索引:
drop table test1 purge; drop table test2 purge; drop table test3 purge; drop table t purge; create table t as select * from dba_objects; create table test1 as select * from t; create table test2 as select * from t; create table test3 as select * from t; create index idx_owner on test1(owner); create index idx_object_name on test1(object_name); create index idx_data_obj_id on test1(data_object_id); create index idx_created on test1(created); create index idx_last_ddl_time on test1(last_ddl_time); create index idx_status on test1(status); create index idx_t2_sta on test2(status); create index idx_t2_objid on test2(object_id); set timing on --语句1(test1表有6个索引) insert into test1 select * from t; commit; --语句2(test2表有2个索引) insert into test2 select * from t; commit; --语句3(test3表有无索引) insert into test3 select * from t; commit;
生产库中一般没有索引,查询库中有大量的索引,生产库要执行插入操作。
drop table t purge; create table t as select * from dba_objects; insert into t select * from t; insert into t select * from t; commit; --请从这里开始注意累加的时间(从建索引到插入记录完毕) set timing on create index idx_t_owner on t(owner); create index idx_t_obj_name on t(object_name); create index idx_t_data_obj_id on t(data_object_id); create index idx_t_created on t(created); create index idx_t_last_ddl on t(last_ddl_time); --语句1(t表有6个索引) insert into t select * from t; commit;
--以下进行试验2 drop table t purge; create table t as select * from dba_objects; insert into t select * from t; insert into t select * from t; commit; ---开始注意累加的时间(从插入记录完毕到建索引完毕) set timing on --语句1(t表有6个索引,此时先不建) insert into t select * from t; create index idx_t_owner on t(owner); create index idx_t_obj_name on t(object_name); create index idx_t_data_obj_id on t(data_object_id); create index idx_t_created on t(created); create index idx_t_last_ddl on t(last_ddl_time);
分区效率变低:
分区表
drop table part_tab purge;
create table part_tab (id int,col2 int,col3 int)
partition by range (id)
(
partition p1 values less than (10000),
partition p2 values less than (20000),
partition p3 values less than (30000),
partition p4 values less than (40000),
partition p5 values less than (50000),
partition p6 values less than (60000),
partition p7 values less than (70000),
partition p8 values less than (80000),
partition p9 values less than (90000),
partition p10 values less than (100000),
partition p11 values less than (maxvalue)
)
;
普通表
insert into part_tab select rownum,rownum+1,rownum+2 from dual connect by rownum <=110000;
commit;
create index idx_par_tab_col2 on part_tab(col2) local;
create index idx_par_tab_col3 on part_tab(col3) ;
