一:去除重复URL
scrapy默认使用 scrapy.dupefilter.RFPDupeFilter 进行去重,相关配置有:
DUPEFILTER_CLASS = 'scrapy.dupefilter.RFPDupeFilter'
DUPEFILTER_DEBUG = False
JOBDIR = "保存范文记录的日志路径,如:/root/" # 最终路径为 /root/requests.seen
下面自定义ULR去重操作:(将原来在spider中的操作分解开来)
duplication.py
class RepeatDupeFilter(object):
def __init__(self):
self.visited_url = set()
@classmethod
def from_settings(cls, settings):
"""
初始化时,调用,
:param settings:
:return:
"""
return cls()
def request_seen(self, request):
"""
检测当前请求是否已经被访问过
:param request:
:return: True表示已经访问过;False表示未访问过
"""
print('.......')
if request.url in self.visited_url:
return True
self.visited_url.add(request.url)
return False
def open(self):
"""
开始爬去请求时,调用
:return:
"""
print('open')
def close(self, reason):
"""
结束爬虫爬取时,调用
:param reason:
:return:
"""
print('close')
def log(self, request, spider):
"""
记录日志
:param request:
:param spider:
:return:
"""
print('repeat', request.url)
settings.py
DUPEFILTER_CLASS = "scrapyPro.duplication.RepeatDupeFilter"
执行时机:会在引擎启动后开始执行,当对第一个url进行获取时,就会去调用该去重机制
二:pipeline补充
pipeline中不止可以解析数据,还可以进行其他扩展
pipelines.py
from scrapy.exceptions import DropItem
class ScrapyproPipeline(object):
def __init__(self,conn_str):
self.conn_str = conn_str
self.conn = None #数据库连接
print("connect db")
@classmethod
def from_crawler(cls,crawler):
'''
初始化时候,用于创建pipeline对象,读取配置文件
:param crawler: crawler.settings是在初始化时候就将配置文件放入crawler中了
:return:
'''
conn_str = crawler.settings.get("DB") #获取数据库信息 #模拟数据库记录操作
print("get db info")
return cls(conn_str) #返回该对象,会去执行init方法
def open_spider(self,spider):
'''
每当爬虫开始执行的时候,调用
:param spider:
:return:
'''
# self.conn.open()
print("chouti spider start")
def process_item(self, item, spider):
'''
每当数据需要持久化时,就会被调用,spider是爬虫对象
:param item:
:param spider:
:return:
'''
if spider.name != "xiaohua": #若是爬虫不符合,不进行持久化处理
return item
tpl = "%s
%s
"%(item['href'],item['title'])
with open("news.josn",'a') as fp:
fp.write(tpl)
#交给下一个pipeline处理
return item #和settings文件有关,当settings文件设置多个pipeline时,会依次去执行,若是不想执行可以丢弃item,不继续
#抛出异常DropItem表示终止,丢弃item,不交给下一个处理
# return DropItem()
def close_spider(self,spider):
'''爬虫关闭时执行'''
print("chouti spilder close")
# self.conn.close()
settings.py相关
ITEM_PIPELINES = { #每一个spider都会经过下面所有的pipeline,我们可以根据参数spider对象对其进行处理,也可以设置是否返回item,来设置是否继续向下执行
'scrapyPro.pipelines.ScrapyproPipeline': 300,
'scrapyPro.pipelines.XiaohuaPipeline': 100, #后面小的优先
}
执行时机:会在上面的url去重后,获取完数据后,对数据进行持久化操作

补充:crawler.settings.get("DB")
我们可以在from_crawler的参数crawler中获取配置文件信息
使用crawler.settings.get("DB")
注意:我们在配置文件中键值设置中键必须是大写的
三:cookies获取,CookieJar
获取响应response的响应cookies
from scrapy.http.cookies import CookieJar
def parse(self, response):
#获取cookies
cookie_obj = CookieJar()
cookie_obj.extract_cookies(response,response.request) #从响应体中提取出cookies
self.cookie_dict = cookie_obj._cookies #注意cookies保存在cookiejar对象中的_cookies中
cookies实例:登录抽屉,实现点赞
import scrapy,hashlib,json
from scrapy.selector import Selector,HtmlXPathSelector
from scrapy.http import Request
from scrapy.http.cookies import CookieJar
