Application example: Photo OCR (photo optical character recognition 照片光学字符识别)
Problem description and pipeline
The Photo OCR problem
主要解决的问题,让计算机从我们拍摄的照片中读出文字信息。步骤:
- 给定某张图片,它将把图片浏览一遍,然后找出图片中哪里有文字信息。
- 重点关注文字区域,并在区域中对文字内容进行识别。
- 如果能读出文字,则对其进行转录。
目前的OCR技术对扫描文档来说,是一个比较简单的问题,但对于数码照片来说,还是一个比较困难的机器学习问题。
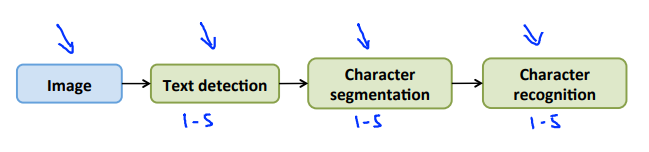
Photo OCR pipeline
照片光学字符识别流水线
- Text detection 浏览图像,找出有文字的区域。
- Character segmentation 通过得到文字区域的矩形轮廓,进行字符切分。
- Character classification 在成功将字段分割为独立的字符后,通过运行一个分类器,输入这些可识别的字符,尝试识别出各字母。
Sliding windows
Supervised learning for pedestrian detection
文字区域识别是一个相对较难的问题,因为文字识别区域会有非常多的变化,宽高比都不固定,所以先以人物识别为例讲述如何进行识别(因为人物,尤其是站立的人物,其宽高比是基本固定的)。
为了建立一个行人检测系统,我们需要首先收集样本,假如我们决定要使用(82 imes 36)的分辨率来进行标准化,我们要做的是去搜集一些正例和反例,有人物的标记为1,没有人物的标记为0。然后通过有监督学习,我们就有了一个模型可以识别类似图片中是否有人。
Sliding window detection
用同样宽高比例的方框,从图片一角开始滑动,每次滑动所取的区域图片都可以利用我们之前训练的模型来识别是否有人,这样从头到尾的滑动一遍之后,我们就知道那个区域有人,哪个区域没有人。

滑动的距离被定义为step-size或者stride,可以是一个像素,也可以是多个像素。step-size越小则最后可能识别错误的可能越小
由于远近的关系,图片中有的人物会比较大,有的会比较小,所以我们可能需要不同尺寸的矩形框去扫描。但是需要注意的是即使使用了不同尺寸我们也可以保持同样的宽高比,然后再将原尺寸矩形框通过拉伸或者压缩使得其符合(82 imes 36)的分辨率,然后再使用模型进行识别。
Text detection
与行人检测类似,我们首先训练出能够区分字符与非字符的模型,然后,运用滑动窗口技术识别字符。一旦完成了字符的识别,我们将识别得出的区域进行一些扩展,然后将重叠的区域进行合并。接着我们以宽高比作为过滤条件,过滤掉高度比宽度更大的区域(认为单词的长度通常比高度要大)。下图中红色的区域是经过这些步骤后被认为是文字的区域,而绿色的区域是被忽略的。

1D Sliding window for character segmentation
一维滑动窗口字符分割。
将有文字的区域送入下一个环节,进行文字分割。首先也要有一个模型,来训练其识别字符的分割线,如下图所示:
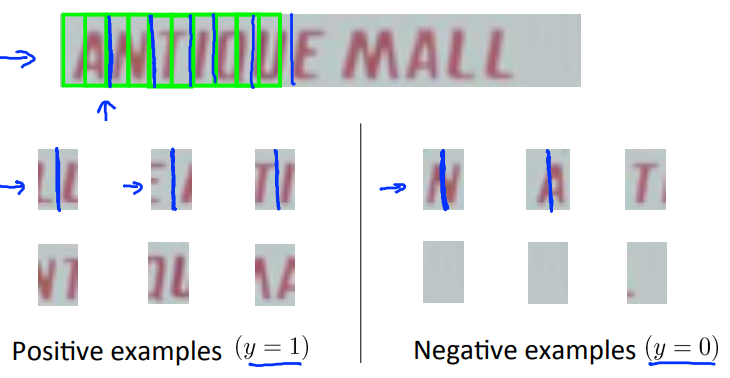
训练分割字符的模型:将中间可分割的图片标记为1,不可分割的图片标记为0,从而训练出一个模型。然后再利用滑动窗口在我们之前框出的文字区域进行滑动识别,从而分割字符。分割好之后,就是利用我们之前课程讲过的文字识别的模型进行文字识别即可。
以上便是字符切分阶段。 最后一个阶段是字符分类阶段,利用神经网络、支持向量机
或者逻辑回归算法训练一个分类器即可。
Getting lots of data: Artificial data synthesis
Character recognition
如何获得大量数据?其中一个技巧就是人造数据,通过合成,失真等方法我们可以生成一些“假”的数据,但是这些数据却能大幅提升我们模型的性能。
Artificial data synthesis for photo OCR
通过把不同字形的字符放到不同的背景中合成新的样本。

