@
问题引出
要求将统计结果按照条件输出到不同文件中(分区)。
比如:将统计结果按照手机归属地不同省份输出到不同文件中(分区)
默认Partitioner分区
public class HashPartitioner<K,V> extends Partitioner<K,V>{
public int getPartition(K key,V value, int numReduceTasks){
return (key.hashCode() & Integer.MAX VALUE) & numReduceTasks;
}
}
- 默认分区是根据key的hashCode对ReduceTasks个数取模得到的。
- 用户没法控制哪个key存储到哪个分区。
自定义Partitioner步骤
- 自定义类继承
Partitioner,重写getPartition()方法
public class CustomPartitioner extends Partitioner<Text,FlowBea>{
@Override
public int getPartition(Text key,FlowBean value,int numPartitions){
//控制分区代码逻辑
……
return partition;
}
}
- 在Job驱动类中,设置自定义
Partitioner
job.setPartitionerClass(CustomPartitioner.class)
- 自定义Partition后,要根据自定义Partitioner的逻辑设置相应数量的
ReduceTask
job.setNumReduceTask(5);//假设需要分5个区
Partition分区案例实操
将统计结果按照手机归属地不同省份输出到不同文件中(分区)
输入数据:
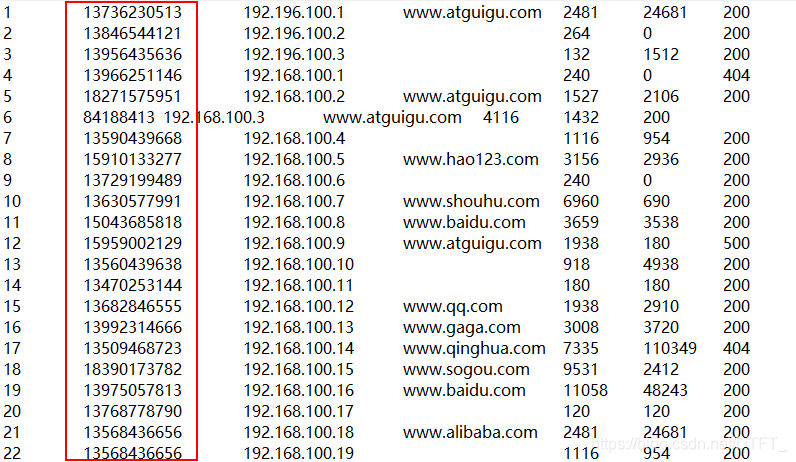
期望输出数据:
手机号136、137、138、139开头都分别放到一个独立的4个文件中,其他开头的放到一个文件中。所以总共分为5个文件,也就是五个区。
相比于之前的自定义flowbean,这次自定义分区,只需要多编写一个分区器,以及在job驱动类中设置分区器,mapper和reducer类不改变
MyPartitioner.java
/*
* KEY, VALUE: Mapper输出的Key-value类型
*/
public class MyPartitioner extends Partitioner<Text, FlowBean>{
// 计算分区 numPartitions为总的分区数,reduceTask的数量
// 分区号必须为int型的值,且必须符合 0<= partitionNum < numPartitions
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
String suffix = key.toString().substring(0, 3);//前开后闭,取手机号前三位数
int partitionNum=0;//分区编号
switch (suffix) {
case "136":
partitionNum=numPartitions-1;//由于分区编号不能大于分区总数,所以用这种方法比较好
break;
case "137":
partitionNum=numPartitions-2;
break;
case "138":
partitionNum=numPartitions-3;
break;
case "139":
partitionNum=numPartitions-4;
break;
default:
break;
}
return partitionNum;
}
}
FlowBeanDriver.java
public class FlowBeanDriver {
public static void main(String[] args) throws Exception {
Path inputPath=new Path("e:/mrinput/flowbean");
Path outputPath=new Path("e:/mroutput/partitionflowbean");
//作为整个Job的配置
Configuration conf = new Configuration();
//保证输出目录不存在
FileSystem fs=FileSystem.get(conf);
if (fs.exists(outputPath)) {
fs.delete(outputPath, true);
}
// ①创建Job
Job job = Job.getInstance(conf);
// ②设置Job
// 设置Job运行的Mapper,Reducer类型,Mapper,Reducer输出的key-value类型
job.setMapperClass(FlowBeanMapper.class);
job.setReducerClass(FlowBeanReducer.class);
// Job需要根据Mapper和Reducer输出的Key-value类型准备序列化器,通过序列化器对输出的key-value进行序列化和反序列化
// 如果Mapper和Reducer输出的Key-value类型一致,直接设置Job最终的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
// 设置输入目录和输出目录
FileInputFormat.setInputPaths(job, inputPath);