drop table norm_tab purge;
create table norm_tab (id int,col2 int,col3 int);
insert into norm_tab select rownum,rownum+1,rownum+2 from dual connect by rownum <=110000;
commit;
create index idx_nor_tab_col2 on norm_tab(col2) ;
create index idx_nor_tab_col3 on norm_tab(col3) ;
set autotrace traceonly statistics
set linesize 1000
set timing on
select * from part_tab where col2=8 ;
select * from norm_tab where col2=8 ;
select * from part_tab where col2=8 and id=2;
select * from norm_tab where col2=8 and id=2;

--查看索引高度等信息
select index_name,
blevel,
leaf_blocks,
num_rows,
distinct_keys,
clustering_factor
from user_ind_statistics
where table_name in( 'NORM_TAB');
select index_name,
blevel,
leaf_blocks,
num_rows,
distinct_keys,
clustering_factor FROM USER_IND_PARTITIONS where index_name like 'IDX_PAR_TAB%';
无索引:
--最慢速度(无索引) drop table t purge; create table t as select * from dba_objects; alter table T modify OBJECT_NAME not null; select count(*) from t; set autotrace traceonly set linesize 1000 set timing on select COUNT(*) FROM T;

--快了一点(有普通索引) drop table t purge; create table t as select * from dba_objects; alter table T modify OBJECT_NAME not null; create index idx_object_name on t(object_name); set autotrace traceonly set timing on select count(*) from t;
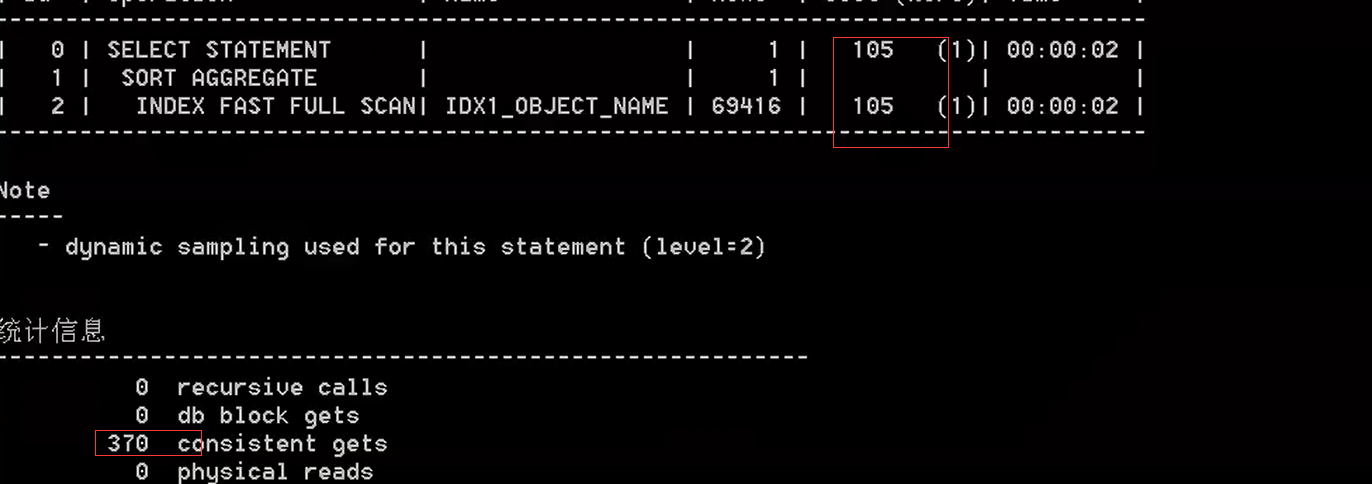
--又快一点(有了一个合适的位图索引) drop table t purge; create table t as select * from dba_objects; Update t Set object_name='abc'; Update t Set object_name='evf' Where rownum<=20000; create bitmap index idx_object_name on t(object_name); set autotrace traceonly set timing on select count(*) from t;
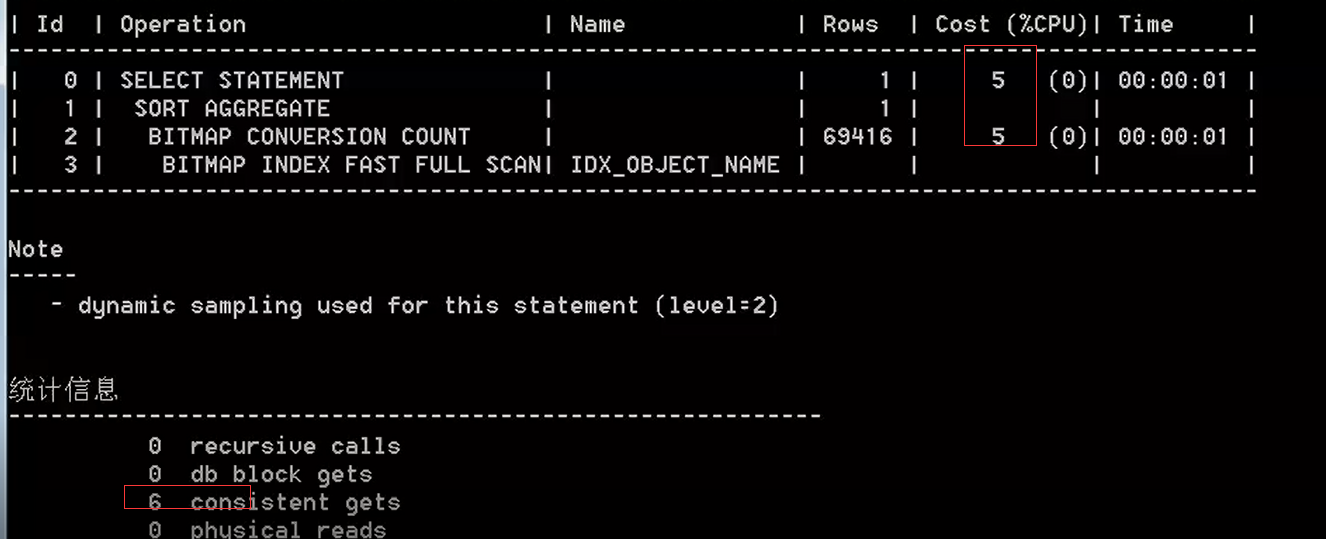
如果记录数不重复或者说重复度很低,ORACLE会选择全表扫描,如果用 来强制,可以发现性能很低下。 alter session set statistics_level=all ; set linesize 1000 set pagesize 1 select /*+index(t,idx_object_name)*/ count(*) from test t; select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
物化视图:(用空间换取时间)
drop materialized view MV_COUNT_T;
drop table t purge;
create table t as select * from dba_objects;
Update t Set object_name='abc';
Update t Set object_name='evf' Where rownum<=20000;
create materialized view mv_count_t
build immediate
refresh on commit
enable query rewrite
as
select count(*) FROM T;
set autotrace traceonly
set linesize 1000
select COUNT(*) FROM T;
--又再快一点(缓存结果集,也是要注意使用的场景) drop table t purge; create table t as select * from dba_objects; select count(*) from t; set linesize 1000 set autotrace traceonly select /*+ result_cache */ count(*) from t;
提高sql的运行速度:
未优化:
create or replace procedure proc_0
as
begin
for i in 1 .. 100000
