补充:Eclipse自动补全快捷键
在Windows下自动补全快捷键是Alt+/
在Linux下自动补全快捷键是ctrl+空格
一:导入jar包
(一)定义用户依赖库
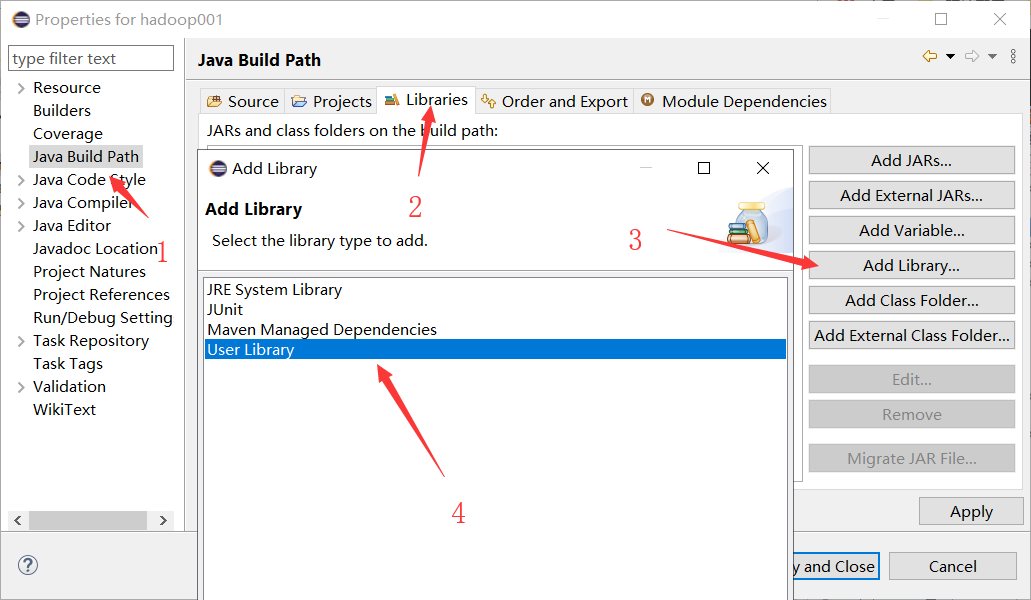
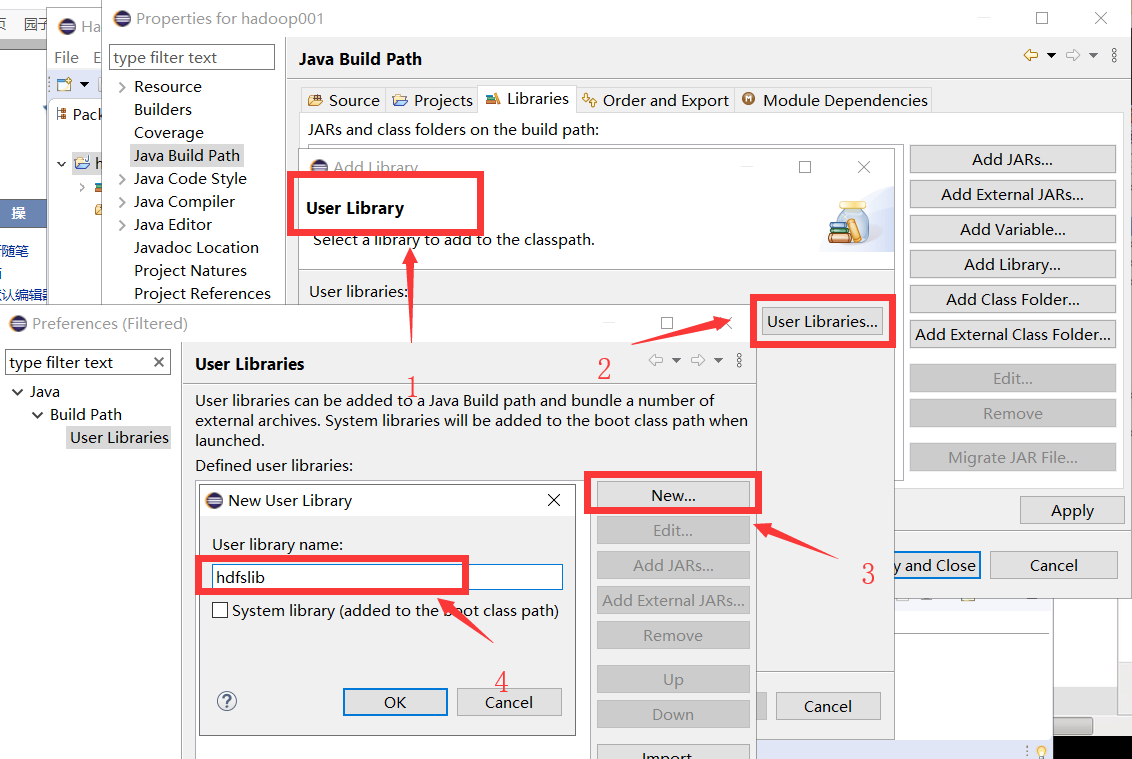
(二)导入 hdfs基础jar包
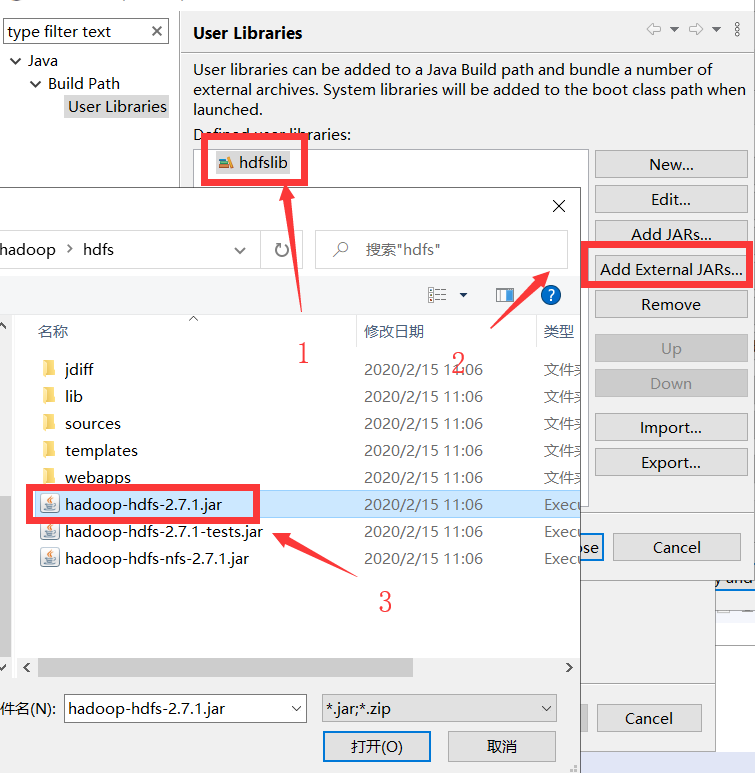
(三)导入hdfs基础jar包所依赖的库

