里面的s指向堆里面Student对象的内存地址0x0101
6给对象的成员变量进行赋值
7方法弹栈
8程序执行结束
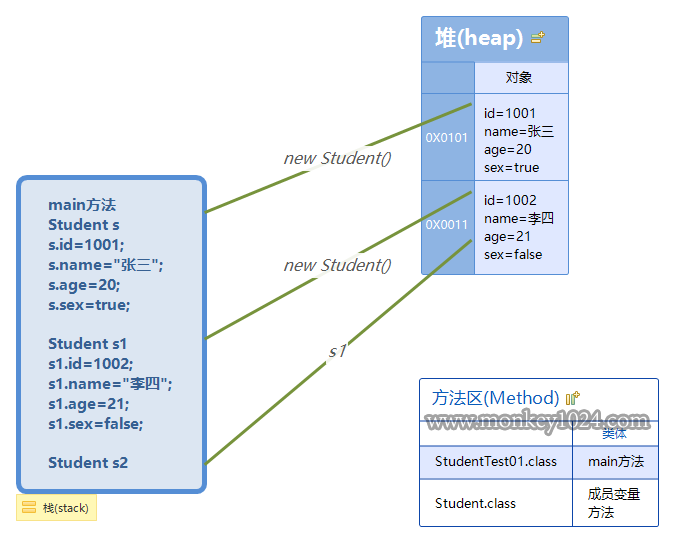
创建两个对象
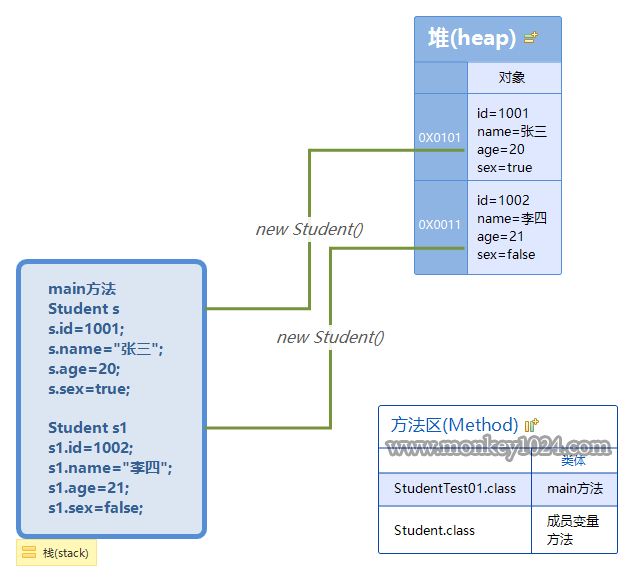
三个指向两个对象
public class StudentTest01{
public static void main(String[] args){
Student s = new Student();
s.name = "张三";
s.age = 20;
s.sex = true;
s.id = 1001;
Student s1 = new Student();
s1.id=1002;
s1.name="李四";
s1.age=21;
s1.sex=false;
Student s2 = s1;
}
}
上面代码将s1指向的对象赋给s2,相当于s1和s2指向同一个对象