一、简述
本文主要讲如何利用图片相似性算法,基于LIRE来实现图片搜索。
二、依赖
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>6.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>6.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>6.3.0</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-io/commons-io -->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.commons/commons-math3 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-math3</artifactId>
<version>3.6.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.sangupta/jopensurf -->
<dependency>
<groupId>com.sangupta</groupId>
<artifactId>jopensurf</artifactId>
<version>1.0.0</version>
</dependency>
</dependencies>
二、样例1
Data目录下存放所有图片的样本。
package com.dearcloud.imagesearch; import net.semanticmetadata.lire.aggregators.AbstractAggregator; import net.semanticmetadata.lire.aggregators.BOVW; import net.semanticmetadata.lire.builders.DocumentBuilder; import net.semanticmetadata.lire.imageanalysis.features.global.CEDD; import net.semanticmetadata.lire.imageanalysis.features.local.opencvfeatures.CvSurfExtractor; import net.semanticmetadata.lire.imageanalysis.features.local.simple.SimpleExtractor; import net.semanticmetadata.lire.indexers.parallel.ParallelIndexer; import net.semanticmetadata.lire.searchers.GenericFastImageSearcher; import net.semanticmetadata.lire.searchers.ImageSearchHits; import net.semanticmetadata.lire.searchers.ImageSearcher; import net.semanticmetadata.lire.utils.FileUtils; import net.semanticmetadata.lire.utils.ImageUtils; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.store.FSDirectory; import javax.imageio.ImageIO; import java.io.File; import java.io.IOException; import java.nio.file.Paths; public class IndexingAndSearchWithLocalFeatures { public static void main(String[] args) throws IOException { String indexPath = "D:\以图搜图\衬衣\index"; String imageData = "D:\以图搜图\衬衣\Data"; indexer(indexPath, imageData); String searchImage = "D:\以图搜图\衬衣\search\timg.jpg"; String searchOutputFolder = "D:\以图搜图\衬衣\output"; search(indexPath, searchImage, searchOutputFolder); } /** * Indexing data using OpenCV and SURF as well as CEDD and SIMPLE. * @param indexFolder * @param imageDirectory */ private static void indexer(String indexFolder, String imageDirectory) { // Checking if arg[0] is there and if it is a directory. boolean passed = false; // use ParallelIndexer to index all photos from args[0] into "index". int numOfDocsForVocabulary = 500; Class<? extends AbstractAggregator> aggregator = BOVW.class; int[] numOfClusters = new int[]{128}; ParallelIndexer indexer = new ParallelIndexer(DocumentBuilder.NUM_OF_THREADS, indexFolder, imageDirectory, numOfClusters, numOfDocsForVocabulary, aggregator); indexer.setImagePreprocessor(image -> ImageUtils.createWorkingCopy(image)); //Local indexer.addExtractor(CvSurfExtractor.class); //Simple indexer.addExtractor(CEDD.class, SimpleExtractor.KeypointDetector.CVSURF); indexer.run(); System.out.println("Finished indexing."); } /** * Linear search on the indexed data. * @param indexPath * @throws IOException */ public static void search(String indexPath, String searchFile, String searchOutputFolder) throws IOException { IndexReader reader = DirectoryReader.open(FSDirectory.open(Paths.get(indexPath))); // make sure that this matches what you used for indexing (see below) ... ImageSearcher imgSearcher = new GenericFastImageSearcher(1000, CEDD.class, SimpleExtractor.KeypointDetector.CVSURF, new BOVW(), 128, true, reader, indexPath + ".config"); // just a static example with a given image. ImageSearchHits hits = imgSearcher.search(ImageIO.read(new File(searchFile)), reader); for (int i = 0; i < hits.length(); i++) { double score = hits.score(i); String imagePath = reader.document(hits.documentID(i)).getValues(DocumentBuilder.FIELD_NAME_IDENTIFIER)[0]; System.out.printf("%.2f: (%d) %s ", score, hits.documentID(i), imagePath); } String outputHtmlReport = FileUtils.saveImageResultsToHtml("search-", hits, searchFile, reader); System.out.println("Report:" + outputHtmlReport); org.apache.commons.io.FileUtils.copyFile(org.apache.commons.io.FileUtils.getFile(outputHtmlReport), org.apache.commons.io.FileUtils.getFile(searchOutputFolder, outputHtmlReport)); } }
三、样例2
1、Indexer
