---恢复内容开始---
1.CentOS主机配置
在配置Hadoop过程中,防火墙必须优先关闭SELinux,否则将影响后续Hadoop配置与使用,命令如下:
# 查看 “系统防火墙” 状态命令
systemctl status firewalld.service
# 关闭 “系统防火墙” 命令
systemctl stop firewalld.service
# 关闭 “系统防火墙” 自启动命令
systemctl disable firewalld.service
# 关闭 “SELinux”命令
setenforce 0
# 关闭“SELinux”系统系统自启动服务
vi /etc/selinux/config
# 修改内容
SELINUX=disabled
(1)执行图结果如下:
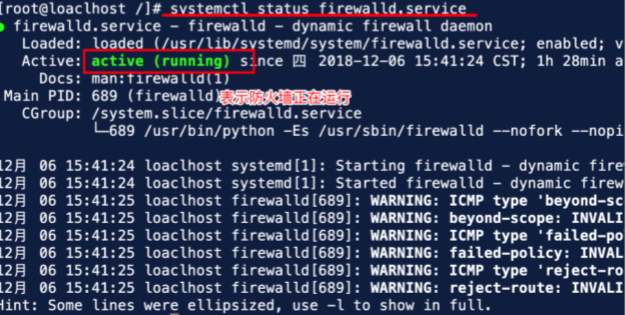
(2)上图的防火墙处于运行状态,现在关闭防火墙,如下图:
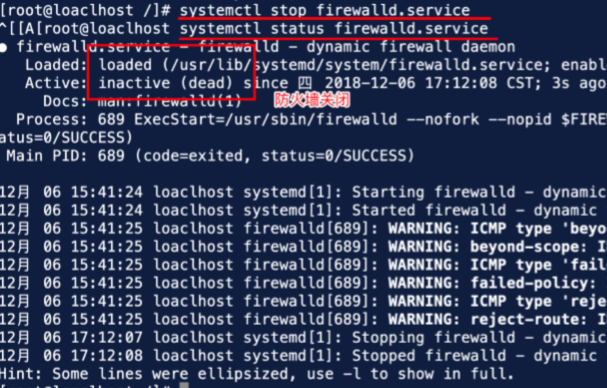
(3)关闭防火墙后,因为重启服务器防火墙会自动重启,关闭系统自启动命令如下:
# systemctl firewalld.service
2.设置主机名称
(1)使用vi编译器编译 #vi /etc/sysconfig/network,修改其内容:
# 修改为:
NETWORKING=yes
HOSTNAME=master
(2)修改主机名,进入#vi /etc/hostname里修改内容:
# 修改为: master
3.配置hosts文件
(1)编译#vi /etc/hosts添加内容,不用去掉原先内容:
#添加内容
192.168.56.110 master
(2)192.168.56.110为IP地址。
4.验证配置结果
(1)重启后主机为master。
# 重启系统命令
reboot now
(2)在终端输入命令 #ping master -c 5查看是否成功。
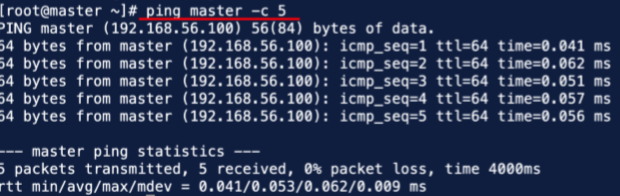
5.JavaJDK环境配置
(1)上传JDK文件,使用xftp将jdk传到/opt目录下,如图:
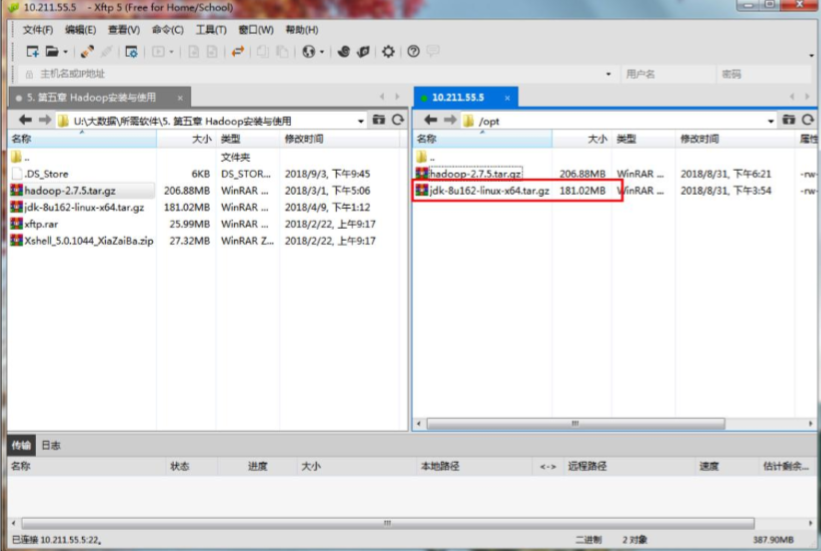
(2)解压缩JDK安装包
进入/opt 目录并解 压 缩 文 件 #tar -zxvf /opt/jdk-8u162-linux-x64.tar.gz
(3)移动 javaJDK 目录至/usr/local/java 中 ,其环境变量地址与Java目录一致
#mv /opt/jdk1.8.0_162 /usr/local/java
(4)配置环境变量
编辑 .bash_profile 文件 :
#vi /root/.bash_profile
添加内容 :
