跳跃表(SkipList)是一种高效的搜索用途的数据结构,从链表结构演化而来,它是基于有序链表的扩展,思想类似于二分法查找,不断地缩小查找范围,减少遍历的次数。redis和levelDB底层都用了它。这个是维基百科上的解释https://en.wikipedia.org/wiki/Skip_list。
对于一般的链表我们知道,要查询一个元素,只能顺序搜索遍历整个链表直到找到元素为止,时间复杂度为O(n)。比如下图有一个有序链表,

如果要在链表中检索元素6,则需要从链表头部开始遍历,遍历次数为6次,时间复杂度为O(n),如果是数组的话,则可以采用二分查找,时间复杂度为O(logn);但是链表因为不支持随机访问,即使有序,也没法采用二分法查找。所以聪明的科学家想到了一个办法去改进现有链表的结构,就是在原有链表的基础上在加一层,为了提高数据的查询效率,就把链表中的个别有特殊意义元素单独拿出来,在当前链表之上再次创建一个链表作为索引。

我们可以提取节点我奇数的作为关键节点。这样在原来的链表基础上多了一层,节点数更少。测试如果我们想查找节点6的话,这次只需要比较关键节点1,3,5。当在关键节点链表确定了位置时候就可以回到原链表中找到6的位置。所以这里关键节点链表相当于一个1级索引,可以减少一半比较的次数。但是如果该链表的节点数很多,要比较的次数依然很多,那么同理我们可以在一级索引的基础上提取关键节点建立二级索引,又加上一层。
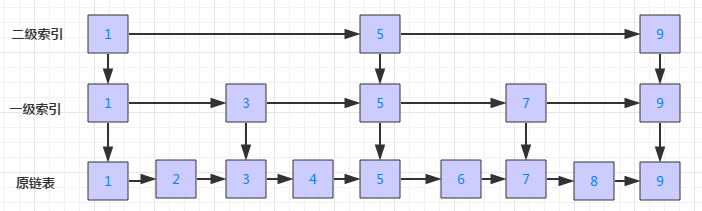
原来的链表变成了三个层次,第1层是最顶层的索引。
案例:查找元素 8
- 首先在顶层链表(二级索引)中比较节点 5, 8比 5大,但是小于9,这时候就取得5节点的地址 。
- 到第二层(一级索引),比较节点7,8>7,但是小于9,这时候就取得7节点的地址 。
- 到第一层,找到7后面的节点8,8=8也就找到了节点。
跳表具有如下性质:
1. 由很多层结构组成 。
2. 每一层都是一个有序的链表结构,
3. 最底层(Level 1)的链表包含所有元素 。
4.如果一个元素出现在 Level 1 的链表中,则它在 Level 1之下的链表也都会出现。
5.每个节点包含两个指针,一个指向同一链表中的下一个元素,一个指向下面一层的元素。
同理链表的插入和删除也没有想象中的高,因为插入和删除隐含的意义是先查找到插入和删除的位置,再进行操作。跳跃表只不过它在链表的基础上增加了跳跃功能,正是这个跳跃的功能,使得在查找元素时,跳表能够提供O(log n)的时间复杂。
跳跃表在很多软件中得到应用,比如kv数据库LevelDB 静态结构(内存中的MemTable),redis的sorted set数据都是用跳跃表来实现。