一、背景:在工作中总会用到各种统计工作,并且这个工作会反复的做,那么,可不可以让这些重复的工作自动化呢?
基于这个想法,把工作中常做的重复的工作给自动化一下
二、目标:实现分类统计,即统计相同项目的数量,如下表

统计的结果应该是:经济管理学院 1
电气信息工程学院 2
机械科学与工程学院 1
三、使用工具软件:python3.7
1、准备数据(g:/test.xlsx)
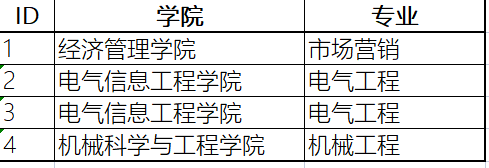
2、实现


1 # -*- coding:utf-8 -*- 2 3 import pandas as pd 4 import numpy as np 5 6 df = pd.read_excel('G:/test.xlsx') 7 pt1 = pd.pivot_table(df,index=["学院"], aggfunc='count',margins_name='合计',margins='True') 8 #pt1 = df.groupby('学院')['学院'].agg('count') 9 print(pt1)
(1)pt1 = pd.pivot_table(df,index=["学院"], aggfunc='count',margins_name='合计',margins='True') 的结果

(2)pt1 = df.groupby('学院')['学院'].agg('count')的结果

问题来了:
为什么(1)(2)的结果有差别呢?
如果让(1)结果跟(2)一样,不需要后面的两个字段呢?
目前还没有找到解决办法,希望知道的人在后面回复一下,我也学习学习!