Synthesizing data by introducing distortions
通过引入失真来生成新的样本。
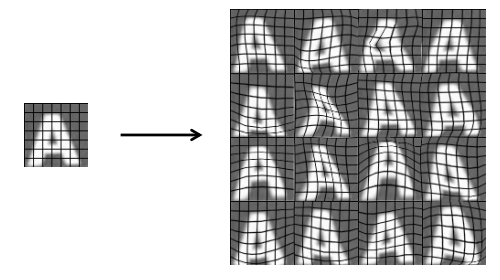
Synthesizing data by introducing distortions: Speech recognition
不同的领域合成数据的方式是不同的,比如在语音识别领域,我们是通过引入不同的背景噪音来合成新的样本数据。

Discussion on getting more data
- Make sure you have a low bias classifier before expending the effort. (Plot learning curves). E.g. keep increasing the number of features/number of hidden units in neural network until you have a low bias classifier. 在增加数据之前首先要确认你已经有了一个低偏差的模型,其实也就是我们之前课程所说的要先看看我们模型目前面临的是一个什么问题,是高偏差问题还是高方差问题,只有当我们解决了高偏差问题之后,才需要考虑增加数据量的问题。
- "How much work would it be to get 10x as much data as we currently have?" 通常在项目中我们需要问下“要获取10倍的数据量需要投入多少资源(人力和时间)”,通常,很可能我们不需要花费太多的时间就可以获取到10倍的数据量,从而大幅提升我们的模型的性能。
- 获取更多数据的方法
- Artificial data synthesis 人工合成数据。
- Collect/label it yourself 自己标记。
- "Crowd source" (E.g. Amazon Mechanical Turk) 找相应的众包网站,去雇佣其它人来进行标记。
Ceiling analysis: What part of the pipeline to work on next
Ceiling analysis 上限分析
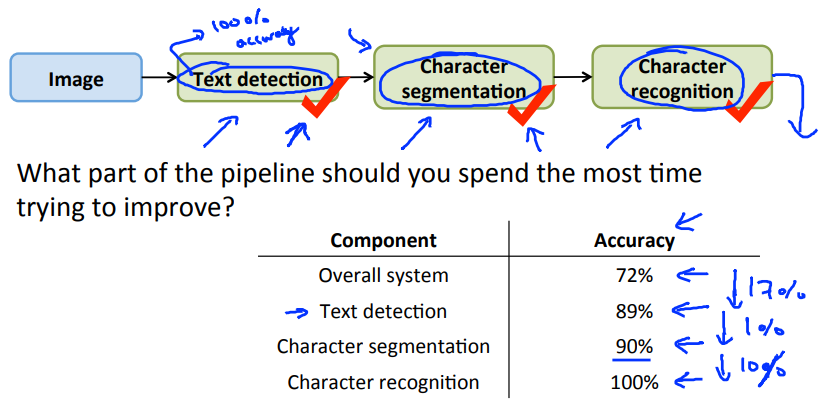
上限分析是分析流水线中每个模块对算法的影响度的分析,即那个模块对算法的改进最有用,然后我们把我们的精力资源投入到那个产出更高的模块。以下图为例进行说明:
-
现有模型在测试集中测试错误率为72%。
-
在Text detection模块的输出数据中使用100%正确的数据(比如人工检查圈选),再用模型跑一下测试集,这时候我们会得到一个新的错误率,本例是89%。这样我们就知道当我们改进我们Text detection模块时,我们最多可以让系统性能提升17%(89%-72%)。
-
将Character segmentation模块输出的数据全部设置为正确的输出,这之后新的错误率是90%。说明改进Character segmentation在对系统整体性能的提升上限只有1%。
-
同理,改进Character recognition模块对系统整体性能的提升上限为10%。
根据上面的实验,我们可以有选择的将精力放在对应模块上。
Another ceiling analysis example

总结:通过人工干预,使某一个模块的准确率人工达到100%,再使用这些数据训练,如果这一模块的变化导致整体系统的系统变得很好,那么说明这个模块值得花时间优化。反之,我们将某一模块达到100%,系统性能仍没有提升很多,则说明这一模块不值得我们花费精力改进。
我们在一个项目的流水线中,可以通过上限分析来得出究竟哪个模块的改善对于我们系统的整体性能提升有很大的帮助,然后将我们的资源和精力投入到那些模块中。