一:累加器简介
(一)累加器用途
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,
如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,
即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,
但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
累加器是用于跨执行器聚合信息的变量。例如,这些信息可以与数据或API诊断相关,比如有多少记录被破坏了,或者某个特定的库API被调用了多少次。
(二)累加器概念
在Spark中如果想在Task计算的时候统计某些事件的数量,使用filter/reduce也可以,但是使用累加器是一种更方便的方式,累加器一个比较经典的应用场景是用来在Spark Streaming应用中记录某些事件的数量。使用累加器时需要注意只有Driver能够取到累加器的值,Task端进行的是累加操作。(可以认为在task端使用写锁,一次只能一个task写入,不会出现竞争导致数据出错)
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能,只能累加,不能减少。累加器只能在Driver端构建,并只能从Driver端读取结果,在Task端只能进行累加。
注意:在每个执行器上更新累加器,都会将累加数据转发回Driver驱动程序。(所以为了避免网络传输次数过大,可以将多次更新的值放入本地变量,到达指定数值后,更新给累加器,减少网络传输次数)
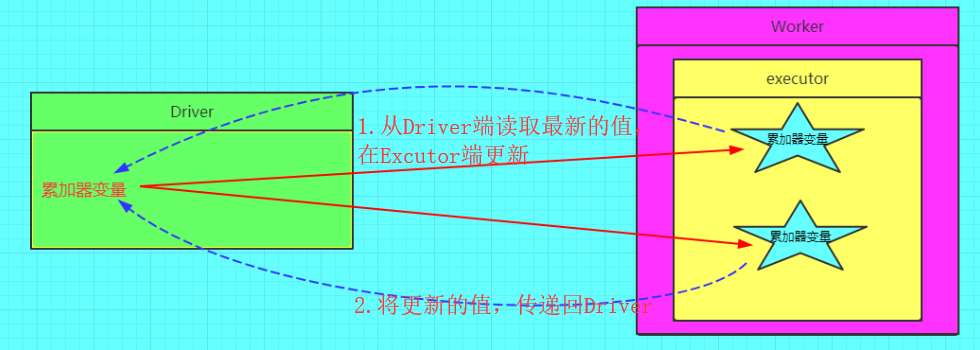
(三)累加器概念图
二:累加器实现原理
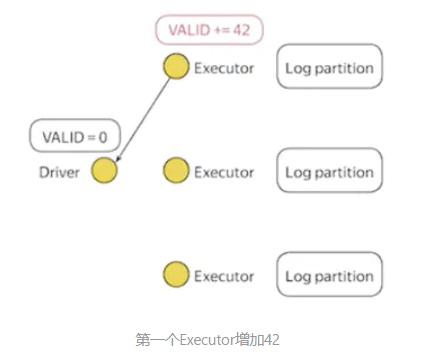
每个Executor各自可以在累加器变量中增加delta值,Executor把delta值发送给Driver,Driver将所有的delta值加在一起。
1.Executor1增加42,Driver接收到之后,VALID的值为42。
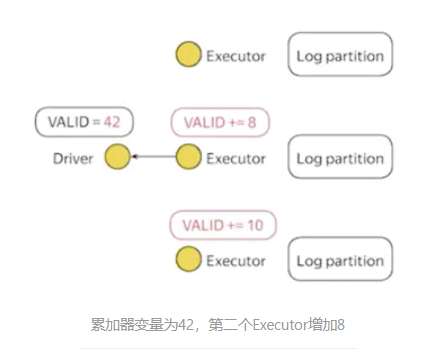
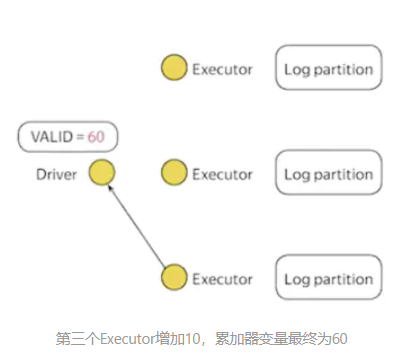
2.Executor2增加8,VALID的值为50。Executor3增加10,VALID的值为60。在Driver中读取该变量时,得到的结果为60。
三:累加器案例讲解
(一)前提
处理目录下的日志文件,某些日志被破坏,导致部分行数据丢失,为空白。我们要统计出来一共有多少行数据被破坏。
(二)不使用累加器的代码(分析错误)---重点
读取some log file目录下的所有日志,甚至分区为4.
