1、transformer
transformer就是大名鼎鼎的论文《Attention Is All You Need》[1],其在一些翻译任务上获得了SOTA的效果。其模型整体结构如下图所示
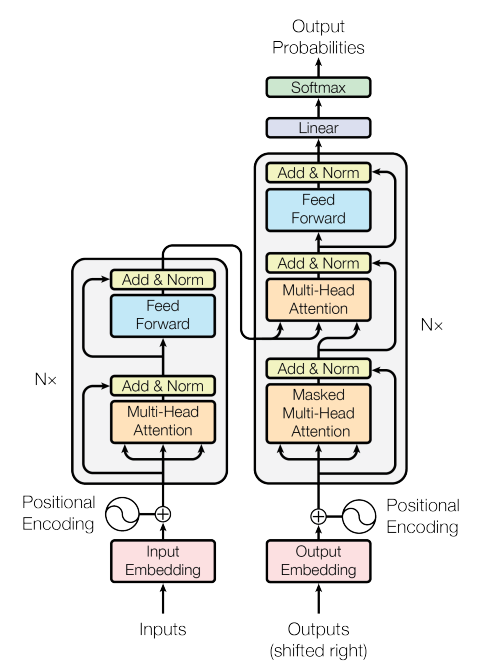
- encoder和decoder
其整体结构由encoder和decoder组成,其中encoder由6个相同的block组成,每个block由相同的结构组成,都包括一个muti_head self-attention结构和全连接组成,在这两个子层的输出,都含有一个BN标准化。在decoder阶段,也是由相同的6个block组成,其在encoder结构的基础上又加入了一个子层,目的是为了和encoder的输出做操作。 - muti_head self-attention
这里多头的意思就是将我们原本的输入词向量在维度上进行切分,假如我们的输入的词向量维度是[512,10,300],假设我们的头的个数是10个,那么将向量经过转换,转成[512,10,10,30]的向量,我们这里以一个头举例,同时,只取一条数据,即向量为[10,30]那么这里回通过一个全连接操作,得到Q,K,V向量,这里Q,K,V向量的维度均为[10,30],对于10个头来说,我们会获得10个这样的Q,K,V。接下来进行如下操作
这里,d_{k}就是30,最终,我们会得到[10,30]的向量,首先,(QK^{T})的乘积是为了得到这10个单词在自己的10个单词的权重,所以维度为[10,10],除以(sqrt{d_{k}}),论文中说是猜测如果(d_{k})过大,会导致在softmax求梯度的时候梯度过小,论文中还举了个栗子,比如两个以正太分布均值=0,方差为1的向量[10,30],[10,30],那么再进行向量乘法操作后,得到的就是均值=0,方差为30的向量。
最后得到输出后,将向量进行拼接,再加上一个全连接操作,即可得到一个block的输出。
- Positional Encoding
论文中介绍了一种假如positional encodeing的方法
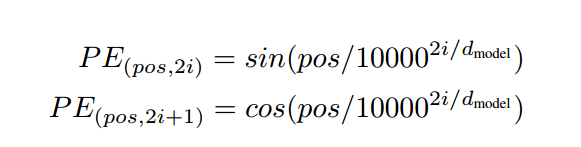
其中,pos为单词在句子中的位置,这里pos取1-10,(d_{model})表示向量的维度,以上面的栗子为例,就是300,(i)表示第几个位置,这里i取值1-300
2、GPT
