在此仓库https://github.com/jym66/Dlink_Parse 上增加了解析url代码
首先下载好仓库代码,修改xigua.py
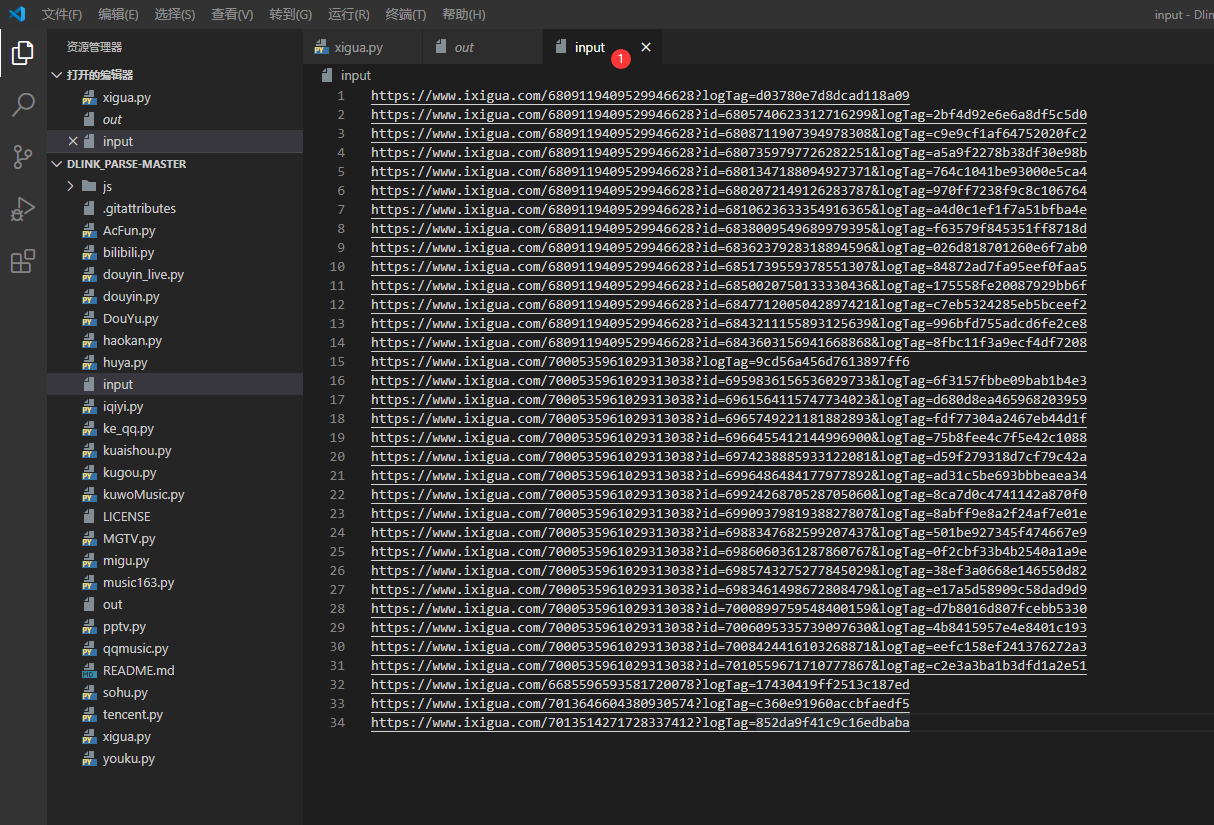
把收集到的url放到input文件中
import requests
import execjs
import re
import jsonpath
import json
import base64
class xigua:
def __init__(self, url):
self.url = url
if "wid_try=1" not in self.url:
self.url = self.url + "&wid_try=1"
self.headers = {
"referer": self.url,
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36",
}
self.nonce = self.getNonce()
def getNonce(self):
res = requests.get(self.url, headers=self.headers)
return res.cookies.get("__ac_nonce")
def getSign(self):
jscode = execjs.compile(open("./js/xigua.js").read())
ctx = jscode.call("getSign", self.nonce, self.url)
return f"__ac_nonce={self.nonce};__ac_signature={ctx};__ac_referer={self.url}"
def start(self):
self.headers.update({"cookie": self.getSign()})
html = requests.get(self.url, headers=self.headers)
res = re.findall("window._SSR_HYDRATED_DATA=(.*?)</script>", html.text)[0].replace("undefined", 'null')
url = jsonpath.jsonpath(json.loads(res), "$..video_2.main_url")
url = str(base64.b64decode(url[0]), "utf-8")
print(url)
return url
if __name__ == '__main__':
with open("input") as f, open("out", mode="w") as f_out:
for line in f:
if not line:
break
url = xigua(line.rstrip()).start()
#也可用requests下载
f_out.write(url+"
")
然后把out里的地址丢到电驴里下载,然后把文件名改成mp4后缀即可。
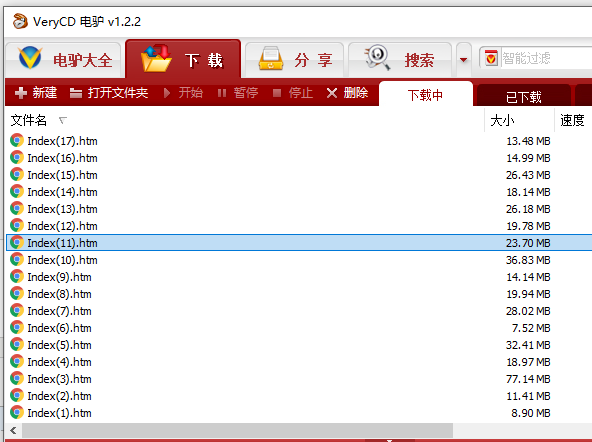
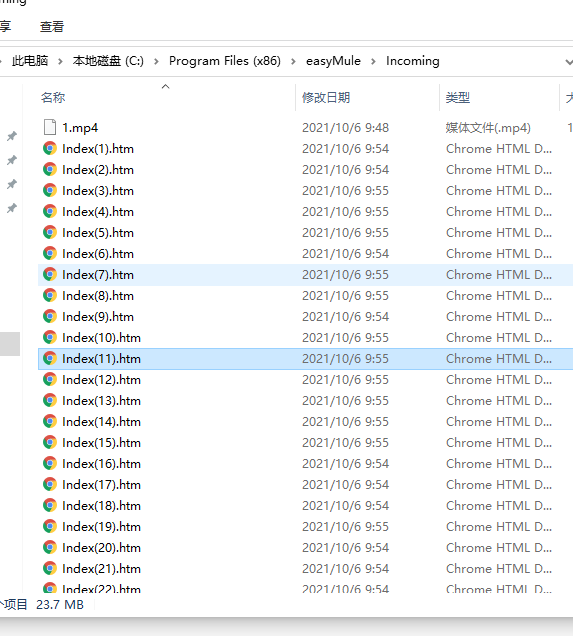
文件管理器的地址栏cmd回车,输入下面的命令批量改后缀
ren *.htm *.mp4