1、架构
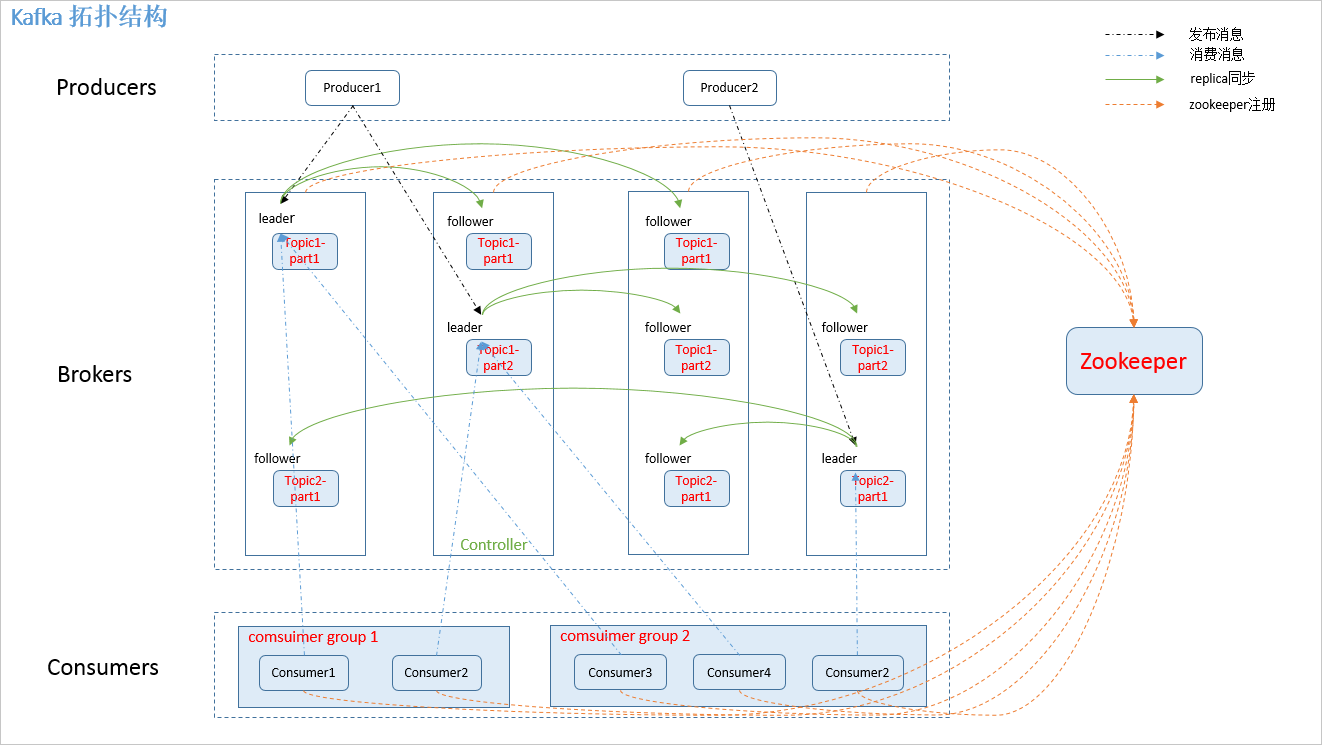
1.producer: 消息生产者,发布消息到 kafka 集群的终端或服务。 2.broker: kafka 集群中包含的服务器。 3.topic: 每条发布到 kafka 集群的消息属于的类别,即 kafka 是面向 topic 的。 4.partition: partition 是物理上的概念,每个 topic 包含一个或多个 partition。kafka 分配的单位是 partition。 5.consumer: 从 kafka 集群中消费消息的终端或服务。 6.Consumer group: high-level consumer API 中,每个 consumer 都属于一个 consumer group,每条消息只能被 consumer group 中的一个 Consumer 消费,但可以被多个 consumer group 消费。 7.replica: partition 的副本,保障 partition 的高可用。 8.leader: replica 中的一个角色, producer 和 consumer 只跟 leader 交互。 9.follower: replica 中的一个角色,从 leader 中复制数据。 10.controller: kafka 集群中的其中一个服务器,用来进行 leader election 以及 各种 failover。 12.zookeeper: kafka 通过 zookeeper 来存储集群的 meta 信息。
2、producer 发布消息
写入方式:
producer 采用 push 模式将消息发布到 broker,每条消息都被 append 到 patition 中,属于顺序写磁盘(顺序写磁盘效率比随机写内存要高,保障 kafka 吞吐率)。
消息路由:
producer 发送消息到 broker 时,会根据分区算法选择将其存储到哪一个 partition。其路由机制为:
1. 指定了 patition,则直接使用; 2. 未指定 patition 但指定 key,通过对 key 的 value 进行hash 选出一个 patition 3. patition 和 key 都未指定,使用轮询选出一个 patition。
3、broker 保存消息
存储方式:
物理上把 topic 分成一个或多个 patition(对应 server.properties 中的 num.partitions=3 配置),每个 patition 物理上对应一个文件夹(该文件夹存储该 patition 的所有消息和索引文件)
存储策略:
无论消息是否被消费,kafka 都会保留所有消息。有两种策略可以删除旧数据:
1. 基于时间:log.retention.hours=168 2. 基于大小:log.retention.bytes=1073741824 4、consumer 消费消息
4、consumer消费消息
kafka 提供了两套 consumer API:
1. The high-level Consumer API 2. The SimpleConsumer API
high-level consumer API 提供了 consumer group 的语义,一个消息只能被 group 内的一个 consumer 所消费,且 consumer 消费消息时不关注 offset,最后一个 offset 由 zookeeper 保存。
如果你想要对 patition 有更多的控制权,那就应该使用 SimpleConsumer API,比如:
1. 多次读取一个消息 2. 只消费一个 patition 中的部分消息 3. 使用事务来保证一个消息仅被消费一次
但是使用此 API 时,partition、offset、broker、leader 等对你不再透明,需要自己去管理。你需要做大量的额外工作:
1. 必须在应用程序中跟踪 offset,从而确定下一条应该消费哪条消息 2. 应用程序需要通过程序获知每个 Partition 的 leader 是谁 3. 需要处理 leader 的变更
使用 SimpleConsumer API 的一般流程如下:
1. 查找到一个“活着”的 broker,并且找出每个 partition 的 leader 2. 找出每个 partition 的 follower 3. 定义好请求,该请求应该能描述应用程序需要哪些数据 4. fetch 数据 5. 识别 leader 的变化,并对之作出必要的响应
参考:https://www.cnblogs.com/xifenglou/p/7251112.html
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务。它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。它的作用相当于对集群的管理,消费者和生产者都要到zookeeper进行服务的发布和注册。