class ChoutiSpider(scrapy.Spider):
name = 'chouti'
allowed_domains = ['chouti.com']
start_urls = ['https://dig.chouti.com/']
cookie_dict = None
def parse(self, response):
#到首页,获取cookie
cookie_obj = CookieJar()
cookie_obj.extract_cookies(response,response.request)
self.cookie_dict = cookie_obj._cookies
yield Request(url="https://dig.chouti.com/login",
cookies=self.cookie_dict,
method="post",
headers={
'user-agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36',
'content-type':'application/x-www-form-urlencoded; charset=UTF-8'
},
body= "phone=账号&password=密码&oneMonth=1",
callback=self.check_login
)
def check_login(self,response):
# print(response.text) #{"result":{"code":"9999", "message":"", "data":{"complateReg":"0","destJid":"cdu_52941024478"}}}
ret = json.loads(response.text,encoding="utf-8")
if ret['result'].get("code") == "9999":
yield Request(url="https://dig.chouti.com/",callback=self.favor)
def favor(self,response):
news_list = Selector(response=response).xpath("//div[@class='part2']/@share-linkid").extract()
for news_id in news_list:
new_url = "https://dig.chouti.com/link/vote?linksId=%s"%news_id
yield Request(url=new_url,
method="post",
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.90 Safari/537.36',
'content-type': 'application/x-www-form-urlencoded; charset=UTF-8'
},
cookies=self.cookie_dict, #正好凑巧,抽屉登录后的操作需要使用登录前的一个cookie值,我们没有在check_login中更新cookies_dict,所以纯属巧合
callback=self.show
)
page_list = Selector(response=response).xpath("//a[@class='ct_pagepa']/@href").extract()
for page_url in page_list:
new_page_url = "https://dig.chouti.com%s"%page_url
yield Request(
url=new_page_url,
method="get",
callback=self.favor
)
def show(self,response):
print(response.text)
注意:当我们无法进入show回调时,可能在settings中的深度设置太低
四:scrapy框架扩展,实现信号回调
自定义扩展时,利用信号在指定位置注册制定操作
在settings.py文件中设置扩展
EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None, #None代表不执行
"scrapyPro.extensions.MyExtend":100
}
扩展文件extensions.py
from scrapy import signals
class MyExtend:
def __init__(self, crawler):
self.crawler = crawler
#在指定信号上注册操作
crawler.signals.connect(self.start,signals.engine_started) #在引擎前端时调用我们定义的方法
@classmethod
def from_crawler(cls, crawler):
return cls(crawler)
def start(self):
print("extensions start")
所有信号
engine_started = object()
engine_stopped = object()
spider_opened = object()
spider_idle = object()
spider_closed = object()
spider_error = object()
request_scheduled = object()
request_dropped = object()
response_received = object()
response_downloaded = object()
item_scraped = object()
item_dropped = object()
# for backwards compatibility
stats_spider_opened = spider_opened
stats_spider_closing = spider_closed
stats_spider_closed = spider_closed
item_passed = item_scraped
request_received = request_scheduled
执行时机:会在信号触发时,去执行相关方法
五:配置文件介绍
# 1. 爬虫名称
BOT_NAME = 'step8_king'
# 2. 爬虫应用路径
SPIDER_MODULES = ['step8_king.spiders']
NEWSPIDER_MODULE = 'step8_king.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# 3. 客户端 user-agent请求头 可伪造