FileOutputFormat.setOutputPath(job, outputPath);
// 设置ReduceTask的数量为5
job.setNumReduceTasks(5);
// 设置使用自定义的分区器
job.setPartitionerClass(MyPartitioner.class);
// ③运行Job
job.waitForCompletion(true);
}
}
FlowBeanMapper.java
/*
* 1. 统计手机号(String)的上行(long,int),下行(long,int),总流量(long,int)
*
* 手机号为key,Bean{上行(long,int),下行(long,int),总流量(long,int)}为value
*
*
*
*
*/
public class FlowBeanMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
private Text out_key=new Text();
private FlowBean out_value=new FlowBean();
// (0,1 13736230513 192.196.100.1 www.atguigu.com 2481 24681 200)
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, FlowBean>.Context context)
throws IOException, InterruptedException {
String[] words = value.toString().split(" ");
//封装手机号
out_key.set(words[1]);
// 封装上行
out_value.setUpFlow(Long.parseLong(words[words.length-3]));
// 封装下行
out_value.setDownFlow(Long.parseLong(words[words.length-2]));
context.write(out_key, out_value);
}
}
FlowBeanReducer.java
public class FlowBeanReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
private FlowBean out_value=new FlowBean();
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Reducer<Text, FlowBean, Text, FlowBean>.Context context)
throws IOException, InterruptedException {
long sumUpFlow=0;
long sumDownFlow=0;
for (FlowBean flowBean : values) {
sumUpFlow+=flowBean.getUpFlow();
sumDownFlow+=flowBean.getDownFlow();
}
out_value.setUpFlow(sumUpFlow);
out_value.setDownFlow(sumDownFlow);
out_value.setSumFlow(sumDownFlow+sumUpFlow);
context.write(key, out_value);
}
}
FlowBean.java
public class FlowBean implements Writable{
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean() {
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
// 序列化 在写出属性时,如果为引用数据类型,属性不能为null
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
//反序列化 序列化和反序列化的顺序要一致
@Override
public void readFields(DataInput in) throws IOException {
upFlow=in.readLong();
downFlow=in.readLong();
sumFlow=in.readLong();
}
@Override
public String toString() {
return upFlow + " " + downFlow + " " + sumFlow;
}
}
输出结果:
总共五个文件
一号区:

二号区:

三号区:

四号区:

其他号码为第五号区:

分区总结
- 如果
ReduceTask的数量 > getPartition的结果数,则会多产生几个空的输出文件part-r-000xx - 如果
Reduceask的数量 < getPartition的结果数,则有一部分分区数据无处安放,会Exception - 如果
ReduceTask的数量 = 1,则不管MapTask端输出多少个分区文件,最终结果都交给这一个ReduceTask,最终也就只会产生一个结果文件partr-00000
以刚才的案例分析:
例如:假设自定义分区数为5,则
- job.setlNlurmReduce Task(1);会正常运行,只不过会产生一个输出文件
- job.setlNlunReduce Task(2),会报错
- job.setNumReduceTasks(6);大于5,程序会正常运行,会产生空文件