loop
execute immediate
'insert into t values ( '||i||')';
commit;
end loop;
end;
/
exec proc_0;
一:绑定变量
create or replace procedure proc_1
as
begin
for i in 1 .. 100000
loop
execute immediate
'insert into t values ( :x )' using i ;
commit;
end loop;
end;
/
exec proc_1;
二:动态sql 改成静态sql(涉及到的表名和列明不存在,考虑使用动态sql)
create or replace procedure proc_2
as
begin
for i in 1 .. 100000
loop
insert into t values (i);
commit;
end loop;
end;
/
exec proc_2;
三:批量提交
create or replace procedure proc_3
as
begin
for i in 1 .. 100000
loop
insert into t values (i);
end loop;
commit;
end;
/
exec proc_3;
四:集合写法
insert into t select rownum from dual connect by level<=100000; commit;
五:直接路劲读
create table t as select rownum x from dual connect by level<=100000;
六:并行设置
create table t nologging parallel 64 as select rownum x from dual connect by level<=100000;
要求为(行列转换,超过3个的只取三个,不足3个的用空格来补列)
DROP TABLE TEST;
CREATE TABLE TEST ( ID1 NUMBER,ID2 NUMBER,VALUE1 VARCHAR2(20),VALUE2 VARCHAR2(20));
INSERT INTO TEST VALUES (1,2,'A','B');
INSERT INTO TEST VALUES (1,2,'C','D');
INSERT INTO TEST VALUES (1,2,'E','F');
INSERT INTO TEST VALUES (1,2,'G','H');
INSERT INTO TEST VALUES (3,8,'I','J');
INSERT INTO TEST VALUES (3,8,'K','L');
INSERT INTO TEST VALUES (3,8,'M','N');
INSERT INTO TEST VALUES (8,9,'O','P');
INSERT INTO TEST VALUES (8,9,'Q','R');
INSERT INTO TEST VALUES (11,12,'S','T');
COMMIT;
SQL> SELECT * FROM TEST;
ID1 ID2 VALUE1 VALUE2
---------- ---------- -------------------- --------------------
1 2 A B
1 2 C D
1 2 E F
1 2 G H
3 8 I J
3 8 K L
3 8 M N
8 9 O P
8 9 Q R
11 12 S T
10 rows selected
ID1 ID2 VALUE1 VALUE2 VALUE3 VALUE4 VALUE5 VALUE6
---------- ---------- -------------------- -------------------------------------------------------------
1 2 A B C D E F
3 8 I J K L M N
8 9 O P Q R NULL NULL
11 12 S T NULL NULL NULL NULL
我们可以通过MAX+分析函数实现如下:
SELECT ID1,ID2
,MAX(DECODE(RN,1,VALUE1))
,MAX(DECODE(RN,1,VALUE2))
,MAX(DECODE(RN,2,VALUE1))
,MAX(DECODE(RN,2,VALUE2))
,MAX(DECODE(RN,3,VALUE1))
,MAX(DECODE(RN,3,VALUE2))
FROM (SELECT TEST.*, ROW_NUMBER() OVER(PARTITION BY ID1,ID2 ORDER BY VALUE1,VALUE2) RN FROM TEST) T
WHERE RN<=3
GROUP BY ID1,ID2;
可以将SQL改造为如下
WITH T AS
(select hopbyhop,
svcctx_id,
substr(cause,
instr(cause, 'Host = ') + 7,
instr(cause, 'Priority = ') - instr(cause, 'Host = ') - 11) peer,
substr(cause,
instr(cause, 'Priority = ') + 11,
instr(cause, 'reachable = ') -
instr(cause, 'Priority = ') - 13) priority
from dcc_sys_log
where cause like '%SC路由应答%'
and hopbyhop in (select distinct hopbyhop from dcc_sys_log))---此处多余!