# USER_AGENT = 'step8_king (+http://www.yourdomain.com)'
# Obey robots.txt rules
# 4. 禁止爬虫原来配置(默认true,符合爬虫规则,人家不让就不去爬取)
# ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# 5. 并发请求数
# CONCURRENT_REQUESTS = 4
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
# 6. 延迟下载秒数
# DOWNLOAD_DELAY = 2
# The download delay setting will honor only one of:
# 7. 单域名访问并发数,并且延迟下次秒数也应用在每个域名
# CONCURRENT_REQUESTS_PER_DOMAIN = 2
# 单IP访问并发数,如果有值则忽略:CONCURRENT_REQUESTS_PER_DOMAIN,并且延迟下次秒数也应用在每个IP
# CONCURRENT_REQUESTS_PER_IP = 3
# Disable cookies (enabled by default)
# 8. 是否支持cookie,cookiejar进行操作cookie
# COOKIES_ENABLED = True
# COOKIES_DEBUG = True
# Disable Telnet Console (enabled by default)
# 9. Telnet用于查看当前爬虫的信息,操作爬虫等...
# 使用telnet ip port ,然后通过命令操作
# TELNETCONSOLE_ENABLED = True
# TELNETCONSOLE_HOST = '127.0.0.1'
# TELNETCONSOLE_PORT = [6023,]
# 10. 默认请求头
# Override the default request headers:
# DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
# }
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
# 11. 定义pipeline处理请求
# ITEM_PIPELINES = {
# 'step8_king.pipelines.JsonPipeline': 700,
# 'step8_king.pipelines.FilePipeline': 500,
# }
# 12. 自定义扩展,基于信号进行调用
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# # 'step8_king.extensions.MyExtension': 500,
# }
# 13. 爬虫允许的最大深度,可以通过meta查看当前深度;0表示无深度
# DEPTH_LIMIT = 3
# 14. 爬取时,0表示深度优先Lifo(默认);1表示广度优先FiFo
# 后进先出,深度优先
# DEPTH_PRIORITY = 0
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleLifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.LifoMemoryQueue'
# 先进先出,广度优先
# DEPTH_PRIORITY = 1
# SCHEDULER_DISK_QUEUE = 'scrapy.squeue.PickleFifoDiskQueue'
# SCHEDULER_MEMORY_QUEUE = 'scrapy.squeue.FifoMemoryQueue'
# 15. 调度器队列
# SCHEDULER = 'scrapy.core.scheduler.Scheduler'
# from scrapy.core.scheduler import Scheduler
# 16. 访问URL去重
# DUPEFILTER_CLASS = 'step8_king.duplication.RepeatUrl'
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
"""
17. 自动限速算法
from scrapy.contrib.throttle import AutoThrottle
自动限速设置
1. 获取最小延迟 DOWNLOAD_DELAY
2. 获取最大延迟 AUTOTHROTTLE_MAX_DELAY
3. 设置初始下载延迟 AUTOTHROTTLE_START_DELAY
4. 当请求下载完成后,获取其"连接"时间 latency,即:请求连接到接受到响应头之间的时间
5. 用于计算的... AUTOTHROTTLE_TARGET_CONCURRENCY
target_delay = latency / self.target_concurrency
new_delay = (slot.delay + target_delay) / 2.0 # 表示上一次的延迟时间
new_delay = max(target_delay, new_delay)
new_delay = min(max(self.mindelay, new_delay), self.maxdelay)
slot.delay = new_delay
"""
# 开始自动限速
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# 初始下载延迟
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# 最大下载延迟
# AUTOTHROTTLE_MAX_DELAY = 10
# The average number of requests Scrapy should be sending in parallel to each remote server
# 平均每秒并发数
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# 是否显示
# AUTOTHROTTLE_DEBUG = True
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
"""
18. 启用缓存
目的用于将已经发送的请求或相应缓存下来,以便以后使用
from scrapy.downloadermiddlewares.httpcache import HttpCacheMiddleware