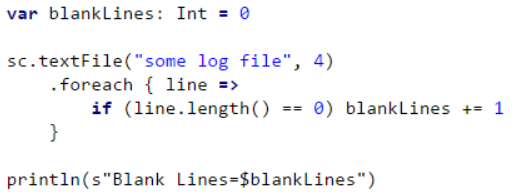
上述代码的问题是,当Driver驱动程序打印变量blankLines时,它的值将是零。
这是因为,当Spark将这段代码发送给每个Task执行程序时,这些变量将成为该执行程序的局部变量,并且其更新后的值不会被转发回驱动程序。
为了避免这个问题,我们需要在累加器中设置变量:空白行,这样每个执行器中对这个变量的所有更新都将被转发回驱动程序。
(三)改进用累加器
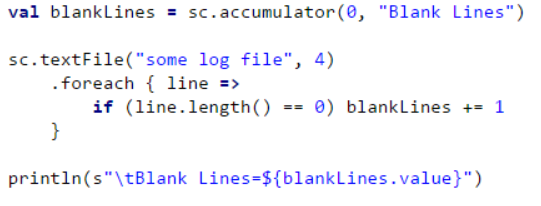
这保证了在每个Task执行器上更新累加器空白行,并将更新转发回驱动程序。
熟悉Hadoop Map-Reduce的人会注意到Spark的累加器类似于Hadoop的Map-Reduce计数器。
三:累加器注意事项
(一) 累加器在Driver端定义赋初始值,累加器只能在Driver端读取最后的值,在Excutor端更新。
(二)累加器不是一个调优的操作,因为如果不这样做,结果是错的(必须这样做)
(三)累加器没有改变Spark的lazy计算模型,如果累计器在RDD的操作中更新了,累计器的值只会在RDD作为action的一部分被计算时更新。所以,在lazy的transformation中(如map()),累加器的更新不能保证被执行。
为了安全起见,始终只在action中使用累加器。
(四)更多关于transformation和action可以见四中
四:累加器的使用
(一)累加器累加一个数组
//在driver中定义 val acc = sc.longAccumulator("Test Accumulator") //在task中进行累加 sc.parallelize(1 to 10).foreach(x => acc.add(x)) //在driver中输出 println(acc.value)
(二)累加器错误用法---少加(transformation)
val accum = sc.longAccumulator("Error Accumulator") val numberRDD = sc.parallelize(1 to 10).map(n => { accum.add(1) n + 1 }) println("accumulator: " + accum.value)
执行完毕,打印的值时多少呢?