SELECT hopbyhop,svcctx_id,
MAX(DECODE(RN,1,PEER)) PEER1
,MAX(DECODE(RN,1,PRIORITY)) PRIORITY1
,MAX(DECODE(RN,2,PEER)) PEER2
,MAX(DECODE(RN,2,PRIORITY)) PRIORITY2
,MAX(DECODE(RN,3,PEER)) PEER3
,MAX(DECODE(RN,3,PRIORITY)) PRIORITY3
FROM (SELECT T.*, ROW_NUMBER() OVER(PARTITION BY hopbyhop,svcctx_id ORDER BY PEER,PRIORITY) RN FROM T)
WHERE RN<=3
GROUP BY hopbyhop,svcctx_id;
注:涉及到结果集多次使用的时候,尽量用WITH子句,来减少代码,并且易于维护,这个WITH子句处的处理逻辑如下,
只是为了取出Host = 的值和Priority = 的值
SQL> SELECT substr('SC路由应答:Host = SR2@001.ChinaTelecom.com, Priority = 1, reachable = true',
2 instr('SC路由应答:Host = SR2@001.ChinaTelecom.com, Priority = 1, reachable = true', 'Host = ') + 7,
3 instr('SC路由应答:Host = SR2@001.ChinaTelecom.com, Priority = 1, reachable = true', 'Priority = ') - instr('SC路由应答:Host = SR2@001.ChinaTelecom.com, Priority = 1, reachable = true', 'Host = ') - 11) peer,
4 substr('SC路由应答:Host = SR2@001.ChinaTelecom.com, Priority = 1, reachable = true',
5 instr('SC路由应答:Host = SR2@001.ChinaTelecom.com, Priority = 1, reachable = true', 'Priority = ') + 11,
6 instr('SC路由应答:Host = SR2@001.ChinaTelecom.com, Priority = 1, reachable = true', 'reachable = ') -
7 instr('SC路由应答:Host = SR2@001.ChinaTelecom.com, Priority = 1, reachable = true', 'Priority = ') - 13) priority
8 from dual;
写死长度比较不科学,万一数据变化了,值就错误了,写相对位置也比较简单,只要能将层次分清楚即显的简单:
with data as (SELECT 'SC路由应答:Host = SR2@001.ChinaTelecom.com, Priority = 1, reachable = true' as str
,'Host = ' k1
,'Priority = ' k2
FROM DUAL)
,data2 AS (SELECT data.*,INSTR(str,k1) p1,INSTR(str,k2) p2 FROM data)
select SUBSTR(str,p1+LENGTH(k1),INSTR(str,',',p1+1)-p1-LENGTH(k1))
,SUBSTR(str,p2+LENGTH(k2),INSTR(str,',',p2+1)-p2-LENGTH(k2))
from data2;
最终代码:
with data as (select hopbyhop,
svcctx_id,
cause as str,
'Host = ' k1,
'Priority = ' k2
from dcc_sys_log where cause like '%SC路由应答%')
