Hello,上一篇(http://www.cnblogs.com/souvenir/p/4969399.html)我们简单的分享了JS中的变量存储原理,但是并未结束,我们漏掉了什么。
对了,就是关于对象的存储。
大家都知道,JavaScript中的变量类型分为两种,一种是基本数据类型,包括:undefined,null,Number,String,Boolean,另外一种就是对象。
两种数据类型的存储方式在JS中也有所不同。
另外,内存分为栈区(stack)和堆区(heap),然后在JS中开发人员并不能直接操作堆区,堆区数据由JS引擎操作完成,那这二者在存储数据上到底有什么区别呢?
我们简单的通过下面这张图来分析:

JS中变量的定义在内存中包括三个部分:
-
- 变量标示 (比如上图中的Str,变量标示存储在内存的栈区)
- 变量值 (比如上面中的Str的值souvenir或者是obj1对象的指向堆区地址,这个值也是存储在栈区)
- 对象 (比如上图中的对象1或者对象2,对象存储在堆区)
也就是说,对于基本数据类型来说,只使用了内存的栈区。
对于上一篇中提到的问题来说,
1 var a = 100; 2 3 func(); 4 5 function func(){ 6 console.log(a); 7 var a=200; 8 console.log(a); 9 }
在JS预加载阶段,JS引擎只是在内存的栈区为每个变量分配了内存,指定了标示符,并未为其指定值。
等到JS执行期才会为其赋值。
现在我们再来看对象变量的问题就比较清楚了,例如下面的:
1 var a=100; 2 var obj1={ 3 attr:'hello' 4 }; 5 6 func(a,obj1); 7 8 function func(num,obj){ 9 var a2=num; 10 a2=200; 11 12 var obj2=obj; 13 obj2.attr='hello'; 14 } 15 16 console.log(a); 17 console.log(obj1.attr);
我们分别定义了一个基本类型和对象类型的变量,然后在函数中对其分别执行复制操作,然后修改新变量的值。
最后的执行结果为:
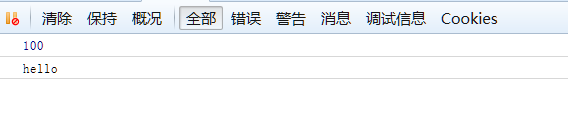
对于基本数据类型,在执行第9行时,JS是把num在栈区的值,也就是100复制给了a2这个局部变量,然后在第10行又修改了a2的值,
这个操作过程并未影响到全局变量a的值。
小结:
对于对象来说,当JS执行12行的时候,实际上是把obj在栈区的值,也就是obj对象在堆区的引用地址,复制给了新的局部变量obj2,
这时候,obj2与obj实际上已经指向了同一个堆区的对象,然后obj2修改了这个对象的某个属性值。然后函数执行完毕,obj2这个局部变量没有引用将会被GC回收。
再次访问obj1这个全局变量时,其所指向的对象其实已经被修改过了。