(四)导入公共jar包
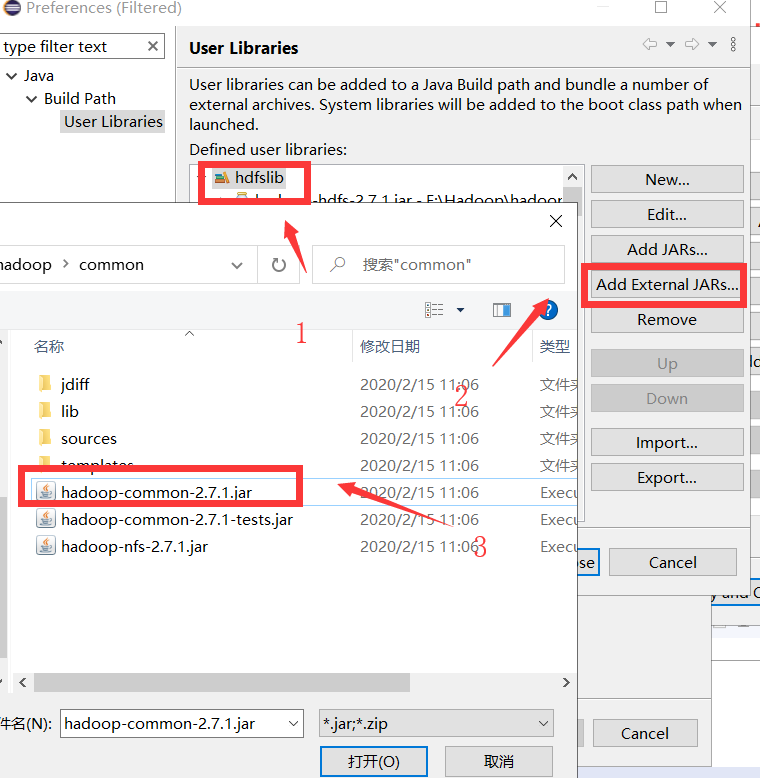
(五)导入公共jar包所需lib库
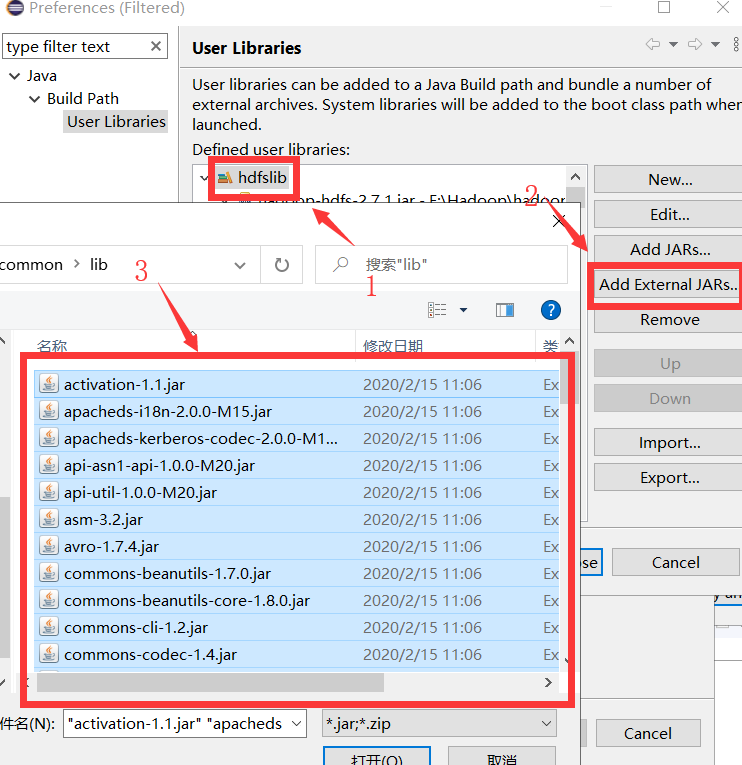
(六):创建类

