@两篇很全面的文章,以及传智播客的课程。http://jiajun.iteye.com/blog/899632/和http://blog.csdn.net/woshiwanxin102213/article/details/17584043
一.简介
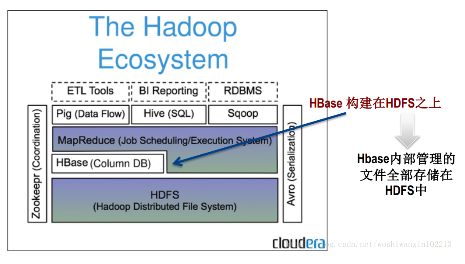
hbase,全称Hadoop Base是bigtable的开源山寨版本。是建立的hdfs之上,提供高可靠性(几台机器down掉不影响性能)、高性能(可以实现毫秒级的读写)、列存储、可伸缩、实时读写的分布式数据库系统。
它介于nosql和RDBMS之间,仅能通过主键(row key)和主键的range来检索数据,仅支持单行事务(可通过hive支持来实现多表join等复杂操作)。主要用来存储非结构化和半结构化的松散数据。
与hadoop一样,Hbase目标主要依靠横向扩展,通过不断增加廉价的商用服务器,搭建起大规模结构化存储集群,来增加计算和存储能力。
hbase可以利用HDFS作为其文件存储系统,利用MapReduce来分析处理HBase中的海量数据,利用Zookeeper来作为协调工具。
下幅图表明了HBase在Hadoop生态圈的位置。
HBase中表的特点:
- 大:一个表可以有上亿行,上百万亿行
- 无模式:每行都有一个可排序(字典顺序)的主键和任意多的列,列可以根据需要动态的增加,同一张表中的不同行可以有截然不同的列
- 面向列:面向列(族)的存储和权限控制,列(族)独立检索
- 稀疏:空(null)列并不占用存储空间,表可以设计的非常稀疏
- 数据多版本:每个单元中的数据可以有多个版本,默认情况下版本号自动分配,是单元格插入时的时间戳
- 数据类型单一:HBase中的数据都是字符串,没有类型
二.HBase数据模型和基本概念

主键:Row key,是用于检索记录的主键,访问hbase table中的行,共有三种方式:

2.region按大小分割的,每个表一开始只有一个region,随着数据不断插入表,region不断增大,当增大到一个阀值的时候,Hregion就会等分会两个新的Hregion。并且会被分配到两个不同的机器上。当table中的行不断增多,就会有越来越多的Hregion。

3.Hregion是Hbase中分布式存储和负载均衡的最小单元。最小单元就表示不同的Hregion可以分布在不同的HRegion server上。但一个Hregion是不会拆分到多个server上的。
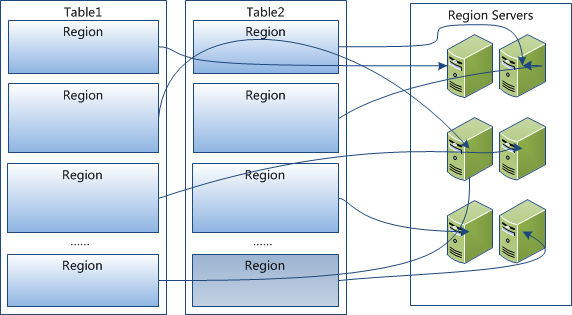
4. HRegion虽然是分布式存储的最小单元,但并不是存储的最小单元。
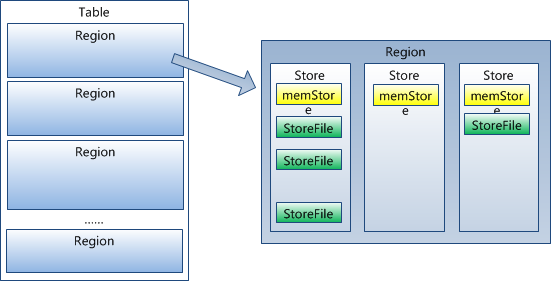
事实上,HRegion由一个或者多个Store组成,每个store保存一个columns family。
每个Strore又由一个memStore和0至多个StoreFile组成。如图:
StoreFile以HFile格式保存在HDFS上。
一个列族的数据是放在一个store上的。
更多关于HFile的结构,见参考博客。
四.系统架构。
很重要的一张图:
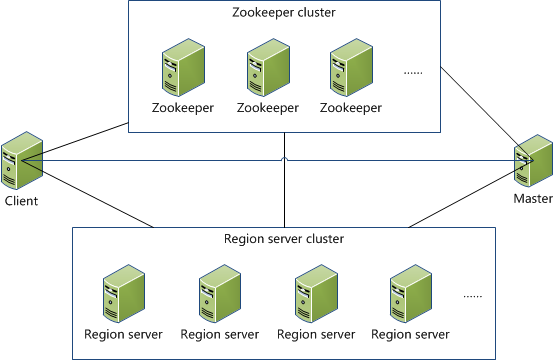
Client
包含访问HBase的接口(例如操作数据库的java接口),并维护cache来加快对HBase的访问,比如region的位置信息。
Zookeeper(动物管理员)
1.在实际中,为了集群的安全,启用了多个master。但是通过选举,保证任何时候,集群中只有一个master,Master与RegionServers 启动时会向ZooKeeper注册。
2.存贮所有Region的寻址入口,主要是存储Region和列族的映射表
3.实时监控Region server的上线和下线信息,并实时通知Master,从而进行重新分配。因为region server上线会发送心跳给zookeeper,超过一段时间未发送心跳,就认为down机了
4.存储HBase的schema和table元数据。包括有哪些table,每个table上有哪些column family
zookeeper的引入是为了更高效的管理多个region server
Master
1.为region server 分配region。当某个region的数据过多,会被切分为两部分,region的切分由master来完成。
2.负责region server的负载均衡
3.发现失效的region server 并重新分配其上的region(数据可以从HDFS上恢复)
4.HDFS的垃圾文件回收
5.处理schema更新请求,主要是DDL操作,例如创建表,删除表...
Region Server
1.维护region,处理对这些region的IO请求
2.负责切分在运行过程中变得过大的region
可以看到,client访问hbase上数据的过程并不需要master参与(寻址访问zookeeper和region server,数据读写访问regione server),master仅仅维护者table和region的元数据信息,负载很低。