树、二叉树、查找算法总结
一.思维导图
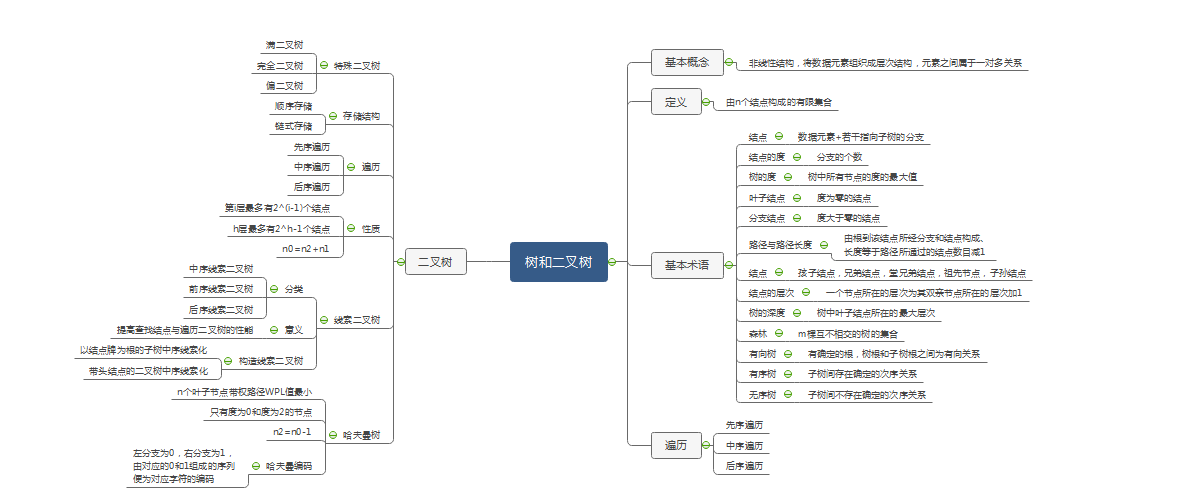
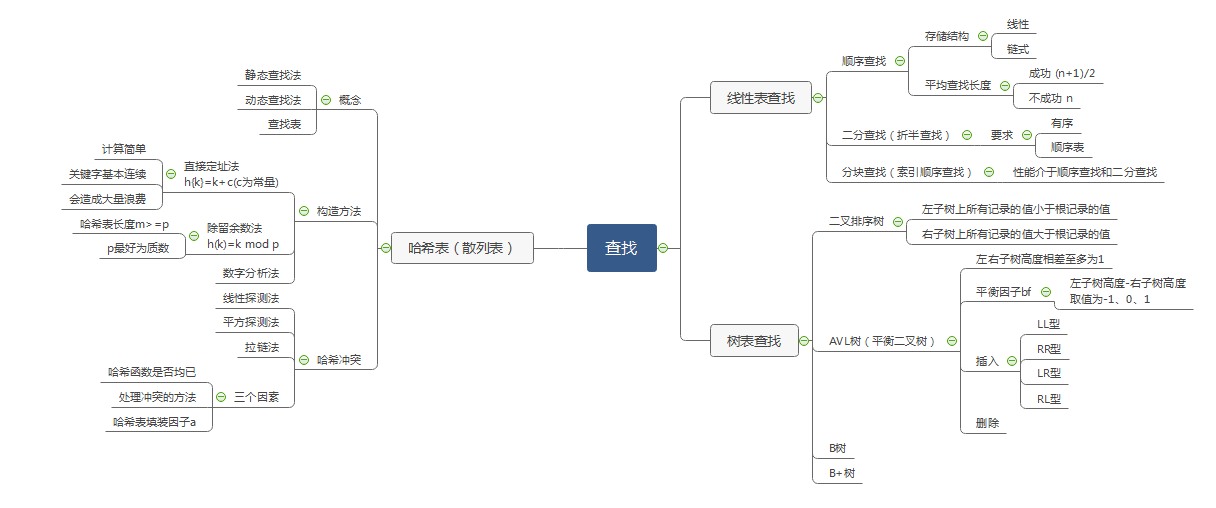
二.重要概念的笔记
1.树的基本术语
结点为数据元素+若干指向子树的分支,结点的度为分支的个数
树的度为树中所有结点的度的最大值,树的深度为树中叶子结点所在的最大层次
叶子结点为度为零的结点,分支结点为度大于零的结点
路径与路径长度:由从根到该结点所经分支和结点构成,长度等于路径所通过的节点数目减1
结点的层次:一个节点所在的层次为其双亲节点所在的层次加1
2.二叉树的性质
1.第i层上组多有2^(i-1)个结点
2.深度为h的二叉树最多有2^h-1个结点
3.n0=n2+1
4.具有n个结点的完全二叉树的深度为「log2n」+1
5.二叉树是由左、右子树的二叉树和根节点组成。
typedef struct BiTNode {
char data;
struct BiTNode* lchild, * rchild;
}BiTNode, * BiTree;
3.遍历二叉树
1.先序遍历
int PreOrderTraverse(BiTree T) {
if (T != NULL) {
cout << T->data;
PreOrderTraverse(T->lchild);
PreOrderTraverse(T->rchild);
}
return 1;
}
2.中序遍历
int InOrderTraverse(BiTree T) {
if (T != NULL) {
InOrderTraverse(T->lchild);
cout << T->data;
InOrderTraverse(T->rchild);
}
return 1;
}
3.后序遍历
int PostOrderTraverse(BiTree T) {
if (T != NULL) {
PostOrderTraverse(T->lchild);
PostOrderTraverse(T->rchild);
cout << T->data;
}
return 1;
}
线索二叉树
1.提高查找结点与遍历二叉树的性能,n个结点的二叉树空指针个数为:n*2-(n-1)=n+1;
2.线索二叉树存储结构设计:在节点的存储结构上增加两个标志位来区分两种情况
哈夫曼树
1.带权路径WPL最小
2.仅有度为0和2的节点
3.哈夫曼编码:规定哈夫曼树中的左分支为0,右分支为1,从根节点到每个叶节点所经过的分支对应的0和1组成的序列便为该叶子节点对应字符的编码。这样的编码称为哈夫曼编码.