,data2 as (select data.*,instr(str,k1) p1, instr(str,k2) p2 from data)
,data3 as
(select hopbyhop,
svcctx_id,
SUBSTR(str,p1+LENGTH(k1),INSTR(str,',',p1+1)-p1-LENGTH(k1)) peer
,SUBSTR(str,p2+LENGTH(k2),INSTR(str,',',p2+1)-p2-LENGTH(k2)) PRIORITY
from data2)
SELECT hopbyhop,svcctx_id,
MAX(DECODE(RN,1,PEER)) PEER1
,MAX(DECODE(RN,1,PRIORITY)) PRIORITY1
,MAX(DECODE(RN,2,PEER)) PEER2
,MAX(DECODE(RN,2,PRIORITY)) PRIORITY2
,MAX(DECODE(RN,3,PEER)) PEER3
,MAX(DECODE(RN,3,PRIORITY)) PRIORITY3
FROM (SELECT data3.*, ROW_NUMBER() OVER(PARTITION BY hopbyhop,svcctx_id ORDER BY PEER,PRIORITY) RN FROM data3)
WHERE RN<=3
GROUP BY hopbyhop,svcctx_id;
最终的代码:
select distinct to_char(svcctx_id),
to_char(0),
to_char(nvl((select peer_id
from dcc_ne_config
where peer_name = PEER1),
0)),
to_char(priority1),
to_char(nvl((select peer_id
from dcc_ne_config
where peer_name =PEER2),
0)),
to_char(priority2),
to_char(nvl((select peer_id
from dcc_ne_config
where peer_name = PEER3),
0)),
to_char(priority3)
from
(with data as (select hopbyhop,
svcctx_id,
cause as str,
'Host = ' k1,
'Priority = ' k2
from dcc_sys_log where cause like '%SC路由应答%')
,data2 as (select data.*,instr(str,k1) p1, instr(str,k2) p2 from data)
,data3 as
(select hopbyhop,
svcctx_id,
SUBSTR(str,p1+LENGTH(k1),INSTR(str,',',p1+1)-p1-LENGTH(k1)) peer
,SUBSTR(str,p2+LENGTH(k2),INSTR(str,',',p2+1)-p2-LENGTH(k2)) PRIORITY
from data2)
SELECT hopbyhop,svcctx_id,
MAX(DECODE(RN,1,PEER)) PEER1
,MAX(DECODE(RN,1,PRIORITY)) PRIORITY1
,MAX(DECODE(RN,2,PEER)) PEER2
,MAX(DECODE(RN,2,PRIORITY)) PRIORITY2
,MAX(DECODE(RN,3,PEER)) PEER3
,MAX(DECODE(RN,3,PRIORITY)) PRIORITY3
FROM (SELECT data3.*, ROW_NUMBER() OVER(PARTITION BY hopbyhop,svcctx_id ORDER BY PEER,PRIORITY) RN FROM data3)
WHERE RN<=3
GROUP BY hopbyhop,svcctx_id) t2
忽略SQL改造等价性

max min的写法,分开写性能快。
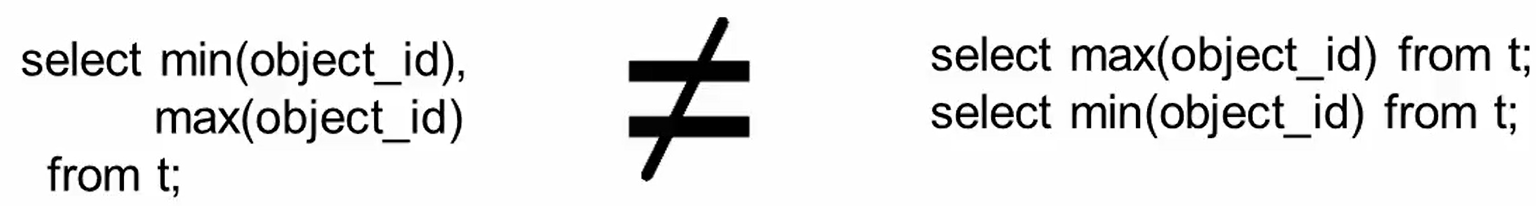
这样写是等价的

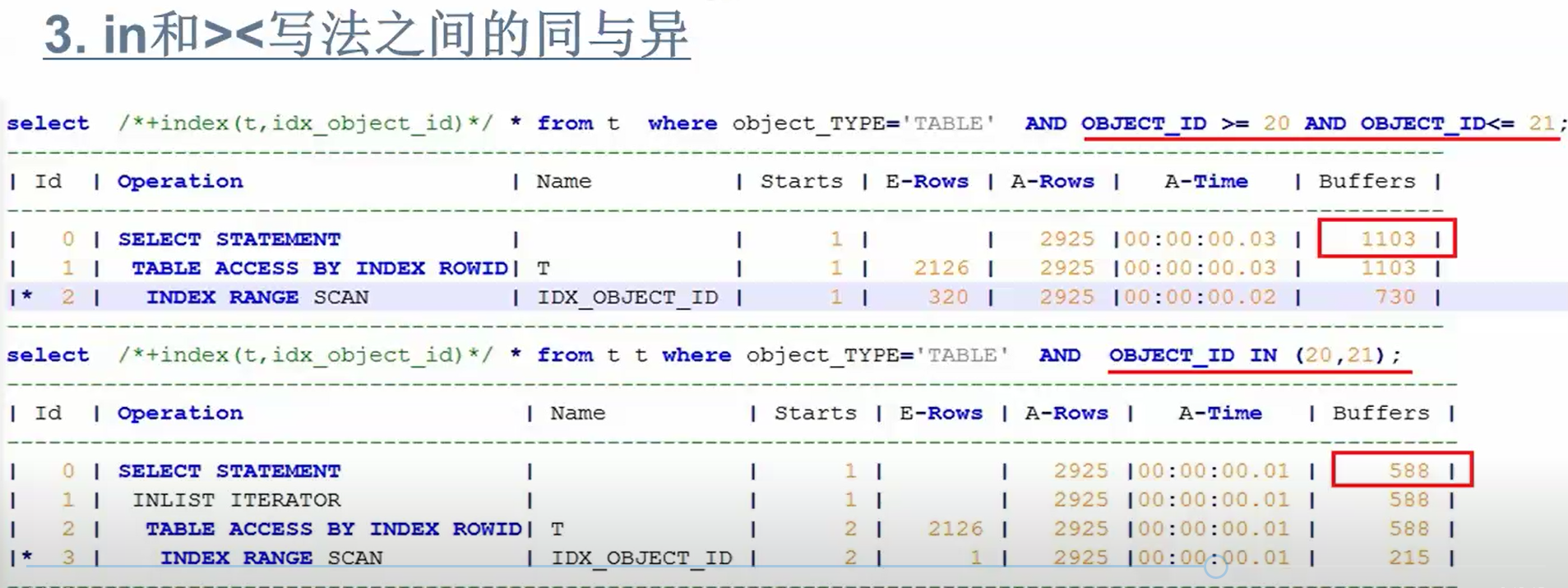