GPT是由openAI提出的一种算法思想[2],其主要思想是通过在大规模的预料上进行模型的训练,然后在特定任务上进行为调。所以其总体思想分为无监督的训练和有监督的微调。
-
无监督的训练
无监督的训练是指我们首先对模型用大规模的语料进行训练,得到相应的参数。比如我们常用的word embedding,固定在输入向量,然后随着模型一起训练的过程。在本论文中,用的是transformer模型作为预训练模型,其公式如下
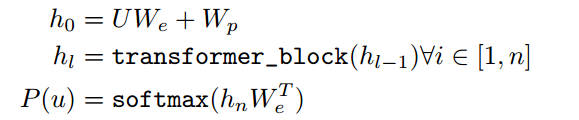
在第一个式子中,(U)代表输入的单词token,(W_{e})代表单词的词向量,(W_{p})代表位置向量。第二个式子中,我们将向量加和作为输入,经过transformer模型,最终得到输出(h_{l})。最后对于输出层,加上一个全连接然后接一个softmax层,得到每个单词在相应位置的概率,其中,对于一条输入,均含有其对应的上下文单词,我们在softmax最大化这个单词所在节点的概率即可。 -
有监督的微调
当我们用大量的语料进行模型的训练后,就会得到相应模型的参数,接着,我们可以用我们的特定任务在这个模型参数的基础上进行训练,以一些分类任务为例,这里我们将transfomer的输出加上一个softmax层,最终输出的节点个数即为类别标签的个数。在论文中微调损失函数既有分类标签的的损失,也有预训练中损失,所以最终的损失函数是两者的加和。这里分类的损失可以理解,但是预训练中的损失是什么?他的上下文输出的单词是什么?这里我的理解是对于一个句子依旧给他一个窗口,然后类似于word2vec,其中一个损失是预训练的损失,另一个损失是对于标签分类的损失。如下公式所示,(L_{2}(C))是分类的损失,(L_{1}(C))是预训练的损失,在这里,我们可以对预训练的损失设定权值。
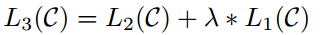
-
总体架构图
总体架构图如下所示,这里我们看到,对于不同的任务的微调,有不同的处理方法,对于分类任务,我们直接输入相应的句子,在输出层加上一个softmax,对于一些句子对输入的任务,我们利用一些相应的标记,进行拼接,最终输出也是用softmax进行分类。
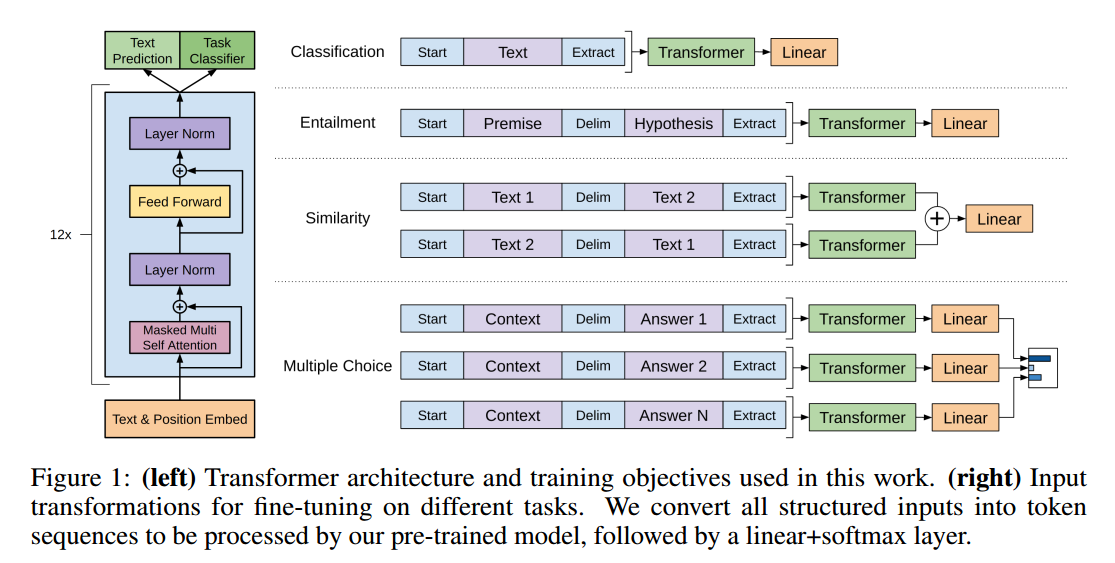
3、bert