from scrapy.extensions.httpcache import DummyPolicy
from scrapy.extensions.httpcache import FilesystemCacheStorage
"""
# 是否启用缓存策略
# HTTPCACHE_ENABLED = True
# 缓存策略:所有请求均缓存,下次在请求直接访问原来的缓存即可
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.DummyPolicy"
# 缓存策略:根据Http响应头:Cache-Control、Last-Modified 等进行缓存的策略
# HTTPCACHE_POLICY = "scrapy.extensions.httpcache.RFC2616Policy"
# 缓存超时时间
# HTTPCACHE_EXPIRATION_SECS = 0
# 缓存保存路径
# HTTPCACHE_DIR = 'httpcache'
# 缓存忽略的Http状态码
# HTTPCACHE_IGNORE_HTTP_CODES = []
# 缓存存储的插件
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
"""
19. 代理,需要在环境变量中设置
from scrapy.contrib.downloadermiddleware.httpproxy import HttpProxyMiddleware
方式一:使用默认
os.environ
{
http_proxy:http://root:woshiniba@192.168.11.11:9999/
https_proxy:http://192.168.11.11:9999/
}
方式二:使用自定义下载中间件(推荐:灵活)
def to_bytes(text, encoding=None, errors='strict'):
if isinstance(text, bytes):
return text
if not isinstance(text, six.string_types):
raise TypeError('to_bytes must receive a unicode, str or bytes '
'object, got %s' % type(text).__name__)
if encoding is None:
encoding = 'utf-8'
return text.encode(encoding, errors)
class ProxyMiddleware(object):
def process_request(self, request, spider):
PROXIES = [
{'ip_port': '111.11.228.75:80', 'user_pass': ''},
{'ip_port': '120.198.243.22:80', 'user_pass': ''},
{'ip_port': '111.8.60.9:8123', 'user_pass': ''},
{'ip_port': '101.71.27.120:80', 'user_pass': ''},
{'ip_port': '122.96.59.104:80', 'user_pass': ''},
{'ip_port': '122.224.249.122:8088', 'user_pass': ''},
]
proxy = random.choice(PROXIES)
if proxy['user_pass'] is not None:
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
encoded_user_pass = base64.encodestring(to_bytes(proxy['user_pass']))
request.headers['Proxy-Authorization'] = to_bytes('Basic ' + encoded_user_pass)
print "**************ProxyMiddleware have pass************" + proxy['ip_port']
else:
print "**************ProxyMiddleware no pass************" + proxy['ip_port']
request.meta['proxy'] = to_bytes("http://%s" % proxy['ip_port'])
DOWNLOADER_MIDDLEWARES = {
'step8_king.middlewares.ProxyMiddleware': 500,
}
"""
"""
20. Https访问
Https访问时有两种情况:
1. 要爬取网站使用的可信任证书(默认支持)
DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory"
DOWNLOADER_CLIENTCONTEXTFACTORY = "scrapy.core.downloader.contextfactory.ScrapyClientContextFactory"
2. 要爬取网站使用的自定义证书
DOWNLOADER_HTTPCLIENTFACTORY = "scrapy.core.downloader.webclient.ScrapyHTTPClientFactory"
DOWNLOADER_CLIENTCONTEXTFACTORY = "step8_king.https.MySSLFactory"
# https.py
from scrapy.core.downloader.contextfactory import ScrapyClientContextFactory
from twisted.internet.ssl import (optionsForClientTLS, CertificateOptions, PrivateCertificate)
class MySSLFactory(ScrapyClientContextFactory):
def getCertificateOptions(self):
from OpenSSL import crypto
v1 = crypto.load_privatekey(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.key.unsecure', mode='r').read())