线性表的查找
1.顺序查找:有顺序和链式两种存储结构,查找成功的平均查找长度为(n+1)/2,不成功为n,算法简单,对表的结构无太多要求,但查找效率低
2.二分查找:也称折半查找法,对表比较有要求,适用于有序的顺序表,查找效率高
3.分块查找:又称索引顺序查找,是以索引的方式存储和查找线性表,将数据分为许多块,块内元素可以无序,块与块是有序的,性能介于顺序查找和二分查找之间
哈希表
1.构造方法
- 1.直接定址法,h(k)=k+c(c为常量),计算简单但会造成浪费,不可能发生冲突,但需要待处理的数据关键字基本连续
- 2.除留余数法,h(k)=k mod p(p最好为质数),p需小于或等于哈希表长度m
- 3.数字分析法,通过对关键字中每一位数字的取值分布情况进行分析,提取取值较均匀的数字位作为哈希地址的方法,适合于所有关键字值都已知的情况
2.哈希冲突解决方法
- 1.线性探测法,当h(k)地址被占用发生冲突,地址+1 且取余 m,直到找到空闲地址
- 2.平方探测法,d0=h(k),di = (d0 ± i^2),是一种较好的处理冲突的方法,可以避免出现堆积问题,不能探测到所有单元,但至少能探测到一半单元
- 3.拉链法,是用单链表把所有的同义词单链表连接起来的方法
三.疑难问题及解决方案
疑难问题
题目

输出样例

PTA题目哈夫曼树,给出n个结点求其构成的哈夫曼树的权值,刚开始遇到这道题,觉得很简单,在纸上我们可以轻易构造成哈夫曼树,若转为代码变复杂很多了。一般思路可能是在构造二叉树结点的基础上多构造指向父母的结点,并采用递归思想构建哈夫曼树,还要随时注意找出最小的两个结点的值来结合,一般的思路想起来会很麻烦,仔细研究哈夫曼树的性质找找方向
解决过程
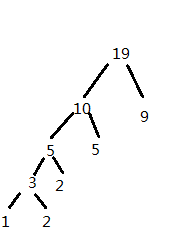
这为题目样例构造的哈夫曼树
当我们计算哈夫曼树的权值的时候,每个节点的值乘上该结点的高度h,哈夫曼树有一个特点就是最底下的叶子节点的值必定会比上层小,且构造过程先取两个最小结点的值,这是其中一点。观察图中我们会发现最底层1和2结点计算权值时为14=24,倒二层2结点为2*3,会发现这其实是一个累积过程,最五层的值加了四次,第四层加了3次,第三层加了2次,这其实是一个递归的过程,接下来讲解代码实现的过程,结合代码来理解。
先构造一个可以排序的怼,规定数值从小到大排列,priority_queue<int, vector<int>, greater<int>>q;,让元素全部入队,出队两次p和q均为一组数的最小值,相加后入队,定义一个WPL,使得WPL+= p + q ,重复该循环到结束得到该WPL的值,具体代码如下:
#include<iostream>
#include<queue>
using namespace std;
int main()
{
int n, m, sum = 0;
priority_queue<int, vector<int>, greater<int>>q;
cin >> n;
for (int i = 0; i < n; i++)
{
cin >> m;
q.push(m);
}
for (int i = 0; i < n - 1; i++)
{
int a = q.top();
q.pop();
int b = q.top();
q.pop();
q.push(a + b);
sum += a + b;
}
cout << sum;
return 0;
}