bert是由Google的一些研究者们提出的一种算法[3],其沿用了GPT的用大规模的语料进行预训练,然后在下游任务进行微调的方式,其中预训练的基础模型依然用的是transformer模型,bert在embedding层用了三种方式的embedding累加,并且提出了双向的语言模型,这比GPT的单向语言模型更能学到语义的信息。并且加入了next sentence prediction方式作为loss的一部分,最终在多个任务上达到了sota的效果。
- input embedding
输入的embedding有三种方式组成,第一种就是我们的单词embedding,假设输入的句子序列,经过编码是[3,5,7,8,4,5,4],词典的大小为N,向量的维度为d,那么第一个token embedding为[7,d]的向量。第二个是sentence embedding,出现这个的原因是如果输入的句子如果是两个的话,那么我们分别用0表示第一条句子,用1表示第二条句子,比如这两条句子组合之后分别是[0,0,0,0,1,1,1],sentence embedding的维度是[2,d],最终,经过embedding,得到[7,d]的矩阵表示,其中前4条向量相同,后3条向量相同。第三个是position embedding,即位置的embedding,假设句子的最大长度为128,那么会生成一个[128,d]的矩阵,原始数据的位置表示为[0,1,2,3,0,1,2],这样我们得到各自位置上的句子表示,最终也为[7,d]。最后,我们将这三个向量进行相加得到输入的embedding。结构如下图所示
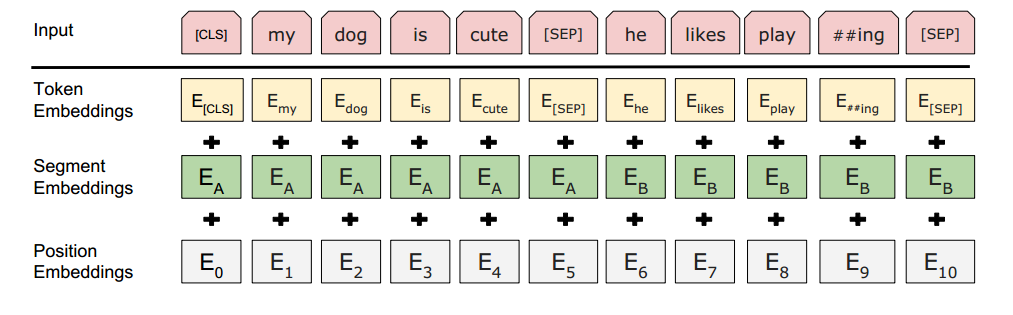
- 输入的标记
在bert种,为了区分两条句子,用[CLS]表示所有句子的开头,用[SEP]来分隔两个句子,则我们得到的输入为[[CLS],3,5,7,8,[SEP],4,5,4[SEP]]这样的输入形式。 - Masked LM
Masked LM是为了解决语言模型单向训练的问题,首先,将训练数据中80%的单词用mask表示,将10%的单词用该句子中随机的单词来代替,另外10%保持不变。在输出层的时候,我们用这些被mask和被替代的单词来预测原始的单词,最终算得损失函数。比如我们的输入可能会变成
[[CLS],[MASK],5,8,8,[SEP],4,[MASK],4[SEP]] - next sentence predition
