阅读目录
概要
Hadoop有以下3种运行模式:
- 独立(或本地)模式 : 无需运行任何守护进程,所有程序都在同一个JVM上运行。在此模式下测试和调试MapReduce程序很方便,因此该模式在开发阶段比较合适。
- 伪分布模式: Hadoop守护进程运行在本地机器上,模拟一个小规模的集群;
- 全分布模式: Hadoop守护进程运行在一个集群上。
在独立模式下,将使用本地文件系统和本地MapReduce作业运行器;
在分布模式下,将启动HDFS和MapReduce(或YARN)守护进程。
本文主要介绍伪分布模式的搭建。
环境说明:
- 操作系统 :Centos 6.8
- java版本 :jdk1.6.0_45
- hadoop版本:hadoop-1.2.1
准备工作:
- java文件 :jdk-6u45-linux-x64.bin
- hapoop文件:hadoop-1.2.1.tar.gz
本文主要内容如下:
- 安装Java1.6;
- 设置ssh无密码登录;
- 安装hadoop1.2.1,并修改配置文件;
- Hadoop启动;
- 测试hadoop;
本文经过本人亲自实践,可行。
二、设置ssh无密码登录
- 在伪分布模式下工作必须启动守护进程,而启动守护进程的前提是已经安装SSH。
- Hadoop并不严格区分伪分布模式和全分布模式,它只是在集群内的(多台)主机(由slaves文件定义)上启动守护进程:SSH到各个主机并启动一个守护进程。
- 伪分布模式是全分布模式的一个特例。
- 在伪分布模式下,(单)主机就是本地计算机(localhost),因此需要确保用户能够SSH到本地机器,并且可以不输入密码。
SSH免密码登陆,应该在hadoop安装环境所在的用户下配置,比如本Hadoop伪集群搭建在hadoop用户下,则SSH 免密码登陆应该在hadoop用户下配置。
具体步骤如下:
1. 检查是否安装了ssh,若没有安装,则安装(以下指令并非都要执行):
rpm -qa| grep ssh //检查是否安装service sshd status //查看ssh运行状态yum install ssh //安装sshchkconfig --list sshd //查看是否开机启动chkconfig sshd on //设置开机启动
2. 创建hadoop用户和组
groupadd hadoopuseradd -g hadoop -d /home/hadoop hadooppasswd hadoop
3. 设置ssh无密码登录
方式1:(测试没问题)
su - hadoopssh-keygen -t rsa //在~/.ssh/目录下生成id_rsa私钥和id_rsa.pub公钥cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keyschmod 600 ~/.ssh/authorized_keys
把公钥加到用于认证的公钥文件中,authorized_keys是用于认证的公钥文件
方式2: (未测试,应该可用)
基于空口令创建新的SSH密钥,以实现无密码登录
su - hadoopssh-keygen -t rsa -P '' -f ~/.ssh/id_rsacat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 600 ~/.ssh/authorized_keys
4. 测试
在本机上输入:
ssh localhost //首次时会让输入yes/no,但是不需要密码
三、Hadoop的安装(在Hadoop用户下)
su - hadoopmkdir ~/hadoop-env //将hadoop-1.2.1.tar.gz拷贝到该文件夹下cd hadoop-env/tar zxvf hadoop-1.2.1.tar.gz //安装Hadoop
配置环境变量
su -vi /etc/profile
添加内容如下:
# set hadoopexport HADOOP_HOME=/home/hadoop/hadoop-env/hadoop-1.2.1export PATH=$HADOOP_HOME/bin:$PATH
使环境变量生效
source /etc/profileexit //退回到Hadoop用户
四、配置Hadoop相关配置文件
配置文件主要有如下几个:
- hadoop-env.sh;
- core-site.xml:用于配置通用属性;
- hdfs-site.xml:用于配置HDFS属性;
- mapred-site.xml:用于配置MapReduce属性;
- masters和slaves文件;
- /etc/hosts;
此外,docs子目录下还存放这个3个HTML文件,即:
- core-default.html
- hdfs-default.html
- mapred-default.html
分别保存各部分的默认属性配置。
下面介绍不同模式的关键配置属性:
| 组件名称 | 属性名称 | 独立模式 | 伪分布模式 | 全分布模式 |
| Common | fs.default.name | file:///(默认) | hdfs://localhost/ | hdfs://namenode/ |
| HDFS | dfs.replication | N/A | 1 | 3(默认) |
| MapReduce 1 | mapred.job.tracker | local | localhost:8021 | jobtracker:8021 |
| YARN(MapReduce 2) | yarn.resource.manager.address | N/A | localhost:8032 | resourcemanager:8032 |
1. 配置文件【hadoop-env.sh】
主要配置Java_home和hadoop安装环境变量。
cd /home/hadoop/hadoop-env/hadoop-1.2.1/conf/cp hadoop-env.sh hadoop-env.sh.origvi hadoop-env.sh
添加内容如下:
#set java environmentexport JAVA_HOME=/usr/program/jdk1.6.0_45export HADOOP_HOME_WARN_SUPPRESS=true
添加HADOOP_HOME_WARN_SUPPRESS的目的是防止老是出现“warning:$HADOOP_HOME is deprecated”
2. 配置文件【core-site.xml】
cd /home/hadoop/hadoop-envmkdir hadooptmpchmod 777 -R /home/hadoop/hadoop-env/hadooptmp/ (以root用户执行)cp core-site.xml core-site.xml.origvi core-site.xml
内容如下:
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>fs.default.name</name><value>hdfs://localhost:9000/</value> 注:9000后面的“/”不能少</property><property><name>hadoop.tmp.dir</name><value>/home/hadoop/hadoop-env/hadooptmp</value></property></configuration>
说明:hadoop分布式文件系统的两个重要的目录结构,一个是namenode上名字空间的存放地方,一个是datanode数据块的存放地方,还有一些其他的文件存放地方,这些存放地方都是基于hadoop.tmp.dir目录的,比如namenode的名字空间存放地方就是 ${hadoop.tmp.dir}/dfs/name, datanode数据块的存放地方就是${hadoop.tmp.dir}/dfs/data,所以设置好hadoop.tmp.dir目录后,其他的重要目录都是在这个目录下面,这是一个根目录。我设置的是进入/home/hadoop/hadoop-env/hadooptmp,当然这个目录必须是存在的。
3. 配置文件【hdfs-site.xml】
cp hdfs-site.xml hdfs-site.xml.origvi hdfs-site.xml
内容如下:
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>dfs.replication</name><value>1</value></property></configuration>
4.配置文件【mapred-site.xml】
cp mapred-site.xml mapred-site.xml.origvi mapred-site.xml
内容如下:
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href="configuration.xsl"?><!-- Put site-specific property overrides in this file. --><configuration><property><name>mapred.job.tracker</name><value>localhost:9001</value></property></configuration>