v2 = crypto.load_certificate(crypto.FILETYPE_PEM, open('/Users/wupeiqi/client.pem', mode='r').read())
return CertificateOptions(
privateKey=v1, # pKey对象
certificate=v2, # X509对象
verify=False,
method=getattr(self, 'method', getattr(self, '_ssl_method', None))
)
其他:
相关类
scrapy.core.downloader.handlers.http.HttpDownloadHandler
scrapy.core.downloader.webclient.ScrapyHTTPClientFactory
scrapy.core.downloader.contextfactory.ScrapyClientContextFactory
相关配置
DOWNLOADER_HTTPCLIENTFACTORY
DOWNLOADER_CLIENTCONTEXTFACTORY
"""
"""
21. 爬虫中间件
class SpiderMiddleware(object):
def process_spider_input(self,response, spider):
'''
下载完成,执行,然后交给parse处理(在spider处理前)
:param response:
:param spider:
:return:
'''
pass
def process_spider_output(self,response, result, spider):
'''
spider处理完成,返回时调用(在spider处理后)
:param response:
:param result:
:param spider:
:return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)
'''
return result
def process_spider_exception(self,response, exception, spider):
'''
异常调用
:param response:
:param exception:
:param spider:
:return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline
'''
return None
def process_start_requests(self,start_requests, spider):
'''
爬虫启动时调用,第一次使用时,针对start_url
:param start_requests:
:param spider:
:return: 包含 Request 对象的可迭代对象
'''
return start_requests
内置爬虫中间件:
'scrapy.contrib.spidermiddleware.httperror.HttpErrorMiddleware': 50,
'scrapy.contrib.spidermiddleware.offsite.OffsiteMiddleware': 500,
'scrapy.contrib.spidermiddleware.referer.RefererMiddleware': 700,
'scrapy.contrib.spidermiddleware.urllength.UrlLengthMiddleware': 800,
'scrapy.contrib.spidermiddleware.depth.DepthMiddleware': 900,
"""
# from scrapy.contrib.spidermiddleware.referer import RefererMiddleware
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
# 'step8_king.middlewares.SpiderMiddleware': 543,
}
"""
22. 下载中间件
class DownMiddleware1(object):
def process_request(self, request, spider):
'''
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
'''
pass
def process_response(self, request, response, spider):
'''
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
'''
print('response1')
return response
def process_exception(self, request, exception, spider):
'''
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
'''
return None
默认下载中间件
{
'scrapy.contrib.downloadermiddleware.robotstxt.RobotsTxtMiddleware': 100,
'scrapy.contrib.downloadermiddleware.httpauth.HttpAuthMiddleware': 300,
'scrapy.contrib.downloadermiddleware.downloadtimeout.DownloadTimeoutMiddleware': 350,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware': 400,
'scrapy.contrib.downloadermiddleware.retry.RetryMiddleware': 500,
'scrapy.contrib.downloadermiddleware.defaultheaders.DefaultHeadersMiddleware': 550,
'scrapy.contrib.downloadermiddleware.redirect.MetaRefreshMiddleware': 580,
'scrapy.contrib.downloadermiddleware.httpcompression.HttpCompressionMiddleware': 590,
'scrapy.contrib.downloadermiddleware.redirect.RedirectMiddleware': 600,