如上所述,在预训练的时候,我们会输入两个句子,但正常情况下我们只有一个句子,那么如何进行构造呢?我们会将一个完整的句子进行分割成2个部分,第二个部分以50%的概率随机替换为其他的句子,如果替换了,那么is_next为0,否则为1。在最终的输出层,我们会构造两个输出节点,类似于二分类,来预测这两个句子是否是同一个句子中的句子。从而计算损失函数,最终的损失函数为Masked LM损失函数两者的和。 - 微调
当我们用大规模的语料训练好bert模型后,可以根据自己下游的业务继续进行训练。
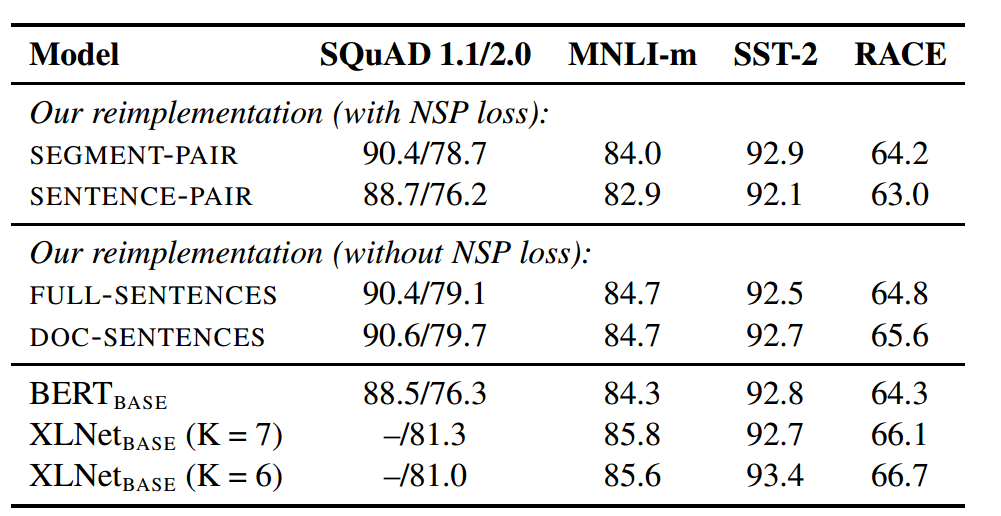
4、RoBERTa
该论文是由fb和华盛顿大学联合提出的一种方法[4],这篇文章的创新点不多,更像是对BERT的进一步炼丹,通过调整一些参数,步长等,最终在多个任务中取得了SOTA的效果,所以说,如果丹炼的好,相同的模型,也可以超过之前的效果。RoBERTa主要实验调优的方面有:1、增大训练数据集,增大batch,增大epoch。2、将static masked LM 换成dynamic masked LM。3、去掉NSP。4、用字节代替字符。
- 增大训练数据集,增大batch,增大epoch
RoBERTa使用更多的数据集,总计160G,其中包括BOOKCORPUS(16G),CC-NEWS(过滤后76G),OPENWEBTEXT(38G),STORIES(31G)。
原始bert用的是batch_size为256,steps为1M,RoBERTa用了两组,一组是batch_size为2k,steps为125k,另外一组是batch_size为8k,steps为31k
增大之后的效果如下图所示,可以看到,效果虽有提升,但是整体一般。
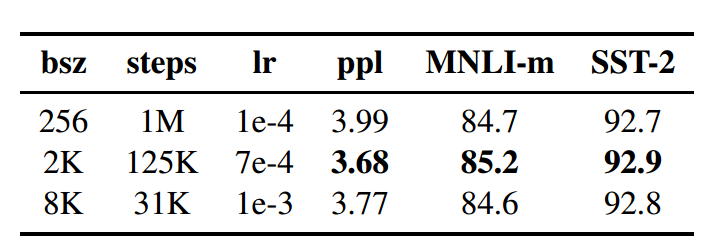
- 将static masked LM 换成dynamic masked LM
原始的MLM首先在线下用create pretraing脚本得到相应的训练数据,RoBERTa是在输入的时候对数据进行动态mask,效果如下。整体看来,效果也比较的一般,提升有限。因为这里其实动态的输入和静态数据其实基本上原理是一样的,所以并没有提升太多的效果。
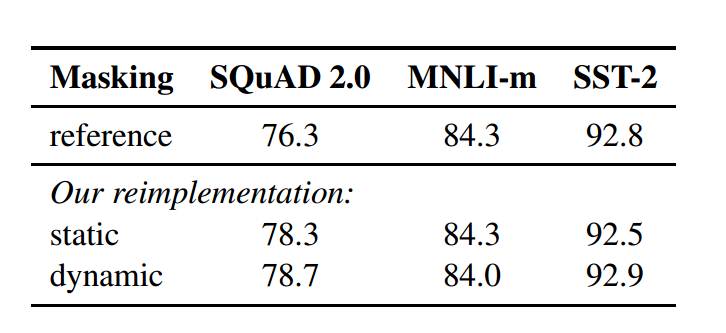
- 去掉NSP
这里的实验结果表明,不使用NSP的效果要优于使用NSP(这里倒还是挺令人意外的)
- 用字节代替字符
原始的bert是用字符作为输入,RoBERTa使用字节,这里会使整体词表的数量增大,但是提升效果一般,就不上图了。
5、ALBERT