答案是0,累加器没有改变Spark的lazy计算模型,如果累计器在RDD的操作中更新了,累计器的值只会在RDD作为action的一部分被计算时更新。所以,在lazy的transformation中(如map()),累加器的更新不能保证被执行。
(三)累加器错误用法---多加(transformation和action)
val accum = sc.longAccumulator("Error2 Accumulator") val numberRDD = sc.parallelize(1 to 10).map(n => { accum.add(1) n + 1 }) numberRDD.count() println("accum1: " + accum.value) numberRDD.reduce(_+_) println("accum2: " + accum.value)
结果得到:
accum1:10 accum2: 20
虽然只在map里进行了累加器加1的操作,但是两次得到的累加器的值却不一样,这是由于count和reduce都是action类型的操作,触发了两次作业的提交,所以map算子实际上被执行了两次,在reduce操作提交作业后累加器又完成了一轮计数,所以最终的累加器的值为20。究其原因是因为count虽然促使numberRDD累计出来,但是由于没有对其进行缓存,所以下次再次需要使用numberRDD这个数据集时,还需要从并行化数据集的部分开始执行计算。解释道这里,这个问题的解决方法也就很清楚了,就是在count之前调用numberRDD的cache方法(或persist),这样在count后数据集就会被缓存下来,reduce操作就会读取缓存的数据集,而无需从头开始计算。
(四)使用cache保持数据一致
val accum = sc.longAccumulator("Error2 Accumulator") val numberRDD = sc.parallelize(1 to 10).map(n => { accum.add(1) n + 1 }) numberRDD.cache().count() println("accum1: " + accum.value) numberRDD.reduce(_+_) println("accum2: " + accum.value)
这次两次打印的值就会保持一致了。都是10。
(五)如果累计器在actions操作算子里面执行时,只会累加一遍。可以实现(四)中情况
val accum = sc.longAccumulator("Error2 Accumulator") val numberRDD = sc.parallelize(1 to 10).map(n => { n + 1 }) numberRDD.foreach(t =>{ accum.add(1) }) println("accum1: " + accum.value) numberRDD.reduce(_+_) println("accum2: " + accum.value)
输出结果:
accum1: 10 accum2: 10
(六)对比transformation和action
对于只在actions执行更新操作的累加器,Spark会保证任务对累加器的更新操作只会应用一次,例如,重启任务不会更新累加器的值。在transformations中用户应该意识到,如果任务或作业阶段重新执行,每个任务的更新操作会应用多次。
(七)transformation和action补充:聚合算子
def method2(lines: RDD[String]): Unit = { val totalAcc: LongAccumulator = lines.sparkContext.longAccumulator("total") //定义累加器 val dbRDD: RDD[String] = lines.filter(line => { //filter transformation延时计算 val fields = line.split("\^") val jobs = fields(1) jobs.contains("大数据") || jobs.contains("hadoop") || jobs.contains("spark") }) val eduRDD = dbRDD.map( line => { //map transformation延时计算 totalAcc.add(1) val fields = line.split("\^") val edu = fields(6) (edu, 1) }).reduceByKey(_ + _) //reduce transformation延时计算 //确保累加器执行 eduRDD.count() //count action直接触发计算 val sum = totalAcc.value println(sum) eduRDD.foreach{ case (edu, count) =>{ println(s"学历是${edu}的人数为${count},占得比例为: "+count/(sum+0.0)) }} println(totalAcc.value) }
上面代码结果为sum=448,但是经过foreach()后,得到的totalAcc.value的结果仍然是448?
分析:
测试发现eduRDD是dbRDD经过map和reduceByKey两个算子得到的结果,所以eduRDD经过多次action算子也不会重复累加了。
但是如果将map和reduceByKey算子分开,并且是在map中添加的累加器,那重复调用reduceByKey后生成的RDD的action算子,将会翻倍累加。(eduRDD1.reduceByKey,其中eduRDD1是通过dbRDD.map添加累加器后生成的),此时为重复调用eduRDD1,即重复进行累加。
但是连着使用两个算子后,调用将不会重复累加,通过测试发现当经过聚合算子的操作后,得到的RDD重复调用action,累加类不再进行累加。
五:内置累加器
上面的代码使用了内置支持的Long类型累加器,当然还存在其他内置支持的累加器:double类型、集合Collection类型
(一)集合累加器---官方提供的一个自定义累加器案例