export JAVA_HOME=/usr/local/java
export PATH=$JAVA_HOME/bin:$PATH
使环境变量生效:
#source /root/.bash_profile
(5)验证JDK配置是否成功,使用# java -version,结果如下:

6.Hadoop安装与配置
(1)使用xftp将Hadoop软件包上传至/opt下,如图:
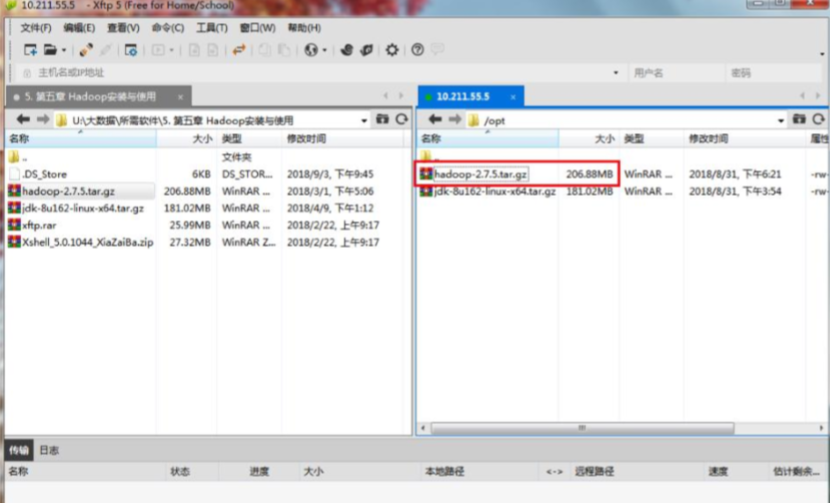
(2)解压Hadoop
上传完成后,解压缩文件 #tar -zxvf /opt/hadoop-2.7.5.tar.gz
修改 hadoop-2.7.6-src 目录名称为 hadoop
#mv /opt/hadoop-2.7.5 /opt/hadoo
(3)配置环境变量
编辑 .bash_profile 文件:
#vi /root/.bash_profile
添加内容 :
export HADOOP_HOME=/opt/hadoop
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
(4)添加完成后,输入命令 #source /root/.bash_profile 使环境变量生效。
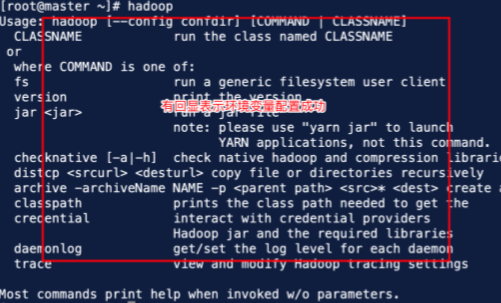
7.配置其文件
(1)配置core-site.xml 文件
#vi /opt/hadoop/etc/hadoop/core-site.xml
配置其内容:
在<configuration>补充区域</configuration>中间补充
补充内容,如下
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/hadoopdata</value>
</property>
(2)配置文件系统hdfs-site.xml
# vi /opt/hadoop/etc/hadoop/hdfs-site.xml
配置内容如下 :
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
(3)配置资源管理器yarn-site.xml
#vi /opt/hadoop/etc/hadoop/yarn-site.xml
补充内容:
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:18088</value>
</property>
(4)配置添加计算框架mapred-site.xml
复制文件
#cp /opt/hadoop/etc/hadoop/mapred-site.xml.template /opt/hadoop/etc/hadoop/mapredsite.xml
编辑文件