ALBERT依旧是Google提出的一种算法[5],其在原始Bert的基础上进行了优化,主要是为了解决Bert的参数量大,训练时间长的问题,其主要有三点创新:1、对输入的embedding进行因式分解。2、层间权重共享。3、损失函数将NSP替换为SOP。
-
输入embedding因式分解
输入层embedding因式分解是这样一种思想,通常的Bert的embedding向量E和隐藏层H是相等的,假设我们的单词个数是V,则我们的embedding的参数量为V * E,以bert_large为例,V=30000,H=E=4096,那么在优化时需要优化的参数量为30000 * 4096 = 1.23亿。在Albert中,将输入的embeding分成两个部分,V * E 和 E * H的向量,其中E远远小于H,这里的E为128,则H为4096,则参数量为30000 * 128 + 128 * 4096 = 436万,原始Bert的参数量是Albert的28倍。
下面依据论文中的描述,从模型角度和实际角度分析这种做法的可行性
从模型角度来看,V * E是词向量的表示,其不涉及词与词之间的相关关系,也就是说每个单词的embedding是相互独立的,而E * H这个向量则含有了词与词之间的相关信息,所以可以将两者分离开。
从实际角度来看,就是我们上文所说的参数量的减少,通过比较,的确可以有效的减少参数的数量。 -
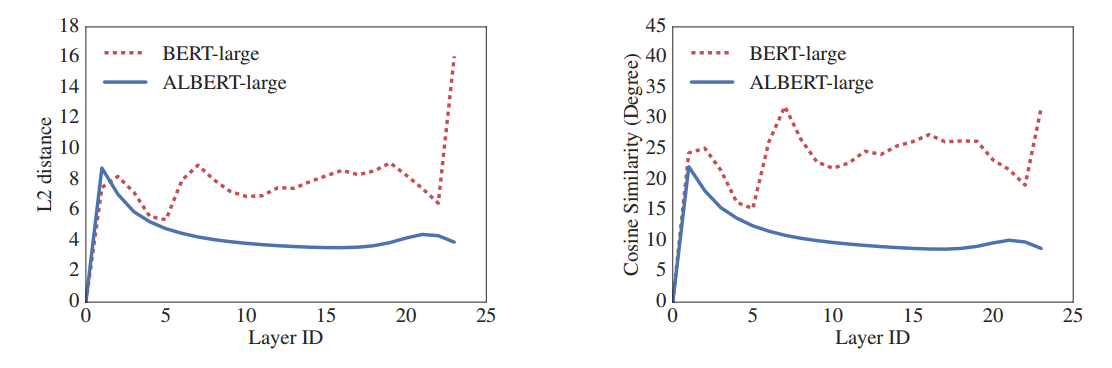
层间权重共享
层间权重共享表示的是每个transformer模块的参数是共享的,并且通过实验的比较,发现层间权重共享可以有效的减少震荡,如下图所示。其中蓝线为Albert的结果,红色虚线为Bert的实验结果。
-
损失函数将NSP替换为SOP
论文中讲述了在单个任务中,NSP可以进行主题预测和连贯性预测,NSP的主题预测其实和MLM的效果有一定的冲突,所以作者用SOP代替NSP,NSP是进行两个句子的构造,正例的构造方法是选择一个句子,并将该句子所在句子的后一句作为第二个句子。负例选择的方法是选择一个句子,并随机选择另一个文档的一个句子。在输出时判断这两个句子是否属于同一个句子,类似于一个二分类。SOP的同样是进行两个句子的构造,正例的构造方法和NSP一样,负例的构造方法是将正例中的两个句子调换个位置。
6、spanBert