二:实现下载文件
(一)要访问hdfs,需要获取FileSystem类(必须是org.apache.hadoop.fs包下)的实例对象
import org.apache.hadoop.fs.FileSystem;

其中FileSystem类是抽象类,要获取对象,需要调用静态方法:
FileSystem fs = FileSystem.get(conf);
(二)FileSystem实例化需要用到配置信息Configuration类
import org.apache.hadoop.conf.Configuration;
Configuration conf = new Configuration();
注意:配置类需要core-site.xml和hdfs-site.xml文件,才可以解析hdfs://链接
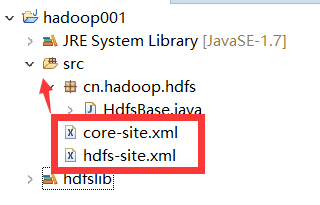
Configuration对象会读取classpath下的xxx-site.xml配置文件,并解析其内容,封装到对象中
(三)获取hdfs系统文件路径,打开hdfs输入流
Path f = new Path("hdfs://hadoopH1:9000/jdk-7u80-linux-x64.tar.gz"); //指定路径
FSDataInputStream in = fs.open(f); //打开hdfs输入流
(四)打开本地文件输出流,利用IOUtils将输入流数据拷贝到输出流
FileOutputStream out = new FileOutputStream("/home/hadoop/Download/jdk.tar.gz"); //打开文件输出流,输入文件路径 IOUtils.copy(in, out);
(五)使用fs.copyToLocalFile(src, dst);下载
(六):全部代码实现
1.全部代码
package cn.hadoop.hdfs; import java.io.FileOutputStream; import java.io.IOException; import org.apache.commons.io.IOUtils; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; public class HdfsBase { public static void main(String[] args) throws IOException { //要访问hdfs,需要获取FileSystem类(必须是org.apache.hadoop.fs包下)的实例对象 Configuration conf = new Configuration(); FileSystem fs = FileSystem.get(conf); //fs对象就是HDFS的客户端,用fs就可以读文件,写文件,查看文件... //下载文件 Path f = new Path("hdfs://hadoopH1:9000/jdk-7u80-linux-x64.tar.gz"); //指定路径 FSDataInputStream in = fs.open(f); //打开hdfs输入流 FileOutputStream out = new FileOutputStream("E:\jdk.tar.gz"); //打开文件输出流,输入文件路径 IOUtils.copy(in, out); //上传数据到hdfs文件系统 } }
2.代码运行
三:实现文件上传
(一)代码实现
public void upload() throws IOException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoopH1:9000/"); FileSystem fs = FileSystem.get(conf); Path f = new Path("hdfs://hadoopH1:9000/Day01/linux-2.6.tar.gz"); FSDataOutputStream out = fs.create(f); FileInputStream in = new FileInputStream("E:\源码\linux-2.6.19.tar.gz"); IOUtils.copy(in, out); //上传数据 }
(二)处理权限问题

