隐语义模型是通过隐含特征,联系用户和物品,基于用户的特征对物品进行自动聚类,然后在用户感兴趣的类中选择物品推荐给用户。
对于推荐系统,常用的算法:
USER-CF:给用户推荐和他兴趣相似的用户喜欢的物品
ITEM-CF:给用户推荐他们感兴趣物品的相似物品
LFM:得到用户感兴趣的分类,从该分类中挑选物品推荐给用户
对于LFM,要做的工作有:
1.对物品进行分类,这里是模糊分类,也就是得出每个物品在每个类中的权重,并不是说一个物品就是属于一个类
2.确定用户感兴趣的类,这里要计算用户对所有类的兴趣度
3.从类中挑选物品给用户推荐,根据1,2结果相乘,得出用户对所有物品的兴趣度,进行排序,得出结果
公式:
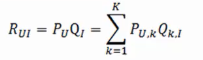
其中R是用户u对物品i的兴趣度组成的矩阵
P是用户u对第k个类的兴趣度组成的矩阵
Q是物品i在第k个类中的权重
一图胜千言:
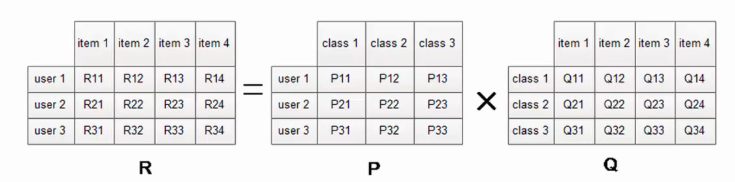
可以看出,协同过滤是基于统计的,不需要有学习过程,可以实时得出。而隐语义模型是基于建模的,根据训练集,计算出上图中的全部参数,有训练过程,无法实时给出结果。
损失函数:
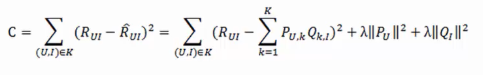
其中后两项为L2正则化项,防止过拟合
求解可以用梯度下降:
梯度:
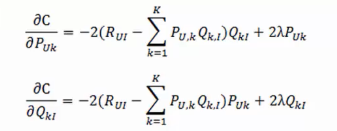
迭代求解:
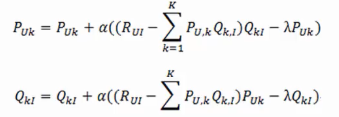
隐语义模型中负样本的选择
1)对每个用户,要保证正负样本的数目相近
2)对每个用户采样负样本时,要选取那些很热门,而用户却没有行为的物品。(更代表用户对该物品不感兴
趣)
参数:
1.隐特征个数,也就是类个数f
2.学习率∂
3.正则化参数λ
相对CF,LFM的空间复杂度更低