def main(args: Array[String]): Unit = { val conf = new SparkConf().setAppName("wordcount").setMaster("local[2]") val sc = new SparkContext(conf) case class User(name:String,telephone:String) val collect_plus=Array(User("Alice","15837312345") //这是我们将要进行累加的值 ,User("Bob","13937312666") ,User("Thomas","13637312345") ,User("Tom","18537312777") ,User("Boris","13837312998") ) val rdd05=sc.parallelize(collect_plus,2) val user_plustool=sc.collectionAccumulator[User]("用户累加器") //定义累加器 rdd05.foreach(user => { val teletephone=user.telephone.reverse if (teletephone(0)==teletephone(1) && teletephone(0)==teletephone(2)){ user_plustool.add(user) //进行累加 } } ) println(user_plustool) } }
六:自定义累加器
(一)自定义累加器讲解
可以通过AccumulatorV2创建自己的类型。AccumulatorV2抽象类由多个方法,其中必须重写的是:
reset:用于重置累加器为0
add:用于向累加器加一个值
merge:用于合并另一个同类型的累加器到当前累加器
其它必须重写的方法有:
copy():创建此累加器的新副本 isZero():返回该累加器是否为零值 value():获取此累加器的当前值
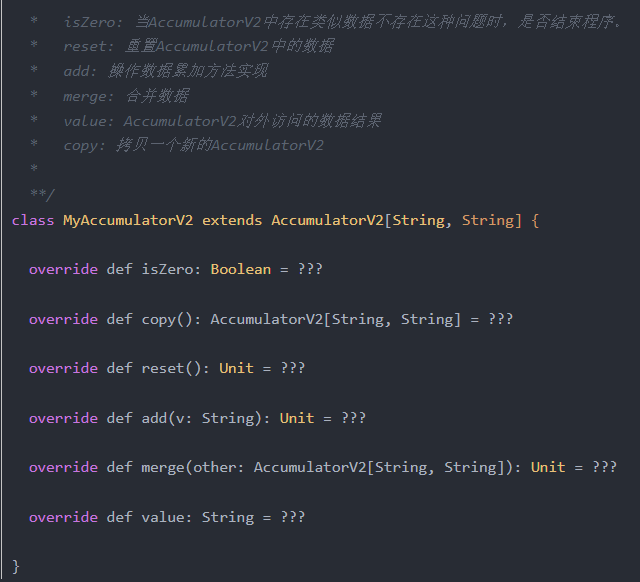
(二)自定义累加器实现
下面这个累加器可以用于在程序运行过程中收集一些文本类信息,最终以Set[String]的形式返回。
package com.rk.spark import java.util import org.apache.spark.util.AccumulatorV2 class MyAccumulatorV2 extends AccumulatorV2[String, java.util.Set[String]]{ private val set:java.util.Set[String] = new util.HashSet[String]() override def isZero: Boolean = { set.isEmpty } override def reset(): Unit = { set.clear() } override def add(v: String): Unit = { set.add(v) } override def merge(other: AccumulatorV2[String, util.Set[String]]): Unit = { other match { case o:MyAccumulatorV2 => set.addAll(o.value) } } override def value: java.util.Set[String] = { java.util.Collections.unmodifiableSet(set) } override def copy(): AccumulatorV2[String, util.Set[String]] = { val newAcc = new MyAccumulatorV2() set.synchronized{ newAcc.set.addAll(set) } newAcc } }
(三)测试自定义累加器
package com.rk.spark import org.apache.log4j.{Level, Logger} import org.apache.spark.{SparkConf, SparkContext} object AccumulatorTest { def main(args: Array[String]): Unit = { Logger.getLogger("org.apache.hadoop").setLevel(Level.OFF) Logger.getLogger("org.apache.spark").setLevel(Level.OFF) Logger.getLogger("org.spark-project").setLevel(Level.OFF) //设置日志打印级别 val conf = new SparkConf() .setMaster("local[*]") .setAppName(this.getClass.getSimpleName) val sc = new SparkContext(conf) //自定义 val myAccum = new MyAccumulatorV2 //定义自定义累加器 sc.register(myAccum, "MyAccumulator") val sum: Int = sc.parallelize( Array("1", "2a", "3", "4f", "a5", "6", "2a"), 2) .filter(line => { //用于过滤掉一些数据 val pattern = """^-?(d+)""" val flag = line.matches(pattern) //返回为0,没有匹配成功,过滤掉。返回1,匹配成功,保留 if (!flag) { myAccum.add(line) //将我们filter要过滤掉的数据保存到累加器中 } flag }).map(_.toInt).reduce(_ + _) println("sum: " + sum) for (v <- myAccum.value.toArray) { print(v + " ") } println() sc.stop() } }
本例中利用自定义的收集器收集过滤操作中被过滤掉的元素,当然这部分的元素的数据量不能太大。
sum: 10 4f a5 2a