一、索引使用规则
1、【强制】禁止使用全模糊查询
全模糊查询无法使用索引,应当尽可能避免。
原因:like本身效率就比较低,应该尽量避免查询条件使用like;对于like ‘%...%’(全模糊)这样的条件,是无法使用索引的,全表扫描自然效率很低;另外,由于匹配算法的关系,模糊查询的字段长度越大,模糊查询效率越低。
解决方案:首先尽量避免模糊查询,如果因为业务需要一定要使用模糊查询,则至少保证不要使用全模糊查询,对于右模糊查询,即like ‘…%’,是会使用索引的;左模糊like ‘%...’无法直接使用索引,但可以利用reverse + function index 的形式(在程序中把要查询的字段调转),变化成 like ‘…%’;全模糊是无法优化的,一定要的话考虑用搜索引擎(ES)。出于降低服务器的负载考虑,尽可能地减少数据库模糊查询。
2、【强制】要求条件中,or前后的字段都为索引
在使用or分割条件时,若or前的列有索引,而or后的列没有索引,则索引都不会被使用到
3、【强制】要求必须使用复合索引的第一列
在使用复合索引时,若只使用了复合索引非第一列的其他字段,则索引不生效。所以要求必须带有复合索引的第一列,并且注意,在建立复合索引时将区分度高的放在第一个。
单一索引:单一索引是指索引列为一列的情况,即新建索引的语句只实施在一列上,也叫普通索引
CREATE INDEX indexName ON mytable(username);
复合索引:用户可以在多个列上建立索引,这种索引叫做复合索引(组合索引);复合索引在数据库操作期间所需的开销更小,可以代替多个单一索引。
CREATE INDEX PersonIndex ON Person (LastName, FirstName)
对于复合索引:Mysql从左到右的使用索引中的字段,一个查询可以只使用索引中的一部份,但只能是最左侧部分。例如索引是key index (a,b,c). 可以支持a | a,b| a,b,c 3种组合进行查找,但不支持 b,c进行查找 。
同时有两个概念叫做窄索引和宽索引,窄索引是指索引列为1-2列的索引,宽索引也就是索引列超过2列的索引; 设计索引的一个重要原则就是能用窄索引不用宽索引,因为窄索引往往比宽索引更有效。
4、【强制】禁止创建重复索引
创建索引时,索引的命名不能相同;不能对表中指定一列创建两个索引。
5、【强制】创建索引的个数不超过五个
一个表最多16个索引,在开发中不能超过五个
6、【强制】禁止索引字段的长度过长,建议不超过3072字节
二、函数使用规则
1、【建议】时间函数
谨慎使用SYSDATE(),now()等时间函数,推荐由应用服务器获取时间进行赋值(因后续有可能从单机数据库向分布式数据库迁移,所以在这里进行了建议要求)。
NOW()取的是语句开始执行的时间,SYSDATE()取的是动态的实时时间。
因为NOW()取自mysql的一个变量”TIMESTAMP”,而这个变量在语句开始执行的时候就设定好了,因此在整个语句执行过程中都不会变化。

2、【建议】聚合函数
建议使用count(*)作为计数操作
1)若表中无空字段,则可以使用select count(1) from tableName 的方式来进行统计;
2)若表中有空字段,则可以使用select count(*) from tableName 的方式来进行统计。
按照效率排序的话,count(字段)<count(主键id)<count(1) ≈count(*),尽量使用 count(*)
原则:
- server 层要什么就给什么;
- InnoDB 只给必要的值;
- 现在的优化器只优化了 count(*) 的语义为“取行数”,其他“显而易见”的优化并没有做。
对于 count(主键 id) 来说,InnoDB 引擎会遍历整张表,把每一行的 id 值都取出来,返回给 server 层。server 层拿到 id 后,判断是不可能为空的,就按行累加。
对于 count(1) 来说,InnoDB 引擎遍历整张表,但不取值。server 层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。
对于 count(字段) 来说:
如果这个“字段”是定义为 not null 的话,一行行地从记录里面读出这个字段,判断不能为 null,按行累加;
如果这个“字段”定义允许为 null,那么执行的时候,判断到有可能是 null,还要把值取出来再判断一下,不是 null 才累加。也就是前面的第一条原则,server 层要什么字段,InnoDB 就返回什么字段。
对于count(*) 来说:并不会把全部字段取出来,而是专门做了优化,不取值。count(*) 肯定不是 null,按行累加。
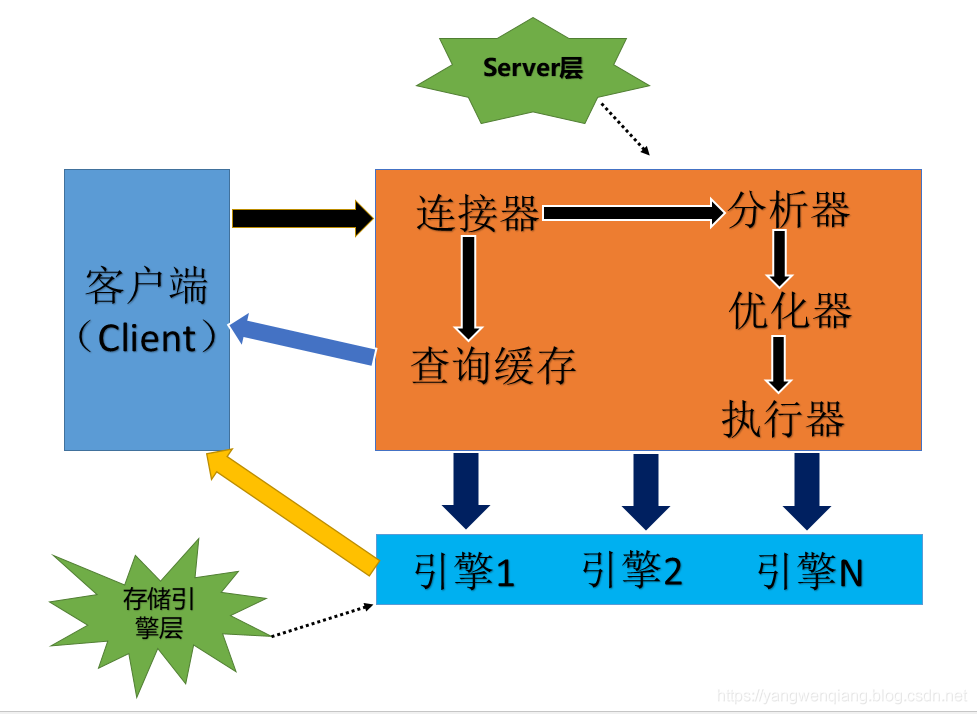
MySQL基本逻辑架构图:
3、【强制】禁止使用自定义函数
三、JOIN使用规则