因为windows下是使用ssyfj这个文件名进行的文件上传,而实际上Hadoop下文件拥有用户组是supergroup,用户是hadoop

1.设置用户名为hadoop(在运行配置中):------程序中配置

-DHADOOP_USER_NAME=hadoop
2.使用FileSystem.get参数配置

public void upload2() throws IOException, InterruptedException, URISyntaxException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoopH1:9000/"); FileSystem fs = FileSystem.get(new URI("hdfs://hadoopH1:9000/"),conf,"hadoop"); fs.copyFromLocalFile(new Path("E:\源码\linux-2.6.19.tar.gz"), new Path("hdfs://hadoopH1:9000/Day01/linux2.6.taz")); }
3.在Hadoop HDFS文件系统中配置目录的权限(任何人都可读可写)------HDFS配置

(三)运行结果显示
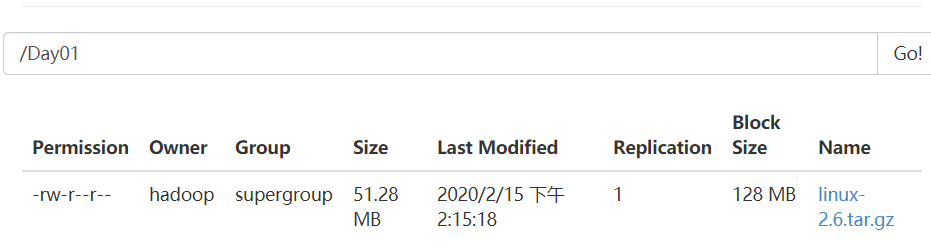
四:创建目录
public void mkdir() throws IOException, InterruptedException, URISyntaxException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoopH1:9000/"); FileSystem fs = FileSystem.get(new URI("hdfs://hadoopH1:9000/"),conf,"hadoop"); fs.mkdirs(new Path("/new/dir/")); }

五:目录/文件删除
public void rm() throws IOException, InterruptedException, URISyntaxException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoopH1:9000/"); FileSystem fs = FileSystem.get(new URI("hdfs://hadoopH1:9000/"),conf,"hadoop"); fs.delete(new Path("/new"), true); //可以设置是否递归删除 }

六:查看、移动、重命名....
(一)递归列出文件信息
public void listFiles() throws IOException, InterruptedException, URISyntaxException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoopH1:9000/"); FileSystem fs = FileSystem.get(new URI("hdfs://hadoopH1:9000/"),conf,"hadoop"); RemoteIterator<LocatedFileStatus> files = fs.listFiles(new Path("/"), true); //递归列出目录 while(files.hasNext()) { LocatedFileStatus file = files.next(); Path filePath = file.getPath(); String fileName = filePath.getName(); System.out.println(fileName); } }
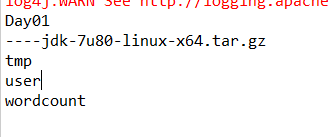
(二)结果显示
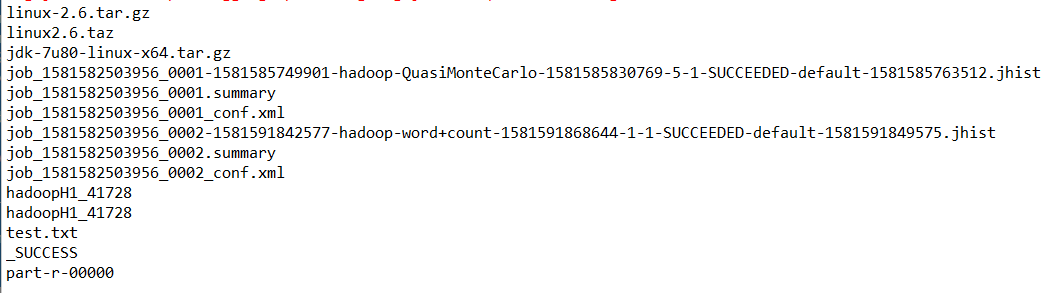
(三)目录显示--非递归
public void listFiles() throws IOException, InterruptedException, URISyntaxException { Configuration conf = new Configuration(); conf.set("fs.defaultFS", "hdfs://hadoopH1:9000/"); FileSystem fs = FileSystem.get(new URI("hdfs://hadoopH1:9000/"),conf,"hadoop"); FileStatus[] listStatus = fs.listStatus(new Path("/")); for(FileStatus status: listStatus) { if(status.isDirectory()) { System.out.println(status.getPath().getName()); }else { System.out.println("----"+status.getPath().getName()); } } }