spanBert是由华盛顿大学,fb等联合提出的一种改进bert的方法,其中它在三个方面进行的改进:1、将token mask改成span mask。2、损失函数加上SBO损失。3、去掉NSP。
- 将token mask改成span mask
我们知道,原生bert用的是单字进行输入,但是有些情况下,一个单词是最小单元,比如"Denver Broncos"是NFL的一个队伍,所以正常来说将这个单词全部mask会是比较合理的。如下图所示,在这幅图中,将"an American football game"作为整体mask,这也是为啥叫span的思想。
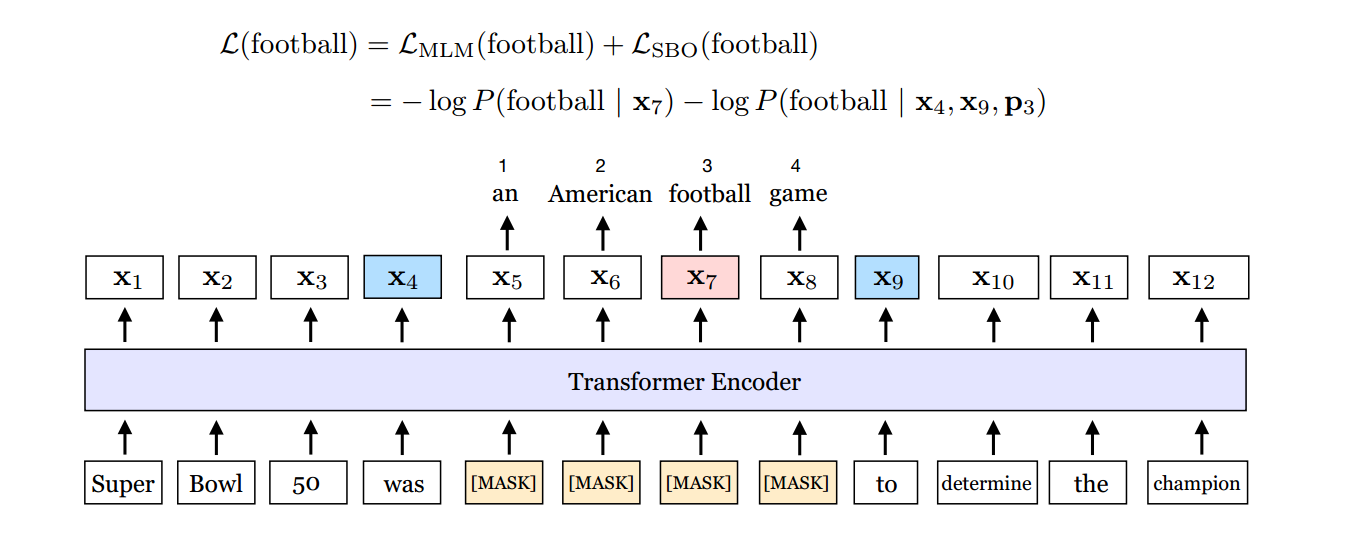
- 损失函数加上SBO损失
还如上图所示,损失函数中除了原生bert中自带的(L_{MLM}(football | x_{7})),还有SBO损失(L_{SBO}(football | x_{4},x_{9},p_{3})),这三个数是怎么得来的呢,假定这个句子为(x_{1},x_{2}.....x_{n})这里n=12,((x_{s},x_{e}))表示被mask的集合,这里s=5,e=8,可以用以下公式得到结果。这里i=7,所以根据公式计算得到(x_{4},x_{9},P_{3})
- 去掉NSP
作者认为NSP会使效果不好,所以去掉了,原文中的两个句子也变成了单个句子。
7、xlnet
xlnet是由卡内基梅隆大学和Google大脑联合提出的一种算法,其沿用了自回归的语言模型,并利用排列语言模型合并了bert的优点,同时集成transformer-xl对于长句子的处理,达到了SOTA的效果。
- AR和AE
AR表示自回归语言模型,自回归语言模型可以理解为单向的语言模型,即通过上文或者是下文预测当前单词,比较有代表性的是GPT,elmo等。AE是自编码语言模型,其通过上下文来预测当前单词,比较有代表性的是bert,利用masked LR,使得上下文单词可以预测当前单词,但是bert的这种方法有一个问题,就是在微调阶段,文本没有办法进行masked,这样会造成一定的性能损失。所以,xlnet就提出了一种排列语言模型,这种模型集成了AR和AE的优点。 - 排列语言模型
一个简单和直观的想法是,我们将输入的token进行随机排列,然后输入到模型中,这样模型不久可以学习到上下文的信息了么,但是这种方法有两个问题:1、选择多少个排列组合进行输入呢,要知道,对于输入个数为T的单词,其排列组合T!,那我们如何取舍?2、对于微调阶段来说,我们也不可能将输入的序列进行多次排列吧,这个如何解决?第一个问题很好解决,干脆随机抽取一部分就行。第二个问题解决起来比较麻烦,那么xlnet用了一种attention mask的方式,解决了这个问题,同时,还无需改变输入序列的顺序。