drop table t purge; create table t as select * from dba_objects; create index idx_object_id on t(object_id,object_type); UPDATE t SET OBJECT_ID=20 WHERE ROWNUM<=26000; UPDATE t SET OBJECT_ID=21 WHERE OBJECT_ID<>20; COMMIT; set linesize 266 set pagesize 1 alter session set statistics_level=all ; select /*+index(t,idx_object_id)*/ * from t where object_TYPE='TABLE' AND OBJECT_ID >= 20 AND OBJECT_ID<= 21; select * from table(dbms_xplan.display_cursor(null,null,'allstats last')); ------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | ------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | | 2925 |00:00:00.03 | 1103 | | 1 | TABLE ACCESS BY INDEX ROWID| T | 1 | 2126 | 2925 |00:00:00.03 | 1103 | |* 2 | INDEX RANGE SCAN | IDX_OBJECT_ID | 1 | 320 | 2925 |00:00:00.02 | 730 | ------------------------------------------------------------------------------------------------------- select /*+index(t,idx_object_id)*/ * from t t where object_TYPE='TABLE' AND OBJECT_ID IN (20,21); select * from table(dbms_xplan.display_cursor(null,null,'allstats last')); --------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Starts | E-Rows | A-Rows | A-Time | Buffers | --------------------------------------------------------------------------------------------------------- | 1 | INLIST ITERATOR | | 1 | | 2920 |00:00:00.01 | 563 | | 2 | TABLE ACCESS BY INDEX ROWID| t | 2 | 2592 | 2920 |00:00:00.01 | 563 | |* 3 | INDEX RANGE SCAN | IDX1_OBJECT_ID | 2 | 1 | 2920 |00:00:00.01 | 214 | --------------------------------------------------------------------------------------------------------

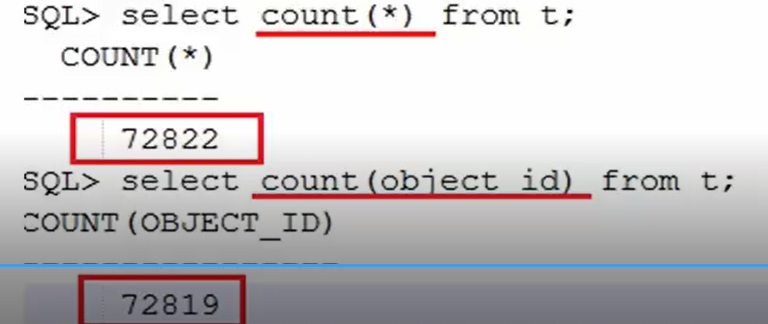
drop table t purge; create table t as select * from dba_objects; update t set object_id =null where rownum<=2; set autotrace off select count(*) from t; select count(object_id) from t;