#vi /opt/hadoop/etc/hadoop/mapred-site.xml
配置内容
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
(5)创建数据文件
创建文件
#mkdir /opt/hadoop/hadoopdata
格式化文件系统
#hadoop namenode -format
8.设置SSH网络
(1)ssh-keygen免密登陆设置,输入命令键回车三次
生成免登入密匙 #ssh-keygen -t rsa

(2)为 master 发送免登入密匙 #ssh-copy-id -i ~/.ssh/id_rsa root@192.168.56.110
注意:输入 yes 回车 yes
输入密码 ,密码为xshell密码。

(3)ssh 连接 master
#ssh master
(4)直接输入 JavaJDK 物理路径
配置文件
# vi /opt/hadoop/etc/hadoop/hadoop-env.sh
内容为 JAVA 路径 :
export JAVA_HOME=/usr/local/java
9.启动Hadoop
(1)开启命令 #start-all.sh
停止命令 #stop-all.sh
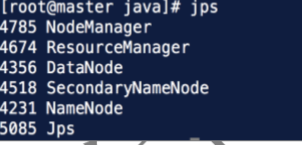
(2)验证配置是否成功
查看 Hadoop 进程
# jps
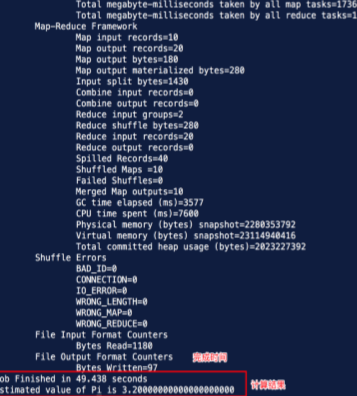
(3)计算PI,看Hadoop是否运行的起
Hadoop 运行 jar 包命令
# hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.j ar pi 10 10
10.多节点配置Hadoop
(1) 编辑文件
#vi /opt/hadoop/etc/hadoop/slaves
内容 :
slave1
slave2
(2)配置hosts主机文件
#vi /etc/hosts
添加内容
192.168.56.111 slave1
192.168.56.112 slave2
(3)虚拟机克隆IP地址

(4)修改克隆主机名
#slave1
NETWORKING=yes
HOSTNAME=slave1
#slave2
NETWORKING=yes
HOSTNAME=slave2
配置文件
#/etc/sysconfig/hostname
修改文件 slave1
修改文件 slave2
(5)配置三台机子免密登陆
ssh-copy-id -i ~/.ssh/id_rsa root@master
ssh-copy-id -i ~/.ssh/id_rsa root@slave1
ssh-copy-id -i ~/.ssh/id_rsa root@slave2
---恢复内容结束---