“ 我们经常在多表查询的时候使用join 去连接多个表,其实join的效率比不好还是应该尽量避免使用的,其本质就是各个表之间循环匹配的,MySQL中只支持一种join算法Nested-Loop Join(循环嵌套连接),但是其有多种变种的算法提高join的执行效率。”
1. Simple Nested-Loop Join(SNL,简单嵌套循环连接)
Simple Nested-Loop join(NLJ)算法从循环中的第一个表中一次读取一行,将每一行传递给一个嵌套循环,该嵌套循环中匹配数据是否一致。例如驱动表User,被驱动表UserInfo 的sql是 select * from User u left join User_info info on u.id = info.user_id,其实就是我们常用的for循环,伪代码的逻辑应该是
for(User u:Users){ for(UserInfo info:UserInfos){ if(u.id == info.userId){ // 得到匹配数据 } } }
简单粗暴的算法,每次从User表中取出一条数据,然后扫描User_info中的所有记录匹配,最后合并数据返回。
假如驱动表User有10条数据,被驱动表UserInfo也有10条数据,那么实际上驱动表User会被扫描10次,而被驱动表会被扫描10*10=100次(每扫描一次驱动表,就会扫描全部的被驱动表),这种效率是很低的,对数据库的开销比较大,尤其是被驱动表。每一次扫描其实就是从硬盘中读取数据加载到内存中,也就是一次IO,目前IO是最大的瓶颈
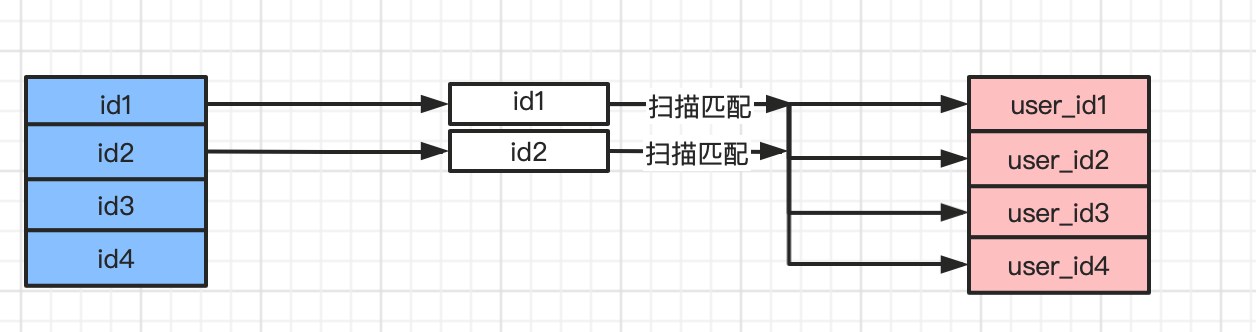
2. Index Nested-Loop Join(INL,索引嵌套循环连接)
索引嵌套循环是使用索引减少扫描的次数来提高效率的,所以要求非驱动表上必须有索引才行。
在查询的时候,驱动表(User) 会根据关联字段的索引进行查询,当索引上找到符合的值,才会进行回表查询。如果非驱动表(User_info)的关联字段(user_id)是主键的话,查询效率会非常高(主键索引结构的叶子结点包含了完整的行数据(InnoDB)),如果不是主键,每次匹配到索引后都需要进行一次回表查询(根据二级索引(非主键索引)的主键ID进行回表查询),性能肯定弱于主键的查询。