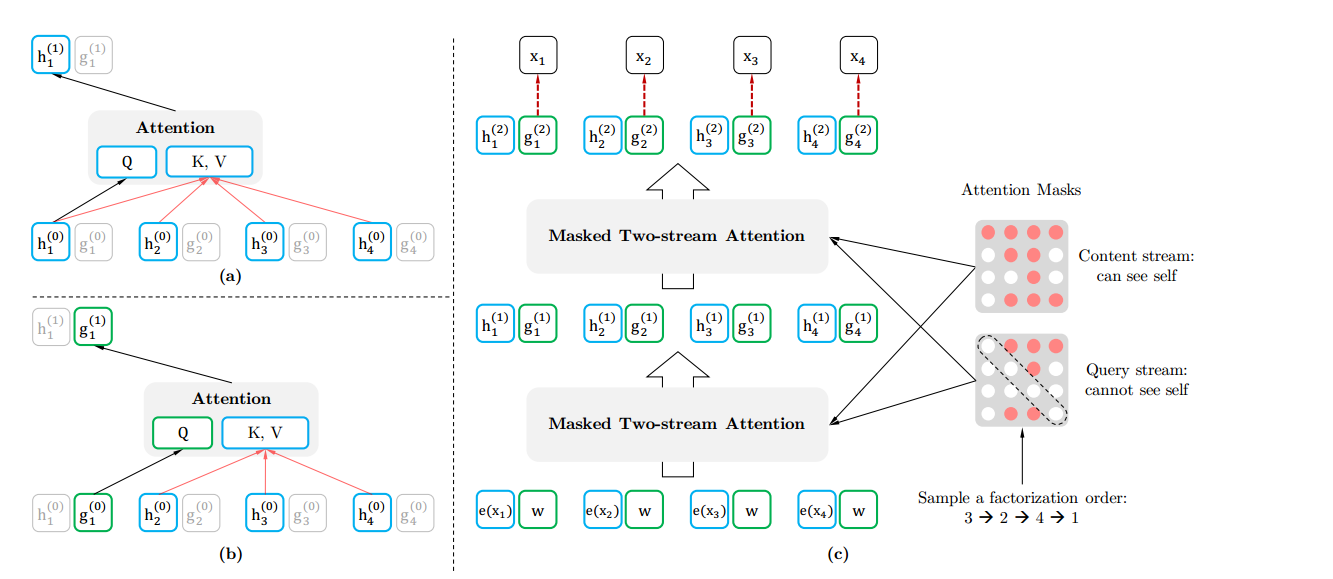
上图表示用两种不同的输入流,分别是query stream和content stream,其中有两种不同的mask方式,既然我们无法改变输入的顺序,那么我们可以通过相应的mask方式来达到相应的效果,对于上图来说,原始的输入是x1,x2,x3,x4,但是我们又想达到x3,x2,x4,x1的效果,怎么办呢?对于序列x3,x2,x4,x1来说,x3看不见任何东西,x2可以看到x3,x4可以看到x3,x2,x1可以看到x3,x2,x4,那么写成mask矩阵的形式就是如右上角的那个图,我们可以对输入的矩阵做一个处理,让相应的单词看不见其他的单词的方式,就可以达到这种效果。 - 集成Transformer-XL
对于过长序列,如果分段来进行处理,往往会遗漏信息,且效果会下降,那么xlnet借鉴了Transformer-XL的思想,设置一个保留上一个片段的信息,在训练时进行更新。
[2]Alec Radford(2018)Improving Language Understanding by Generative Pre-Training.
[3]Jacob Devlin(2019)BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding.
[4]Yinhan Liu(2019)RoBERTa: A Robustly Optimized BERT Pretraining Approach.
[5]Zhenzhong Lan(2020)ALBERT: A LITE BERT FOR SELF-SUPERVISED LEARNING OF LANGUAGE REPRESENTATIONS.
[6]Mandar Joshi(2020)panBERT: Improving Pre-training by Representing and Predicting Spans.
[7]Zhilin Yang(2019).XLNet: Generalized Autoregressive Pretraining for Language Understanding.