package com.dearcloud.imagesearch; import net.semanticmetadata.lire.builders.GlobalDocumentBuilder; import net.semanticmetadata.lire.imageanalysis.features.global.AutoColorCorrelogram; import net.semanticmetadata.lire.imageanalysis.features.global.CEDD; import net.semanticmetadata.lire.imageanalysis.features.global.FCTH; import net.semanticmetadata.lire.utils.FileUtils; import org.apache.lucene.analysis.core.WhitespaceAnalyzer; import org.apache.lucene.document.Document; import org.apache.lucene.index.IndexWriter; import org.apache.lucene.index.IndexWriterConfig; import org.apache.lucene.store.FSDirectory; import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.nio.file.Paths; import java.util.ArrayList; import java.util.Iterator; public class LireIndexer { public static void main(String[] args) throws IOException { String indexPath = "D:\以图搜图\全部\index"; String imageData = "D:\以图搜图\全部\Data"; index(indexPath, imageData); } private static void index(String indexFolder, String imageDirectory) throws IOException { // Getting all images from a directory and its sub directories. ArrayList<String> images = FileUtils.getAllImages(new File(imageDirectory), true); // Creating a CEDD document builder and indexing all files. GlobalDocumentBuilder globalDocumentBuilder = new GlobalDocumentBuilder(false, false); /* If you want to use DocValues, which makes linear search much faster, then use. However, you then have to use a specific searcher! */ // GlobalDocumentBuilder globalDocumentBuilder = new GlobalDocumentBuilder(false, true); /* Then add those features we want to extract in a single run: */ globalDocumentBuilder.addExtractor(CEDD.class); globalDocumentBuilder.addExtractor(FCTH.class); globalDocumentBuilder.addExtractor(AutoColorCorrelogram.class); // Creating an Lucene IndexWriter IndexWriterConfig conf = new IndexWriterConfig(new WhitespaceAnalyzer()); IndexWriter iw = new IndexWriter(FSDirectory.open(Paths.get(indexFolder)), conf); // Iterating through images building the low level features for (Iterator<String> it = images.iterator(); it.hasNext(); ) { String imageFilePath = it.next(); System.out.println("Indexing " + imageFilePath); try { BufferedImage img = ImageIO.read(new FileInputStream(imageFilePath)); if (img == null) continue; Document document = globalDocumentBuilder.createDocument(img, imageFilePath); iw.addDocument(document); } catch (Exception e) { System.err.println("Error reading image or indexing it."); e.printStackTrace(); } } // closing the IndexWriter iw.close(); System.out.println("Finished indexing."); } }
2、Searcher
package com.dearcloud.imagesearch; import net.semanticmetadata.lire.builders.DocumentBuilder; import net.semanticmetadata.lire.imageanalysis.features.global.CEDD; import net.semanticmetadata.lire.searchers.GenericFastImageSearcher; import net.semanticmetadata.lire.searchers.ImageSearchHits; import net.semanticmetadata.lire.searchers.ImageSearcher; import org.apache.commons.io.FileUtils; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexReader; import org.apache.lucene.store.FSDirectory; import javax.imageio.ImageIO; import java.awt.image.BufferedImage; import java.io.IOException; import java.nio.file.Paths; public class LireSearcher { public static void main(String[] args) throws IOException { String indexPath = "D:\以图搜图\全部\index"; String searchImage = "D:\以图搜图\全部\search\timg.jpg"; String searchOutputFolder = "D:\以图搜图\全部\output"; search(indexPath, searchImage, searchOutputFolder); } private static void search(String indexFolder, String searchFile, String searchOutputFolder) throws IOException { BufferedImage img = ImageIO.read(FileUtils.getFile(searchFile)); IndexReader reader = DirectoryReader.open(FSDirectory.open(Paths.get(indexFolder))); ImageSearcher searcher = new GenericFastImageSearcher(30, CEDD.class); // ImageSearcher searcher = new GenericFastImageSearcher(30, AutoColorCorrelogram.class); // for another image descriptor ... /* If you used DocValues while Indexing, use the following searcher: */ // ImageSearcher searcher = new GenericDocValuesImageSearcher(30, CEDD.class, ir); // searching with a image file ... ImageSearchHits hits = searcher.search(img, reader); // searching with a Lucene document instance ... // ImageSearchHits hits = searcher.search(ir.document(0), ir); for (int i = 0; i < hits.length(); i++) { String fileName = reader.document(hits.documentID(i)).getValues(DocumentBuilder.FIELD_NAME_IDENTIFIER)[0]; System.out.println(hits.score(i) + ": " + fileName); } String outputHtmlReport = net.semanticmetadata.lire.utils.FileUtils.saveImageResultsToHtml("search-", hits, searchFile, reader); System.out.println("Report:" + outputHtmlReport); org.apache.commons.io.FileUtils.copyFile(org.apache.commons.io.FileUtils.getFile(outputHtmlReport), org.apache.commons.io.FileUtils.getFile(searchOutputFolder, outputHtmlReport)); } }
四、素材

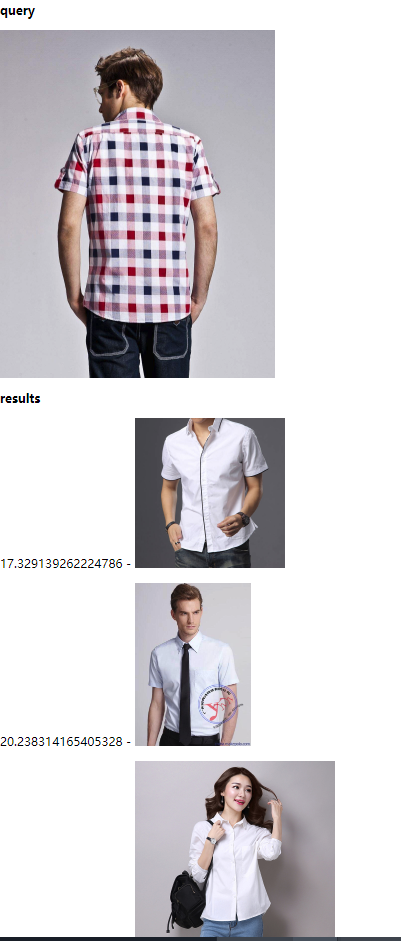
五、LIRE支持的算法