上图中的索引查询之后不一定会回表,什么情况下会回表,这个要看索引查询到的字段能不能满足查询需要的字段,
索引相关的具体可以参考之前的文章:你需要知道的一些索引基础知识 和 B+树的索引知识。
3. Block Nested-Loop Join(BNL,块嵌套循环连接)
如果存在索引,那么会使用index的方式进行join,如果join的列没有索引,被驱动表要扫描的次数太多了,每次访问被驱动表,其表中的记录都会被加载到内存中,然后再从驱动表中取一条与其匹配,匹配结束后清除内存,然后再从驱动表中加载一条记录 然后把被驱动表的记录在加载到内存匹配,这样周而复始,大大增加了IO的次数。为了减少被驱动表的IO次数,就出现了Block Nested-Loop Join的方式。
不再是逐条获取驱动表的数据,而是一块一块的获取,引入了join buffer缓冲区,将驱动表join相关的部分数据列(大小是join buffer的限制)缓存到join buffer中,然后全表扫描被驱动表,被驱动表的每一条记录一次性和join buffer中的所有驱动表记录进行匹配(内存中操作),将简单嵌套循环中的多次比较合并成一次,降低了被驱动表的访问频率。
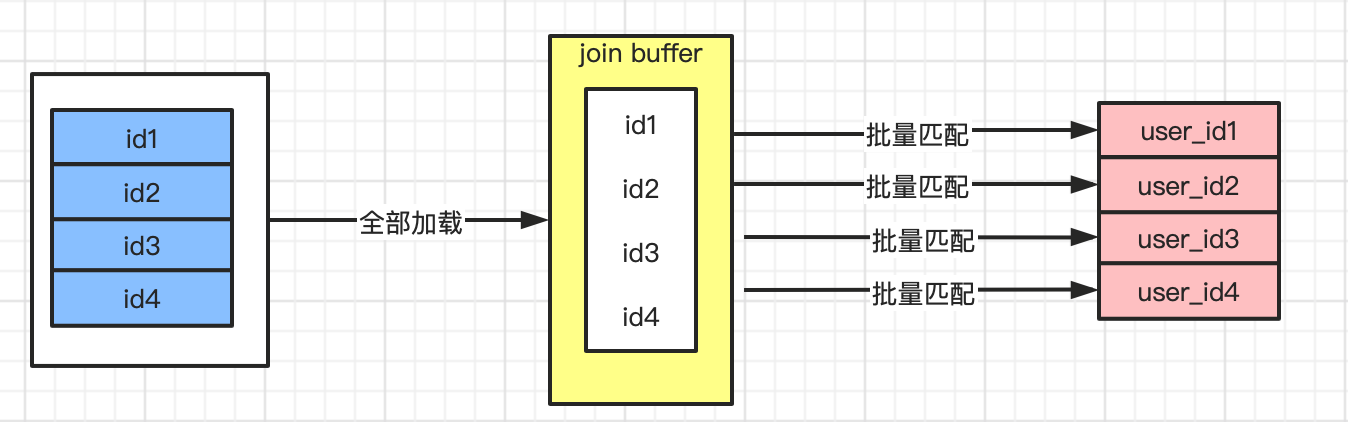
驱动表能不能一次加载完,要看join buffer能不能存储所有的数据,默认情况下join_buffer_size=256k,查询的时候Join Buffer 会缓存所有参与查询的列而不是只有join关联的列,在一个有N个join关联的sql中会分配N-1个join buffer。所以查询的时候尽量减少不必要的字段,可以让join buffer中可以存放更多的列。
可以调整join_buffer_size的缓存大小show variables like '%join_buffer%'这个值可以根据实际情况更改。

使用Block Nested-Loop Join算法需要开启优化器管理配置的optimizer_switch的设置block_nested_loop为on,默认是开启的。可以通过 show variables like '%optimizer_switch%' 查看block_nested_loop状态。

以上三种算法了解即可,其实实际工作中只要我们能都用好索引就不错了,即使是join的连接也要注意关联字段是否建立索引,还是要善于使用索引来提供查询效率。
关注不迷路
MySQL高级相关更多内容,如事务,锁,MVCC,读写分离,分库分表等还在持续更新中,欢迎关注催更。
我是阿纪,用输出倒逼输入而持续学习,持续分享技术系列文章,以及全网值得收藏好文,欢迎关注公众号,做一个持续成长的技术人。

MySQL系列的历史文章
3. MySQL进阶系列:mysql中MyISAM和InnoDB有什么区别;
4. MySQL进阶系列:mysql中表设计如何更好的选择数据类型;
5. MySQL进阶系列:数据库设计中的范式究竟该如何使用;
6. MySQL进阶系列:一文详解explain各字段含义;