摘要
mvc是一种软件设计模式,最早由Trygve Reenskaug在1978年提出,他有效的解决了表示层,控制器层,逻辑层的代码混合在一起的问题,很好的做到了职责分离。但是在实际的编码实践过程中,你会发现这个模式随着业务的扩展,变的逻辑混乱,代码重合度很高。这里提出借鉴DDD思想的一种新的工程结构
mvc的问题
通常一个前后端分离的系统,后端工程系统结构图通常下面这样
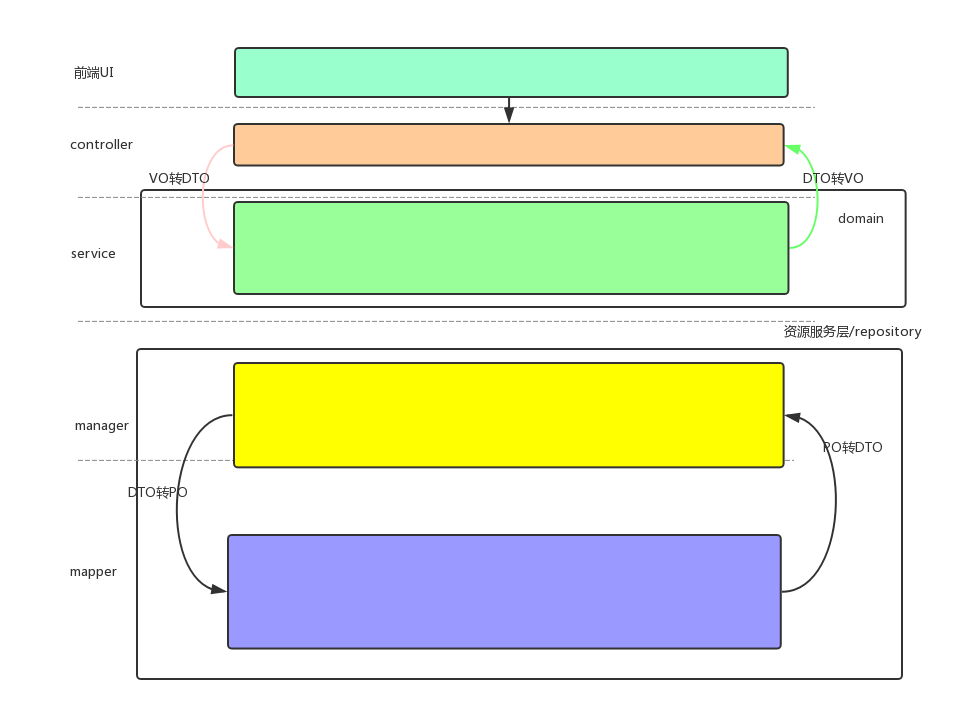
1. 四层 controller/service/manager/mapper
2. 不可以同级调用
3. 上级可以知晓下级,下级不可知晓上级,也就是bean的转化放在上级
这个分层结构职责分离是按照纵向切分的
1. 资源服务层repository是面向DB编程
2. service层是面向前端页面编程。
也就是说,对于某一块的业务,他没有将逻辑抽象到一起,他只是将一次request按照纵向切分了。没有进行横向的业务切分。
这样将会导致的问题
职责分散,逻辑重复度高
- bean的创建太随意,基本就是一个需求对应一些dto, vo,query bean
- 不同开发者对于同一个领域的东西有不同的bean,同一个开发者对于相同逻辑的bean,过了几个月,又定义出一个差不多的bean
没有边界
- 根本没有上下文/边界的概念,比如说店铺会和用户有交互,订单会和用户有交互,通常在DB存储时只会存关联id,然后需要去取对应的名称,其他属性信息。这些信息的获取,有些开发在manager层操作,然后将属性定义到了店铺相关的DTO中;有些放在了service层做。controller/service/manager各个层次都可以调用,没有任何约束。
mvc的演进
按照上述的说明,在一个单体服务中,随着业务的不断迭代,可能会发生什么严重的问题。
举几个真实鲜活的例子
分库分表的例子
实体A是我们业务中的一个基础的重要的实体,对应的数据表tableA,一开始业务很简单,只有1个服务,在这个服务里面调用。后来业务扩张了,有十几个服务了,然后十几个服务直接查这个tableA。tableA也扩张成为了tableA,tableB,tableC。有些人觉得代码重复度高了,将mapper/manager层拆成共通的部分打成一个jar包,然后各个微服务中引入这个jar。业务变得更加复杂了,服务扩展到几十个了,tableA数据也有几千万了,这时候要做分库分表了,怎么整。
最后花了差不多1年,涉及十几个团队,才把这个mapper/manager调用改掉,然后做分库分表。
有人可能觉得这个只要在服务拆分时,避免直接调用就可以了,那再举个其他类型的例子。
用户等级的例子
用户的等级,用户的分级是很复杂的,不同的业务阶段有这个不同的定义。比如一开始定义一个字段叫grade的代表用户等级。