5. 配置文件【masters和slaves文件】
cd /home/hadoop/hadoop-env/hadoop-1.2.1/confcp masters masters.origcp slaves slaves.origvi mastersvi slaves
内容都设置为:
localhost
说明:因为在伪分布模式下,作为master的namenode与作为slave的datanode是同一台服务器,所以配置文件
中的ip是一样的。
6. 主机名和IP解析配置(以root用户操作)
cp /etc/hosts /etc/hosts.origvi /etc/hosts
内容如下:
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4::1 localhost localhost.localdomain localhost6 localhost6.localdomain6127.0.0.1 master127.0.0.1 slave
说明:因为在伪分布模式下,所以master和slave是同一台机器。
五、Hadoop启动
1. 格式化新的HDFS文件系统
- 在使用Hadoop前必须格式化生成一个全新的HDFS安装。
- 该过程创建一个空文件系统,仅包含存储目录和namenode持久化数据结构的初始版本。由于namenode管理文件系统的元数据,并且datanode可以动态的加入或离开集群,因此这个格式化过程不针对datanode。
- 同理,文件系统的规模也无从谈起,集群中datanode的数量将决定文件系统的规模。
- datanode可以在文件系统格式化很久之后按需增加。
下面是格式化HDFS文件系统指令:(以hadoop用户执行)
su - hadoopcd /home/hadoop/hadoop-env/hadoop-1.2.1/bin/hadoop namenode -format //nodename和-format中间有空格
将会生成如下命令结构:
- hadoop.tmp.dir/dfs/name目录;
2. 启动Hadoop所有的进程
在启动hadoop所有的任务之前,先以root用户修改日志目录的权限(否则会报hadoop没有相应权限);
su -chmod -R 777 /home/hadoop/hadoop-env/hadoop-1.2.1/libexec/../logs/service iptables stop //关闭防火墙
启动hadoop所有进程
su - hadoopcd /home/hadoop/hadoop-env/hadoop-1.2.1/bin/./start-all.sh
将会生成如下命令结构:
- hadoop.tmp.dir/dfs/data: 存放datanode上的数据块数据;
- hadoop.tmp.dir/dfs/namesecondary :是namenode的一个备份;
- hadoop.tmp.dir/mapred/local目录;
3. 查看守护进程是否正在运行:
jps
启动进程说明:
start-all.sh调用了如下语句:
- start-dfs.sh
- start-mapred.sh
start-dfs.sh启动了如下进程:
- namenode;
- datanode;
- secondarynamenode;
start-mapred.sh启动了如下进程:
- jobtracker;
- tasktracker;
正常情况下应该能看到:
11761 SecondaryNameNode //是namenode的一个备份12097 Jps11637 DataNode11524 NameNode11862 JobTracker11981 TaskTracker
启动之后,会在$hadoop.tmp.dir/dfs目录下生成data目录,这里面存放的是datanode上的数据块数据;
说明:
- secondaryname是namenode的一个备份,里面同样保存了名字空间和文件到文件块的map关系。建议运行在另外一台机器上,这样master死掉之后,还可以通过secondaryname所在的机器找回名字空间,和文件到文件块得map关系数据,恢复namenode。
- 启动之后,会在$hadoop.tmp.dir/dfs目录下生成data目录,这里面存放的是datanode上的数据块数据;因为笔者用的是单机,所以name和 data都在一个机器上,如果是集群的话,namenode所在的机器上只会有name文件夹,而datanode上只会有data文件夹。
问题解决:
