一、distinct,group by与ROW_Number()窗口函数使用方法
1. Distinct用法:对select 后面所有字段去重,并不能只对一列去重。
(1)当distinct应用到多个字段的时候,distinct必须放在开头,其应用的范围是其后面的所有字段,而不只是紧挨着它的一个字段,而且distinct只能放到所有字段的前面
(2)distinct对NULL是不进行过滤的,即返回的结果中是包含NULL值的
(3)聚合函数中的DISTINCT,如 COUNT( ) 会过滤掉为NULL 的项
2.group by用法:对group by 后面所有字段去重,并不能只对一列去重。
3. ROW_Number() over()窗口函数
注意:ROW_Number() over (partition by id order by time DESC) 给每个id加一列按时间倒叙的rank值,取rank=1
select m.id,m.gender,m.age,m.rank
from (select id,gender,age,ROW_Number() over(partition by id order by id) rank
from temp.control_201804to201806
where id!='NA' and gender!='' or age!=''
) m
where m.rank=1
二、案例:
1.表中有两列:id ,superid,按照superid倒序排序选出前100条不同的id,如下:
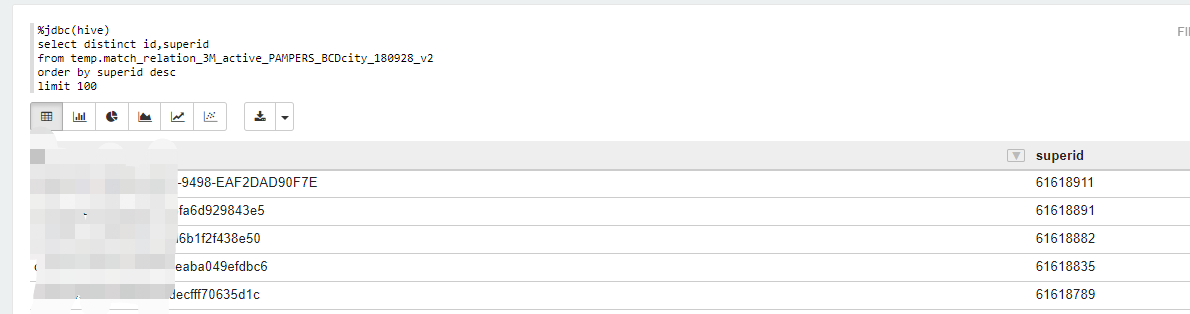
1.方案一:
子查询中对id,superid同时去重,可能存在一个id对应的superid不同,id这一列有重复的id,但 是结果只需要一列不同的id,如果时不限制数量,则可以选择这种方法
%jdbc(hive)
create table temp.match_relation_3M_active_v5 as
select a.id
from (select distinct id,superid
from temp.match_relation_3M_activ
order by superid desc
limit 100
) a
group by a.id
注意,对id去重时可以用gruop by 或者distinct id,两者去重后的id排序时一致的,但是加了distinct(group by)后,distinct字段自带排序功能,会先按照distinct后面的字段进行排序,即已经改变了子查询的中order by的排序,但是结果与正确结果中的id是一样的,只是排序不同罢了。
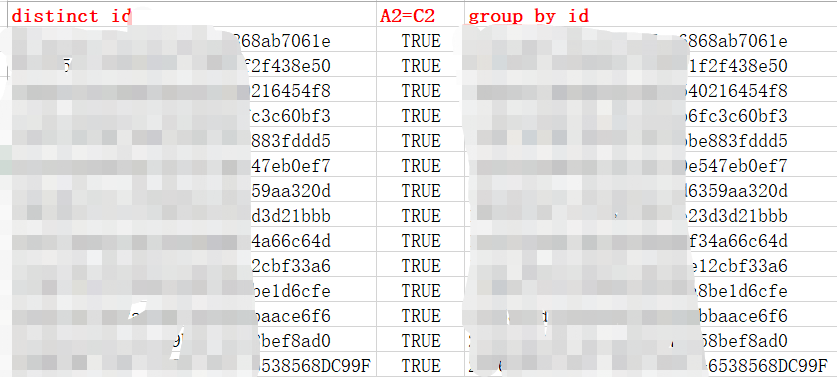
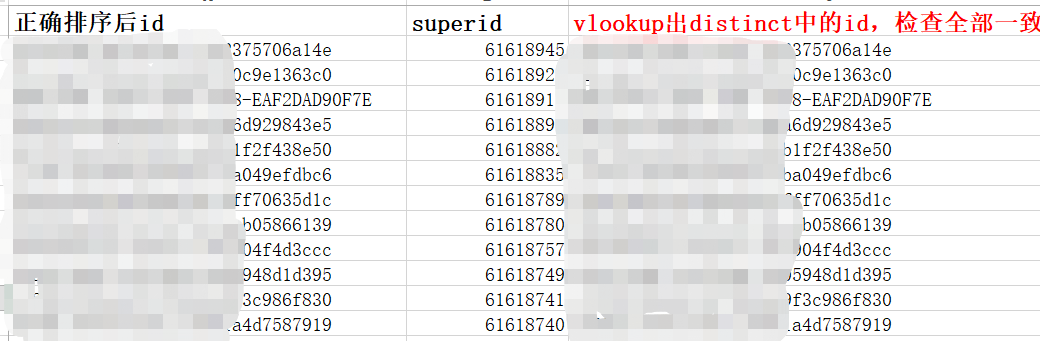
方案二:
因为要求按照superid倒序排序选出,而一个id对应的superid不同,必有大有小,选出最大的那一个,即可。 同理若是按照superid正序排列,可以选出最小的一列
%jdbc(hive)
create table temp.match_relation_3M_active_v7 as
select a.id
from (select id,max(superid) as superid
from temp.match_relation_3M_active
group by id
order by superid desc
limit 100
) a
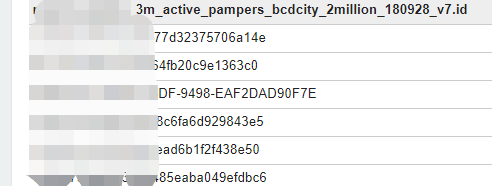
方案三:
首先利用窗口函数ROW_Number() over()窗口函数对id这一列去重,不能用distinct或者group by对id,superid同时去重
%jdbc(hive)
create table temp.match_relation_3M_active_v11 as
select n.id
from (select m.id,superid
from (select id,superid,ROW_Number() over(partition by id order by id) rank
from temp.match_relation_3M_active
) m
where m.rank=1
order by superid desc
limit 100
)n
注意,以下代码中,窗口函数ROW_Number() over()的执行顺序晚于 order by superid desc,最终的结果并非 superid的倒叙排列的结果
%jdbc(hive)
create table temp.match_relation_3M_active_v9 as
select m.id
from (select id, superid,ROW_Number() over(partition by id order by id) rank
from temp.match_relation_3M
order by superid desc
) m
where m.rank=1
group by m.id
limit 100