然后各个业务都在查这个表的字段grade进行判断,然后产品需要改了,增加了判断必须同时要达到什么条件才能称作等级x。这时候你又得满世界的改了。
DDD的工程架构
那如何运用DDD的思想进行改造呢
核心思想:封装领域内的逻辑,统一对外暴露的入口,防止业务逻辑泄露。
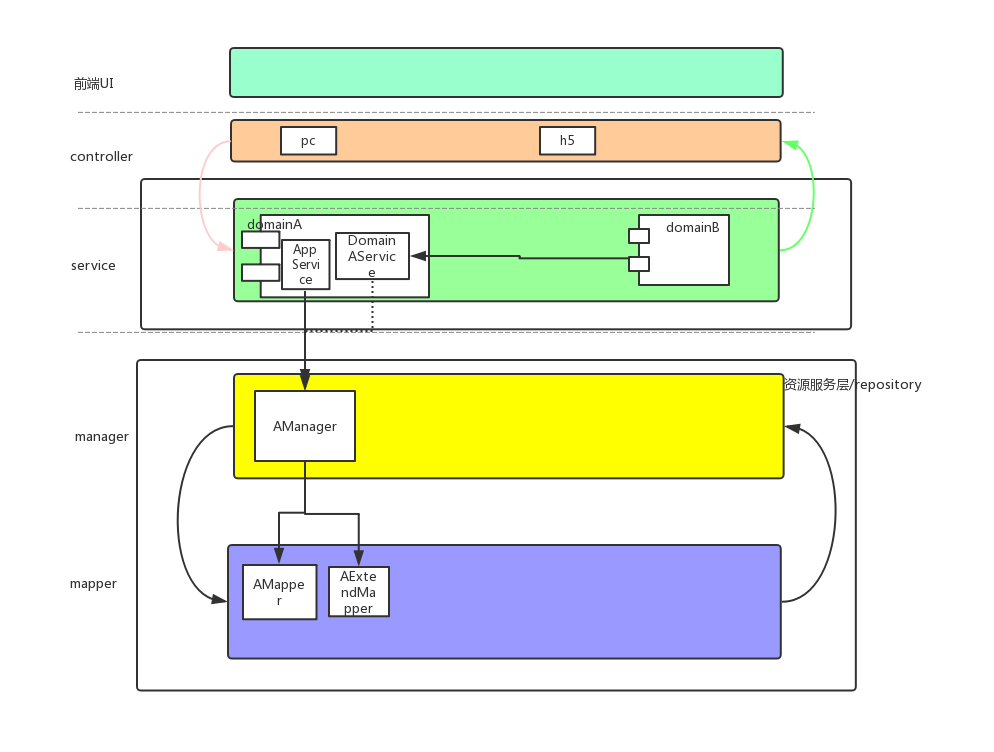
- 在mvc纵向切分的基础上,增加一层领域的横向切分
- 同一个工程里面,领域之间的调用只能通过domainService,这样可以屏蔽领域内的数据库是如何持久化的,业务逻辑是如何判断的、算法是如何实现的。
service之间可以直接调用。 - 领域内还是纵向切分,安装mvc分层结构。
上面的只是一个草图,我们真实的结构图比这要稍微复杂些。领域内会区分领域对象,领域服务,基础设施层。这样在领域内进行指责分离,不过从实际的执行过程中领域内的比较细节,执行起来ROI比较低,推荐大家可以先按这套执行。
画外音:估计有些程序员看到这个工程结构变化呵呵一笑,觉得没多大价值,没什么改变必要。
这种工程的结构划分从提出来的到真正被我们团队成员接受的时间周期差不多是8个月。
原因大概是这么几类
- 引入新的分层,太复杂了,增加了代码复杂度
- 我这块业务很简单,CRUD就行了,没涉及到服务之间的交互。直接mvc一条道走到黑就可以。
如果你看这篇文章也是这种感受,不妨花点时间看下你们业务的代码,看看重复度有多高,看看逻辑有多散乱。你就会明白。
DDD工程的演进
DDD工程的演进也就是服务的拆分了,放到下期讲。
总结
很多DDD的文章都在说传统的编程方式是面试数据库编程,导致对象中只有getter,setter,也就是贫血模型,贫血模型是没有业务逻辑,面向过程设计,不符合面向对象设计原则。
对于这个结论我是同意的,但是对于造成的原因不是很同意。个人认为造成这个原因的主要原因还是在于长期以来的MVC这种模式只有纵向切分导致。如果结合横向切分,有没有DDD也无所谓。这里再引用一下驱动方法不能改变任何事情这段话,如果你能深入理解职责、封装。并随着业务的迭代,不断的重构你的代码,那么你不需要什么DDD,或者其他方法论。
使用职责、封装和组合;
以接口的视角思考,即“人们如何使用我的组件?”;
使用相关技术写好代码,包括可读性、信息性、简洁、自描述,尽量避免显式地使用模式;
有能力回答特定业务的“本质”;“本质”是一个模型,但不意味着类和方法,它意味着回答问题“这个业务如何真正地工作?”
因为这些约束,都是强迫你去思考,去做职责的思考,去做模块的封装。如果你/你团队成员已经领会其中的道理并很好的运用,还需要这些条条框框干吗呢?
下一篇领域与微服务划分,欲知后事如何,请听下回分解。
相关阅读
https://www.cnblogs.com/stoneFang/p/10888630.html
关注【方丈的寺院】,第一时间收到文章的更新,与方丈一起开始技术修行之路