在搭建过程中,在此环节出现的问题最多,经常出现启动进程不完整的情况,要么是datanode无法正常启动,就是namenode或是TaskTracker启动异常。解决的方式如下:
- 在Linux下关闭防火墙:使用service iptables stop命令;关闭hadoop:stop-all.sh
- 再次对namenode进行格式化:/home/hadoop/hadoop-env/hadoop-1.2.1/bin目录下执行hadoop namenode -format命令;
- 对服务器进行重启;
- 查看datanode或是namenode对应的日志文件,日志文件保存在/home/hadoop/hadoop-env/hadoop-1.2.1/logs目录下;
- 再次在/bin目录下用start-all.sh命令启动所有进程,通过以上的几个方法应该能解决进程启动不完全的问题了;
4. 通过web界面查看集群状态
cd /home/hadoop/hadoop-env/hadoop-1.2.1/bin/hadoop dfsadmin -report
在web页面下查看hadoop工作情况:
- Namenode:localhost:50070
- JobTracker:localhost:50030
- localhost:50070(或者 ip:50070查重,如:10.180.0.231::50070)
- 查看namenode

- localhost:50030(或者 ip:50030查重)
- 查看jobtracker启动情况
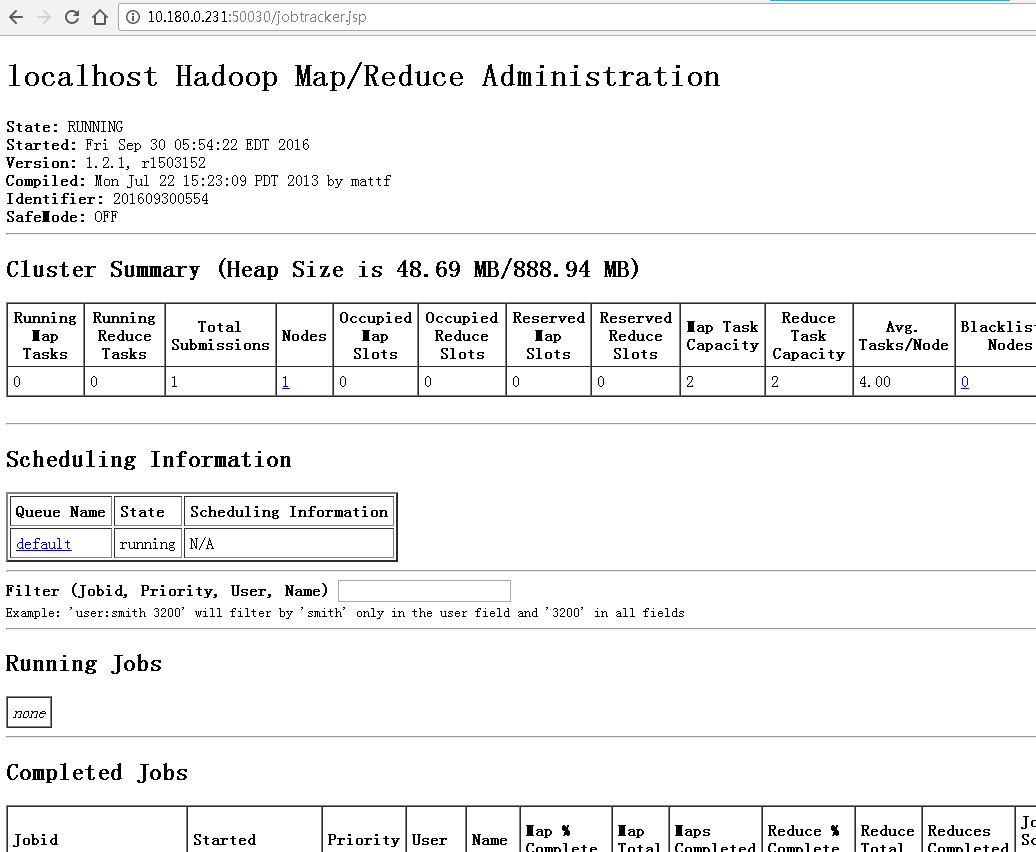
说明:
若是在其他机器上访问不了,很可能是防火墙的问题,此时service iptables
stop(root用户操作),然后重新web访问就可以了。
六、Hadoop环境测试
一个测试例子是wordcount,计算输入文本中词语数量的程序。wordCount在Hadoop主目录下的Java程序包hadoop-example-1.2.1.jar中。
1. 文件准备
/home/hadoop/hadoop-env/hadoop-1.2.1mkdir testcd testvi file01 (输入数个单词)vi file02 (输入数个单词)
2. 在hdfs分布式文件系统创建目录input:
hadoop fs -mkdir input
查看创建情况:
hadoop fs -ls
输出:
drwxr-xr-x - hadoop supergroup 0 2016-09-30 06:30 /user/hadoop/input
3. 离开hadoop的安全模式
hadoop dfsadmin -safemode leave
说明:
hadpoop安全模式相关命令 :
hadoop dfsadmin -safemode enter/leave/get/wait
hadoop的hdfs系统在安全模式下只能进行“读”操作!不能进行文件等的删除、创建、更新操作。
4. 将数据从linux文件系统复制到hdfs分布式文件系统中的input文件夹中;
hadoop fs -put /home/hadoop/hadoop-env/hadoop-1.2.1/test/* input
5. 执行示例程序:
hadoop jar /home/hadoop/hadoop-env/hadoop-1.2.1/hadoop-examples-1.2.1.jar wordcount input output
说明:
- hadoop jar:执行“jar”命令
- /home/hadoop/hadoop-env/hadoop-1.2.1/hadoop-examples-1.2.1.jar:wordcount所在的jar包
- wordcount:程序主函数名
- input output:输入输出文件夹
6. 查看执行结果:
hadoop fs -ls
结果:可以看到多了文件夹output
drwxr-xr-x - hadoop supergroup 0 2016-09-30 06:53 /user/hadoop/inputdrwxr-xr-x - hadoop supergroup 0 2016-09-30 06:56 /user/hadoop/output
查看输出结果:
hadoop dfs -cat output/*
可以看到执行结果:
......Summary 1The 1This 2Trap 1at 4by 1client 1counts 1......
查看web界面,可以看到刚才的运行结果
7. 关闭hadoop所有进程
cd /home/hadoop/hadoop-env/hadoop-1.2.1/bin/./stop-all.sh