'scrapy.contrib.downloadermiddleware.cookies.CookiesMiddleware': 700,
'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 750,
'scrapy.contrib.downloadermiddleware.chunked.ChunkedTransferMiddleware': 830,
'scrapy.contrib.downloadermiddleware.stats.DownloaderStats': 850,
'scrapy.contrib.downloadermiddleware.httpcache.HttpCacheMiddleware': 900,
}
"""
# from scrapy.contrib.downloadermiddleware.httpauth import HttpAuthMiddleware
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# DOWNLOADER_MIDDLEWARES = {
# 'step8_king.middlewares.DownMiddleware1': 100,
# 'step8_king.middlewares.DownMiddleware2': 500,
# }
六:下载中间件和爬虫中间件
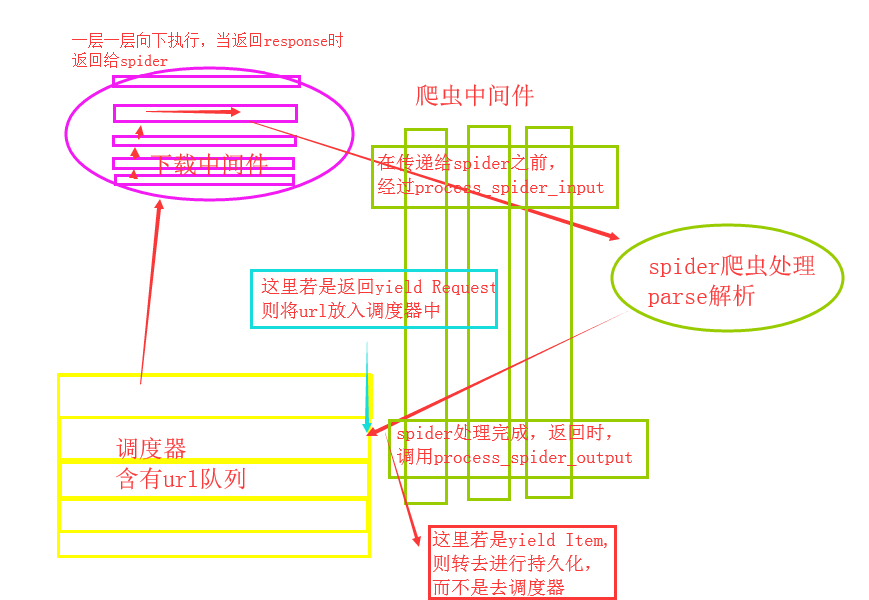


class SpiderMiddleware(object):
def process_spider_input(self,response, spider):
"""
下载完成,执行,然后交给parse处理
:param response:
:param spider:
:return:
"""
pass
def process_spider_output(self,response, result, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return: 必须返回包含 Request 或 Item 对象的可迭代对象(iterable)
"""
return result
def process_spider_exception(self,response, exception, spider):
"""
异常调用
:param response:
:param exception:
:param spider:
:return: None,继续交给后续中间件处理异常;含 Response 或 Item 的可迭代对象(iterable),交给调度器或pipeline
"""
return None
def process_start_requests(self,start_requests, spider):
"""
爬虫启动时调用
:param start_requests:
:param spider:
:return: 包含 Request 对象的可迭代对象
"""
return start_requests
爬虫中间件需要在settings中配置SPIDER_MIDDLEWARES
class DownMiddleware1(object):
def process_request(self, request, spider):
"""
请求需要被下载时,经过所有下载器中间件的process_request调用
:param request:
:param spider:
:return:
None,继续后续中间件去下载;
Response对象,停止process_request的执行,开始执行process_response
Request对象,停止中间件的执行,将Request重新调度器
raise IgnoreRequest异常,停止process_request的执行,开始执行process_exception
"""
pass
def process_response(self, request, response, spider):
"""
spider处理完成,返回时调用
:param response:
:param result:
:param spider:
:return:
Response 对象:转交给其他中间件process_response
Request 对象:停止中间件,request会被重新调度下载
raise IgnoreRequest 异常:调用Request.errback
"""
print('response1')
return response
def process_exception(self, request, exception, spider):
"""
当下载处理器(download handler)或 process_request() (下载中间件)抛出异常
:param response:
:param exception:
:param spider:
:return:
None:继续交给后续中间件处理异常;
Response对象:停止后续process_exception方法
Request对象:停止中间件,request将会被重新调用下载
"""
return None
下载中间件需要在settings中配置DOWNLOADER_MIDDLEWARES
七:自定义命令
1.在spiders同级创建任意目录,如:commands
2.在其中创建 crawlall.py 文件 (此处文件名就是自定义的命令)
from scrapy.commands import ScrapyCommand
from scrapy.utils.project import get_project_settings
class Command(ScrapyCommand):
requires_project = True
def syntax(self):
return '[options]'
def short_desc(self):
return 'Runs all of the spiders'
def run(self, args, opts):
spider_list = self.crawler_process.spiders.list()
for name in spider_list:
self.crawler_process.crawl(name, **opts.__dict__)
self.crawler_process.start()
3.在settings.py 中添加配置 COMMANDS_MODULE = '项目名称.目录名称'
4.在项目目录执行命令:scrapy crawlall
注意:自定制命令是我们研究爬虫源码的入口